 Оценка 481
[+1/-0]
Оценка 481
[+1/-0]

 Оценить
Оценить 





| Оценка 481
[+1/-0]
Оценить
|
Современные операционные системы (OC) нацелены на наиболее эффективное использование ресурсов компьютера. По большей части эффективность достигается за счет разделения ресурсов компьютера между несколькими процессами (многозадачность). Такое крупномасштабное разделение ресурсов обеспечивается операционными системами без каких-либо действий со стороны приложений или процессов. Процессы могут выполняться одновременно за счет переключения центрального процессора (или нескольких процессоров) между ними. Последние версии OC предоставляют механизмы, позволяющие приложениям управлять ресурсами компьютера и распределять их с большей степенью детализации, т.е. на уровне потоков. По аналогии с многозадачными операционными системами, которые могут одновременно выполнять несколько задач путем запуска нескольких процессов, процесс может в свою очередь выполнять несколько задач за счет использования нескольких потоков. В данном документе обсуждаются способы применения потоков для повышения производительности приложений. Также здесь представлена методика распараллеливания последовательных приложений.
Целью распараллеливания, как и большинства методов программирования, является оптимальное использование системных ресурсов. Параллельная обработка повышает сложность проектирования, тестирования и сопровождения программ, обеспечивая при этом повышение пропускной способности приложений на одно- и многопроцессорных компьютерах. Многопоточность представляет собой значительный шаг вперед по сравнению с временами, когда параллельная обработка осуществлялась за счет взаимодействия процессов. За счет распараллеливания сложность организации может быть несколько снижена, особенно в отношении взаимодействия процессов. В то же время, распараллеливание приложения может привнести в программу ошибки, которые трудно обнаружить и воспроизвести.
Инструментальный пакет Intel Threading Tools предназначен для разработчиков любого уровня, от новичков до экспертов, и содержит инструменты, ориентированные на различные этапы цикла разработки. Прежде чем перейти к рассмотрению предлагаемой методики, вниманию читателя предлагаются разделы, посвященные теории параллельных вычислений, принципам распараллеливания и эффективным практическим решениям распараллеливания приложений. Целью многозадачности является максимальное использование ресурсов за счет непрерывной загрузки центрального процессора (ЦП) выполнением того или иного процесса. Каждому процессу выделен определенный временной интервал, в течение которого осуществляется его выполнение. Создание процесса включает в себя выделение некоторого адресного пространства, образа приложения в памяти, содержащего область кода, область данных и стек. Параллельное программирование с использованием процессов требует создания двух или более процессов и механизма взаимодействия, обеспечивающего координацию их параллельной работы при одновременном (конкурентном) исполнении.
Потоки – это независимые друг от друга задачи, выполняемые в контексте процесса. Поток использует код и данные родительского процесса, но имеет свой собственный уникальный стек и состояние процессора, включающее указатель команд. Потоки действуют аналогично процессам и, так же, как процессы, коллективно используют ресурсы ЦП. Каждый поток – это отдельный канал управления, обеспечивающий независимое исполнение своих команд, что позволяет многопоточному процессу одновременно решать различные задачи. Многопоточность обладает следующими преимуществами:
Инструменты, включенные в состав пакета Intel Threading Tools, позволяют быстро разделить последовательное приложение на потоки, облегчают поиск ошибок и обеспечивают повышение производительности выполнения приложений на процессорах Intel.
VTune Performance Environment – это рабочая среда, в состав которой входит анализатор производительности VTune Performance Analyzer. Анализатор VTune позволяет оптимизировать приложение для повышения производительности при выполнении на аппаратных средствах Intel. Основные особенности анализатора VTune:
Более подробная информация приведена на web-узле http://developer.intel.com/software/products/vtune/ .
Компиляторы Intel обеспечивают максимальную скорость выполнения программ на 32-разрядных процессорах Intel, включая новый процессор серии Intel Pentium M, построенный на основе мобильной технологии Intel Centrino, а также 64-разрядные процессоры Intel Itanium и Itanium 2. Компиляторы поддерживают Streaming SIMD Extensions 2 (SSE2) для процессора Intel Pentium 4 и конвейерное выполнение программ для процессоров Intel Itanium и Itanium 2. Межпроцедурная оптимизация (IPO) и оптимизация на основе профиля приложения (PGO) обеспечивают дальнейшее повышение производительности приложения. Компиляторы Intel поддерживают разработку и оптимизацию многопоточного кода с помощью функции автоматического распараллеливания и поддержки OpenMP 2.0.
OpenMP – это промышленный стандарт разработки переносимых многопоточных приложений, обеспечивающий эффективность распараллеливания как с высокой (на уровне циклов), так и с низкой (на уровне функций) степенью детализации. Компиляторы Intel поддерживают OpenMP версии 2.0 и поддерживают преобразование кода для обеспечения параллельного выполнения ПО, использующего разделяемую память.
Компилятор Intel C++ 7.1 включает функцию автоматического распараллеливания циклов. Эта функция производит поиск циклов, которые можно безопасно выполнять параллельно, и автоматически генерирует для них многопоточный код. Автоматическое распараллеливание освобождает разработчика от необходимости вникать в детали разбиения циклов, совместного использования данных, планирования потоков и синхронизации.
Подробнее см. http://developer.intel.com/software/products/compilers/.
Анализатор потоков Intel Thread Checker представляет собой подключаемый модуль для среды VTune Performance Environment. Он позволяет обнаруживать следующие ошибки и потенциальные проблемы в распараллеленном приложении:
Анализатор потоков отслеживает ошибки с точностью до строки исходного кода. Сведения, предоставляемые для каждой ошибки, зависят от типа средств измерения, встроенных в данное приложение. Анализатор потоков собирает данные с помощью средств измерения, встроенных в исходный код или в двоичный файл, или используя комбинацию обоих методов. Средства измерения, встраиваемые в исходный код, устанавливаются путем внесения изменений в исходный код до (или во время) компиляции программы. Средства измерения, встраиваемые в двоичные файлы, устанавливаются путем внесения функций сбора данных непосредственно в исполняемые файлы без знания исходного кода.
Подробнее см. http://developer.intel.com/software/products/threading/
Профилировщик потоков представляет собой подключаемый модуль для анализатора VTune; он позволяет обнаруживать узкие места в производительности приложений, распараллеленных с помощью OpenMP и Win32 API.
Флаг компилятора /Qopenmp_profile при сборке приложения сообщает компилятору о необходимости подключить версию библиотеки, оснащенную средствами измерения. Приложения, собранные с подключением библиотек, оснащенных средствами измерения, могут запускаться для создания файла статистических данных времени выполнения за пределами среды VTune Environment. Впоследствии этот файл можно проанализировать с помощью профилировщика потоков в анализаторе VTune. Если приложение собрано без библиотек со средствами измерения, то при его запуске в среде VTune анализатор VTune заменяет динамические runtime-библиотеки OpenMP их версиями, оснащенными средствами измерения. При этом приложение должно быть собрано с учетом использования динамической версии runtime-библиотеки времени выполнения OpenMP – это делается путем указания параметров /MD /Qopenmp во время компиляции.
Профилировщик потока представляет статистические данные времени выполнения различными способами, что позволяет разработчику анализировать производительность приложения раздельно по потокам и по фрагментам OpenMP. Профиль разделен на части по времени, затраченному на выполнение последовательных и параллельных фрагментов, критических секций и на различные служебные операции по обеспечению синхронизации. Эта информация позволяет определить, как влияет на производительность многопоточного приложения излишний объем служебных операций, операций синхронизации, а также дисбаланс потоков.
Профилировщик потоков Win32 предлагает средства для построения профилей программ, явно распараллеленных с помощью функций интерфейса программирования многопоточных приложений Microsoft Win32, что позволяет выявлять узкие места, ограничивающие производительность параллельных приложений. Это достигается путем внедрения измерительных средств в двоичный файл приложения. Собранные данные используются для выявления проблем производительности многопоточных программ:
Профилировщик потока позволяет:
Библиотека элементарных функций Intel Integrated Performance Primitives – это межплатформенная библиотека с набором мультимедийных функций для улучшения характеристик аудио- и видеокодировщиков/декодировщиков, а также модулей обработки сигналов и изображений.
Библиотека Intel Math Kernel Library (Intel MKL) включает оптимизированные математические функции для инженерных, научно-технических и финансовых приложений. Функциональные возможности библиотеки охватывают функции линейной алгебры, включая LAPACK и BLAS, быстрое преобразование Фурье (БПФ) и векторные трансцендентные функции (библиотеку функций векторных вычислений/VML). Библиотека Intel MKL совместима с ОС Windows и Linux.
Более подробная информация приведена на web-сайте http://developer.intel.com/software/products/perflib/.
Как правило, этап анализа включает получение профиля последовательного приложения с целью определения фрагментов, распараллеливание которых принесет наибольшую выгоду. При этом с помощью анализатора производительности VTune посредством анализа диаграммы вызовов функций производится обнаружение критических путей, а выборка по времени (TBS) позволяет выявить на критических путях "горячие" (критические) точки. После определения кандидатов на распараллеливание следует выбрать подходящую модель распараллеливания. Выбор осуществляется, прежде всего, путем определения требуемого типа параллелизма (по данным или по функциям).
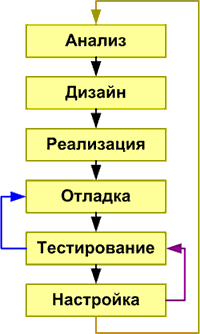
Рисунок 1. Блок-схема основных этапов типовой методики распараллеливания.
На этапе проектирования исследуются критические фрагменты программы, выявленные на этапе анализа, с целью определения изменений, требуемых для применения алгоритма распараллеливания:
На этапе реализации запланированные изменения переносятся в код. Помимо использования анализатора потоков Intel Thread Checker в качестве инструмента для отладки и тестирования, его также можно эффективно использовать для проектирования и разработки параллельных приложений.
При создании программы можно использовать следующие методики распараллеливания:
На этапе отладки производится устранение ошибок, проверяется правильность работы приложения и его соответствие предъявляемым требованиям. Для выявления сбоев и интерактивной отладки критических фрагментов следует использовать динамический анализ приложения.
Для обнаружения недетерминированных ошибок, таких как конкурентные ситуации при доступе к данных, взаимные блокировки и зависание потоков, на этом этапе следует использовать анализатор потоков Intel Thread Checker.
Рабочие характеристики и правильность работы распараллеленного приложения проверяются на этапе тестирования следующим образом:
Внесение изменений в приложение может потребовать повторного прохождения этапов отладки и тестирования, поскольку эти изменения могут повлечь за собой возникновение ошибок распараллеливания. Для исключения всех неполадок может потребоваться работа в цикле: отладка – тестирование – настройка.
Для эффективного распараллеливания приложения необходимо выбрать наиболее подходящий метод распараллеливания. Различия между методами распараллеливания не оказывают заметного влияния на производительность приложения, однако неправильный выбор метода приводит к увеличению затрат времени на внесение изменений, отладку и настройку распараллеленного приложения.
Для выбора оптимального метода распараллеливания следует описать приложение с точки зрения двух моделей: модели параллельного выполнения задач и модели параллельного использования данных.
В приложениях с параллельным выполнением задач независимые операции, заключенные в функции, переносятся в выполняемые асинхронно потоки, как показано на Рис. 2. Для выражения параллелизма на уровне задач предназначены библиотеки поддержки многопоточности, например, интерфейсы программирования многопоточных приложений Win32 и POSIX*

Рисунок 2. Администратор личных данных является хорошим примером приложения, реализующего параллелизм на уровне задач. Для выражения параллелизма на уровне задач независимые функции переносятся в потоки, как показано на примере фрагмента псевдокода.
Под параллелизмом на уровне данных подразумевается многократное применение одних и тех же команд или операций к различным данным. Эта модель показана на Рис. 3. Хорошими кандидатами на применение методов параллельного использования данных являются циклы, в которых выполняются интенсивные вычисления.
Общим примером реализации параллелизма на уровне данных может служить типичный алгоритм обработки изображений, который применяет фильтр к одной или нескольким точкам изображения для вычисления нового значения для заданной точки. Поскольку операции, выполняемые над точками изображения, являются независимыми, вычисления новых значений для точек могут выполняться параллельно.
Иногда параллелизм на уровне данных может выражаться компилятором автоматически. Можно также описать параллелизм с помощью синтаксиса директив, определенного стандартом OpenMP*. Функции преобразования директив в параллельный код выполняет компилятор.
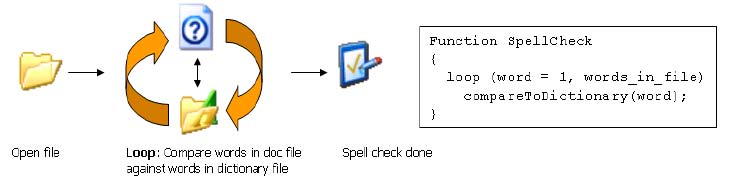
Рисунок 3. Хорошим примером параллельной работы с данными является программа проверки орфографии. Как видно из фрагмента псевдокода, в этом случае производится многократное выполнение одинаковых независимых операций сравнения слов из файла со словарем.
Отметим, что в различных частях одного и того же приложения могут применяться разные модели. В качестве примера приложения, использующего обе модели параллелизма, можно привести работу с базой данных. Задача добавления записей в базу данных может быть назначена одному потоку, сортировка данных – другому, индексирование – третьему, а отдельная группа потоков может осуществлять выполнение запросов. При выполнении запроса к различным данным применяются одинаковые операции, что делает такой запрос задачей параллельного использования данных.
При разработке стандарта OpenMP и библиотек поддержки многопоточности преследовались различные цели. Методы параллельной работы с данными OpenMP предназначены для повышения производительности за счет многозадачности.
Явные методы распараллеливания, также повышающие производительность параллельных приложений, были разработаны для выражения естественного параллелизма, заложенного в большинстве приложений.
В действительности целевой платформой многих параллельных приложений является компьютер с одним процессором. Применение многопоточности обусловлено двумя основными требованиями: увеличением параллелизма и повышением производительности ПО. Рассмотрим суть этих требований на примере текстовых редакторов, которые обычно рассматриваются как приложения с высокими требованиями к производительности. При выводе большого документа на принтер пользователи предпочитают продолжать свою работу. Большинство пользователей сочтут недопустимой невозможность работы с приложением при выполнении длительных задач вывода на печать. В случае многопоточного приложения ОС может обеспечить переключение между ними, скрывая таким образом периоды ожидания. При этом пользователь воспринимает лучшую реакцию приложения как более высокую производительность.
Для автоматического распараллеливания циклов используйте при запуске компиляторов Intel параметр -Qparallel. При наличии параметра -Qparallel компилятор пытается выделить циклы, которые могут безопасно выполняться параллельно. Применение следующих рекомендаций повысит вероятность успешной идентификации параллельных циклов компилятором:
Явное представление числа итераций цикла не означает, что число итераций должно быть зафиксировано во время компиляции. Компилятор лишь должен иметь возможность определить, изменяется ли число итераций при выполнении цикла. Цикл не может быть безопасно вынесен в параллельный поток, если число итераций изменяется в зависимости от определенных условий в теле цикла. Ветвление в теле цикла дает аналогичный эффект. Невыполнение этих рекомендаций не означает, что цикл не может выполняться параллельно. Например, вызов "чистой" функции, такой, как процедура без побочных эффектов, не нарушит параллелизма.
Если компилятор не может гарантировать корректность параллельного исполнения программы, будет выдано соответствующее предупреждение. Полный отчет об успешно распараллеленных циклах и о том, какие зависимости помешали распараллелить другие циклы, можно получить с помощью параметра -Qpar_report3.
Более подробная информация приведена в документации по компилятору.
Большинство современных компиляторов с функцией автоматического распараллеливания оставляют нераспараллеленными сотни или даже тысячи строк исходного кода, содержащихся в программе из нескольких исходных файлов. Но знание разработчиком основного алгоритма позволяет делать выводы о том, что нераспараллеленный автоматически код не содержит зависимостей и может безопасно выполняться параллельно. Для решения этой проблемы был разработан специальный синтаксис на основе директив, получивший название OpenMP, который позволяет описывать параллелизм для компилятора.
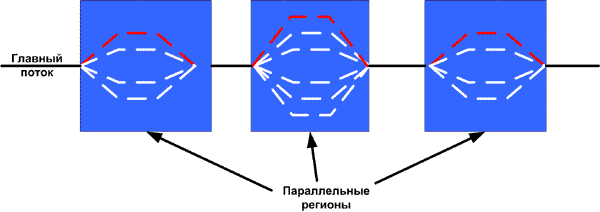
Рисунок 4. OpenMP* использует метод разветвления и слияния: каждый параллельный фрагмент имеет явно определенные начало и конец.
Вскоре после своего появления в 1997 году спецификация OpenMP стала промышленным стандартом описания параллелизма для компиляторов. До появления OpenMP для этой цели использовалось несколько конкурирующих, но сходных между собой наборов директив. Спецификация OpenMP объединила эти синтаксисы и расширила их возможности в отношении работы с большими приложениями.
OpenMP определяет набор директив для языка Fortran и набор псевдокомментариев препроцессора для C/C++. OpenMP реализует метод разветвления/слияния для создания и завершения потоков, что проиллюстрировано на Рис. 4. При этом необходимо явно указывать начало и конец каждого параллельного фрагмента.
Чтобы получить многопоточный исполняемый файл, следует использовать компиляторы Intel с параметром -Qopenmp, указывающим на необходимость обработки директив или псевдокомментариев OpenMP. В противном случае директивы OpenMP игнорируются. Это является ключевым преимуществом OpenMP над другими методами параллельного программирования. Этот метод является пошаговым и относительно безопасным. С помощью OpenMP можно распараллелить определенные циклы и фрагменты программы без крупномасштабных изменений кода. Первоначальный последовательный код остается по большей части нетронутым.
Рассмотрим два примера программ, предназначенных для расчета числа "пи" путем численного интегрирования:
#include <stdio.h> #define INTERVALS 100000 int main() { int i; float n_1, x, pi = 0.0 n_1 = 1.0 / INTERVALS; #pragma omp parallel for private(x) reduction(+:pi) for (i = 0; i < INTERVALS; i++) { x = n_1 * (float(i) - 0.5); pi += 4.0 / (1.0 +x * x); } pi *= n_1; printf ("Pi = %f\n", pi); } |
#include <stdio.h> #include <pthreads.h> #define INTERVALS 100000 #define THREADS 4 float global_sum = 0.0; pthread_mutex_t global_lock = PTHREAD_MUTEX_INITIALIZER; void *pi_calc(void *num); int main () { pthread_t tid[THREADS]; int i; int t_num[THREADS]; for (i = 0; i < THREADS; { t_num[i] = i; pthread_create(&tid[i] NULL, pi_calc, &t_num[i]); } for (i = 0; i < THREADS; i++) pthread_join (tid[i], NULL); printf ("Sum = %f\n", global_sum); } void *pi_calc(void *num) { float my_sum = 0.0; int myid = *(int*)num; float h = 1.0 / INTERVALS; int start = (INTERVALS / THREADS) * myid; int end = start + (INTERVALS / THREADS); float x; int i; for (i = start; i < end; i++) { x = h * ((float)i - 0.5); my_sum += f(x); } pthread_mutex_lock(&global_lock); i++) global_sum += my_sum; pthread_mutex_unlock(&global_lock); } |
Основные отличия между традиционными библиотеками поддержки многопоточности и OpenMP можно подытожить следующим образом:
Закон Амдаля является теоретической основой для определения производительности при параллельном использовании данных (см. рис. 5).

Рисунок 5. Закон Амдаля: распределение общего времени, затрачиваемого на выполнение процесса с помощью N процессоров. Время P затрачивается на параллельное выполнение, но при этом возникают дополнительные затраты времени на служебные операции.
Поскольку требуется найти теоретическое ограничение возможности масштабирования, допустим, что используется бесконечное число процессоров и отсутствуют затраты времени на выполнение служебных операций. В этом случае закон Амдаля сводится к простому соотношению:
Scalability = T Total / T Parallel
Если преимущества параллелизма можно реализовать только для половины процесса, максимально возможный показатель масштабирование составляет 2 – при условии бесконечного числа процессоров и абсолютной эффективности. При использовании только двух процессоров максимально возможное ускорение составит 1,33 при условии абсолютной эффективности.
Если T - это время, требуемое для последовательного выполнения приложения, то при наличии только двух процессоров минимальное требуемое время составит T/2 (для выполнения не распараллеленной половины кода) плюс (T/2)/2 на выполнение распараллеленной половины на двух процессорах, что в сумме составляет 3*T/4. Частное от деления T на (3*T/4) определяет ускорение, равное 4/3 или 1,33.
Используйте закон Амдаля для оценки потенциальной выгоды от параллельной обработки. Например, создание нескольких потоков для обработки изображения должно значительно повысить производительность для многопроцессорных систем. Однако операции ввода/вывода файлов по своей сути являются последовательными. Если для выполнения операций загрузки и сохранения файла требуется больше времени, чем для применения фильтра изображения, создание нескольких потоков для ускорения работы фильтра может оказаться нецелесообразным. Однако в этом случае эффективным может оказаться решение, при котором фильтрация будет выполняться в потоке, отдельном от потока ввода/вывода. Таким образом, в данном примере разделение по данным может не иметь смысла, в то время как функциональное разделение может помочь.
Концепция детализации предлагает другую возможность оценки целесообразности применения параллельной обработки. С помощью закона Амдаля по соотношению времени выполнения параллельных и последовательных операций можно определить, имеет ли смысл внедрять многопоточность. С помощью концепции детализации можно решить, достаточная ли нагрузка приходится на одну независимую задачу (размер которой определяет степень детализации), чтобы оправдать внедрение многопоточности. В отличие от закона Амдаля, представленного объективным уравнением, оценка детализации более субъективна.
Рассмотрим для примера итерационный метод решения дифференциальных уравнений. Каждая итерация зависит от результата предыдущей итерации. Поэтому итерации выполняются строго последовательно, но для операций, выполняемых в пределах одной итерации, возможно внедрение параллелизма. Допустим, что в каждой итерации все вычисления выполняются в одной функции.
Плоский характер профиля таких программ может вводить в заблуждение. Он показывает, что наибольшее время затрачивается именно в этой функции. Напрашивается естественный вывод, что эта функция является хорошим кандидатом на распараллеливание. Однако при этом важно определить примерное время, затрачиваемое на выполнение одной итерации. Возможно, что это время окажется меньше, чем дополнительные затраты на выполнение служебных операций, требуемых для создания и обслуживания потоков, в этом случае производительность с увеличением числа потоков будет уменьшаться. В данном примере степень детализации слишком мала для эффективного использования потоков.
Для принятия решения о том, стоит ли применять распараллеливание к функции или к вызывающей ее программе, используйте модуль графического представления вызовов функций анализатора производительности VTune Performance Analyzer.
Для упрощения применения закона Амдаля затраты на служебные операции по обеспечению параллельной работы игнорируются. Это допущение, конечно, является нереалистичным. Создание потока в ОС Windows отнимает примерно столько же, сколько 1000 операций деления целых чисел. Кроме того, ОС должна обслуживать потоки и планировать их выполнение. Контроль состояния потока требует определенных системных ресурсов. Планирование потоков часто требует переключения контекстов. Выполняемые системой служебные операции ограничивают возможность масштабирования, однако оптимальный алгоритм может свести это воздействие к минимуму.
С помощью OpenMP легко управлять числом потоков для каждого параллельного фрагмента, но ситуация, когда число готовых потоков больше, чем число процессоров, редко приводит к положительным результатам. Это просто увеличивает затраты на служебные операции, не давая выигрыша в производительности.
Применение библиотек поддержки многопоточности более распространено, чем использование модели разветвления/слияния OpenMP. Любой поток может создавать новые потоки и уничтожать другие потоки. Потоки могут появляться и исчезать во время работы программы. Метод реализации потоков по мере возникновения потребности в них является более ясным и понятным, напоминая процедуру динамического распределения памяти. Ресурсы операционной системы запрашиваются по мере необходимости. Зачастую это является наиболее простым способом создания многопоточного приложения, обеспечивающим удовлетворительную производительность. Однако и в этом случае возможны большие затраты на служебные операции, ограничивающие возможность масштабирования.
Используя пример работы с БД, достаточно просто перенести любую транзакцию, например, добавление/удаление записей, выполнение запросов и других операций, в отдельный поток и поручить его планирование операционной системе.
Если число транзакций невелико, такой прием может обеспечить достаточную эффективность. Однако большой объем транзакций способен "затопить" систему слишком большим количеством потоков.
При значительном объеме транзакций число связей увеличивается. Вместо создания отдельного потока для каждой новой транзакции, в самом начале программы можно создать группу потоков для обработки транзакций на протяжении всего времени работы программы. После этого каждая связь обрабатывается потоком, уже созданным в группе потоков.
| СОВЕТ Применяйте потоки многократного использования или группы потоков для сокращения затрат на служебные операции создания и удаления потоков и исключения их отрицательного влияния на эффективность масштабирования приложения. |
В многопоточных программах практически всегда необходимо обеспечение синхронизации для предотвращения конкурентных ситуаций, когда несколько потоков пытаются одновременно изменить одну и ту же глобальную переменную. Необходимость синхронизации ограничивает эффективность параллельных программ даже в большей степени, чем затраты на служебные операции, поскольку требует перевода части программы в последовательную форму. Наиболее часто игнорируется требующая синхронизации операция динамического распределения памяти, которая требует блокировки динамической области памяти во избежание повреждения ее содержимого.
Есть несколько способов предотвратить конфликт при блокировке динамической памяти. Можно выделять память для потока не в динамической области, а в стеке потока с помощью функции alloca или программ сторонних производителей, например, SmartHeap компании MicroQuill.
OpenMP и библиотеки поддержки многопоточности содержат специальные механизмы для создания областей памяти, выделенных под нужды потоков. Потоки могут осуществлять доступ к этим областям без синхронизации.
Для выделения потокам отдельной локальной памяти в различных моделях распараллеливания используйте следующие выражения:
В отсутствие явной синхронизации операционная система планирует выполнение потоков по своему усмотрению. Это приемлемо для изначально параллельных приложений, в которых потоки не взаимодействуют друг с другом и не используют одни и те же данные. Однако такая ситуация скорее является исключением, чем правилом.
static int counter = 0; void update_counter() { counter++; } |
Для большинства параллельных программ во избежание конкурентных ситуаций требуется обеспечить некоторую степень синхронизации. Пример 3 иллюстрирует простую функцию, небезопасную в отношении распараллеливания.
Если доступ к статической переменной-счетчику не синхронизирован, возможна потеря данных, что проиллюстрировано в последовательности, представленной в Табл. 1.
| Time (Время) | Thread 0 (Поток 0) | Thread 1 (Поток 1) |
|---|---|---|
| T0 | Enter function | |
| T1 | Enter function | |
| T2 | Load (counter = 0) | |
| T3 | Load (counter = 0) | |
| T4 | Increment (counter = 1) | |
| T5 | Store (counter = 1) | |
| T6 | Increment (counter = 1) | |
| T7 | Store (counter = 1) | |
| T8 | Return | |
| T9 | Return |
Для предотвращения конфликтных ситуаций все методы распараллеливания имеют специальные конструкции, обеспечивающие синхронизацию. Наилучшим способом исправить ошибку в предыдущем примере является использование функций InterlockedXxx, включенных в состав интерфейса программирования приложений Win32, или элементарного псевдокомментария (pragma, указание транслятору) OpenMP. Безопасные в отношении распараллеливания версии простой функции показаны в примере 4.
static int counter = 0; static int counter = 0; void updateCounter() void updateCounter() { { InterlockedIncrement(&counter); #pragma omp atomic } counter++; } |
Win32-функции InterlockedIncrement, InterlockedDecrement, InterlockedExchange, InterlockedExchangeAdd, InterlockedCompareExchange выполняют элементарные действия над переменными без блокировки потоков. То же относится и к элементарному псевдокомментарию OpenMP. Простые элементарные операции изменения переменных выполняются намного быстрее операций с механизмом синхронизации. Однако они применимы не во всех случаях.
В случае более сложных операций оптимальными для осуществления синхронизации с точки зрения эффективности представляются критические секции. В любой момент времени только один поток может выполнять критическую секцию программы.
Функции, показанные в примере 5, содержат зависимости между данными, которые требуют синхронизации:
static int a, d; static int a, d; CRITICAL_SECTION cs; void DataDependence(int b, int c, int e) void DataDependence(int b, int c, int e) { { #pragma omp critical EnterCriticalSection(&cs); { a = b + c; a = b + c; d = a + e; d = a + e; LeaveCriticalSection(&cs); } } } |
Критическая секция защищает переменные a и d. При отсутствии критической секции несколько потоков могут изменить значение переменной a, где a = b + c, в то время как другие потоки выполняют его считывание (d = a + e), кроме того, несколько потоков могут одновременно изменить переменную d.
Win32 также предоставляет функции, определяющие критические фрагменты, но на этом их сходство с критическими секциями заканчивается:
static int a, d; #include <omp.h> Handle mtx; static int a, d; omp_lock_t lck; void DataDependence(int b, int c, int e) void DataDependence (int b, int c, int e) { { WaitForSingleObject(&mtx); omp_set_lock(&lck); a = b + c; a = b + c; d = a + e; d = a + e; ReleaseMutex(&mtx); omp_unset_lock(&lck); } } |
В отличие от критических секций Win32, являющихся локальными объектами, мьютексы являются объектами ядра. Служебные операции, обеспечивающие захват и освобождение мьютекса, отнимают примерно в 10 раз больше ресурсов, чем при использовании критической секции. Однако функции взаимного исключения Win32 имеют определенные преимущества по сравнению с критическими секциями.
Объекты ядра совместно используются несколькими процессами, поэтому мьютексы могут синхронизировать доступ к памяти, используемой несколькими процессами. Кроме того, мьютексы снабжены механизмами защиты для предотвращения взаимоблокировок (deadlock). Если поток будет завершен в момент удержания им критической секции Win32, другие потоки, пытающиеся войти в эту критическую секцию, будут заблокированы. Такая критическая секция называется зависшей. Потоки, пытающиеся обратиться к брошенному объекту взаимного исключения, возвращают соответствующий код ошибки (WAIT_ABANDONED_0).
Переменные мьютексов могут также использоваться в функциях Win32 WaitForSingleObject и WaitForMultipleObjects, которые допускают использование синхронизирующих задержек.
OpenMP включает функции блокировки, но в реализации Intel они больше напоминают критические секции Win32, чем мьютексы. Это скорее локальные объекты, нежели объекты ядра, и они не могут использоваться несколькими процессами. Попытка обращения к брошенному объекту блокировки OpenMP также приводит к зависанию потока.
Ниже представлена методика распараллеливания приложений, включающая все этапы типового цикла разработки. Цели каждого этапа цикла разработки достигаются путем применения одного или нескольких компонентов инструментального пакета Intel Threading Tools. При рассмотрении методики исследуются различные сценарии применения, что позволяет ускорить разработку.
Все операции реструктуризации данных и исходного кода, производимые с подлежащими распараллеливанию последовательными приложениями, могут быть выполнены на этапе проектирования. Это приводит к уменьшению общих усилий, затрачиваемых на разработку, и исключает необходимость последующих переделок.
Большинство многопоточных приложений исходно проектируются как последовательные, которые затем подвергаются распараллеливанию. При таком подходе правильному проектированию потоков не уделяется достаточно внимания, и основные усилия тратятся на реструктурирование и перестройку последовательного приложения.
Рассмотрим проект параллельного приложения для редактирования видеозаписей. Исходная схема построения приложения имеет целью обеспечение высокой вычислительной мощности; дальнейшие улучшения реализуются за счет раскрытия функционального параллелизма, заложенного в приложении.
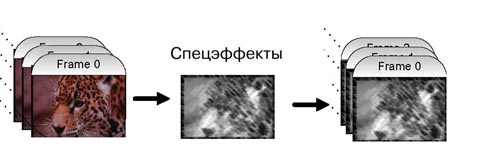
Рисунок 6. Пример редактирования видеоизображений в реальном времени
На Рис. 6 показана передача несжатых видеоданных в приложение. К видеопотоку применяются спецэффекты. Затем обработанный видеопоток сохраняется на диске. Если спецэффекты необходимо применять к видеопотоку в реальном времени, производительность играет весьма существенную роль. Время на обработку каждого кадра ограничено, то есть обработка каждого кадра должна быть завершена до поступления следующего кадра. Рассмотрим автономную модель обработки. Если данное приложение имеет последовательную структуру, последовательность действий может быть аналогична представленной в Примере 7.
char *frameReadBuffer; ..... ..... while (ReadFrame(frameReadBuffer)) { // // Updates the read buffer with the processed data // ProcessFrame(frameReadBuffer); // // Write the modified frame to disk // WriteFrame(frameReadBuffer); } |
При распараллеливании этой задачи существенную роль для получения успешной многопоточной версии играет несколько моментов. Если спецэффекты, применяемые к каждому элементу изображения, достаточно сложны, выполнение функции ProcessFrame() требует значительных вычислительных ресурсов. Применение VTune для оценки характеристик этого приложения покажет, что функция ProcessFrame() заметно выделяется как критическая и при анализе по выборке, и на схеме вызываемых функций. В зависимости от размера кадра обработку можно разделить на несколько частей и выполнять параллельно, что превращает эту проблему в задачу декомпозиции данных.
При проектировании многопоточных приложений внимание в первую очередь уделяется той части кода, выполнение которой занимает наибольшее время. В примере с обработкой видеосигнала предположим, что задачей, занимающей наибольшее время, является применение спецэффекта, затем следуют операции ввода/вывода при считывании и записи кадра. Многопоточная версия, предназначенная для работы на системе с четырьмя процессорами, показана на рисунке 7.
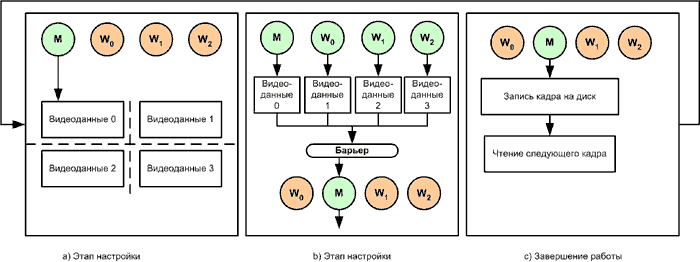
Рисунок 7. Многопоточная версия, реализующая параллелизм данных.
В функции ProcessFrame(), показанной в примере 8, основной поток действует в качестве канала управления и обеспечивает разделение текущего кадра на четыре части на этапе настройки, показанном на рисунке 7 (a). После завершения этапа настройки управляющий поток вызывает три рабочих потока, и все эти четыре потока, включая управляющий, выполняют действия над отдельной частью кадра. После завершения обработки своей части данных потоки ждут у барьера завершения работы остальных потоков. После этого управляющий поток приостанавливает все рабочие потоки, записывает обработанный кадр на диск, а затем считывает следующий кадр видеопотока.
Псевдокод для многопоточной версии функции ProcessFrame() показан в примере 8. Выход управляющего потока из функции ProcessFrame() означает успешное завершение обработки кадра, после чего кадр записывается на диск. Вызывающая функция по-прежнему остается такой, как показано в примере 8.
struct { int startx, endx; int starty, endy; char *data; } ThreadData; ProcessFrame(char *data) { ThreadData perThreadData[nThreads]; // // The master sets the limits for // the region each thread has to process // DecomposeData(data, perThreadData, nThreads); // // Wakes the worker threads with information about their data // Each worker thread will also execute ProcessSection() // for(int i = 1; i < nThreads; ++i) WakeWorkerThread(i, perThreadData[i]); // // Master does its share of the work // ProcessSection(perThreadData[0]); // // Master waits for all the threads to complete processing. Each worker // thread goes to sleep after calling ProcessSection() // WaitForAllThreads(); } |
Предполагая, что серьезные проблемы с производительностью отсутствуют, можно оценить производительность многопоточной версии. Предположим, что обработка спецэффекта занимает 80% времени, а операции ввода/вывода – оставшиеся 20%, где половина затрачивается на считывание кадра, а вторая половина – на запись обработанного кадра. При условии максимального ускорения многопоточной части цикла обработки ожидаемый коэффициент ускорения приложений такого типа согласно закону Амдаля ни при каких условиях не может превысить пяти при бесконечном числе процессоров.
При использовании четырех потоков коэффициент ускорения не может превысить 2,5, поскольку последовательная часть, полностью отведенная на решение задач ввода/вывода, по-прежнему занимает 20% времени, а выполнение параллельной части – 80% / 4, то есть также 20%, как показано на рисунке 8. Это значение представляет собой верхний предел эффективности масштабирования при использовании четырех потоков. В реальных условиях за счет затрат системных ресурсов, возникающих при распараллеливании приложения, фактическое ускорение должно быть менее 2,5.
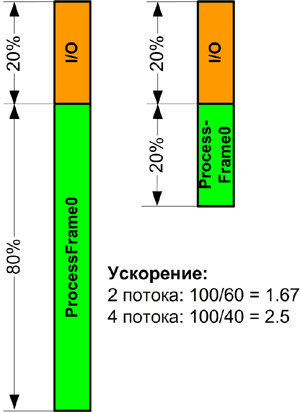
Рисунок 8. Элементы выполняются в цикле. Поток ввода/вывода должен завершить запись блока S1 перед считыванием следующего блока R1.
В этом случае для увеличения эффективности масштабирования последовательная часть приложения должна быть уменьшена.
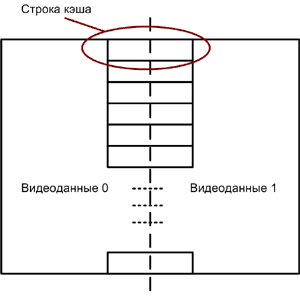
Рисунок 9. Строка кэша для потоков видеоданных.
Приложения, использующие декомпозицию данных, могут быть особенно чувствительны к проблеме непреднамеренного совместного использования ресурсов, что проиллюстрировано на рисунке 9. Ситуация непреднамеренного совместного использования возникает в случае, когда два потока обращаются к разным блокам данных, попадающих в одну строку кэша для чтения и записи при работе на многопроцессорных системах или системах, использующих гиперпоточную технологию.
Когда один из потоков производит запись в строку кэша, для обеспечения согласованности кэша эта строка блокируется. Это заставляет второй поток, читающий элементы этой же строки кэша, повторно обращаться к ней. Эта конкретная может серьезно ухудшить производительность приложения.
Рассмотрим этап настройки, показанный на рисунке 7 (a), и исследуем блоки видеоданных 0 и 1. Если последний элемент строки 1 в блоке видеоданных 0 и первый элемент первой строки блока видеоданных 1 принадлежат к одной и той же строке кэша, возникает ситуация непреднамеренного совместного использования ресурсов, выражающаяся в дополнительных потерях при обработке этих элементов изображения. Ситуацию непреднамеренного совместного использования можно исключить за счет тщательного планирования работы потоков с кэшем с учетом границ строк кэша.
Масштабирование можно улучшить, если в дополнение к потоку ввода/вывода в группу потоков добавляются буферы чтения и записи. Путем наложения операций ввода/вывода на основные операции обработки можно значительно сократить время выполнения. На рисунке 10 показана блок-схема нового решения . Теперь большая часть операций ввода/вывода выполняется параллельно вычислительным задачам. В этом решении используется функциональная декомпозиция задачи ввода/вывода. При этом для новой реализации необходимо создать три дополнительных буфера. Этот алгоритм позволяет повысить производительность предыдущей многопоточной версии.
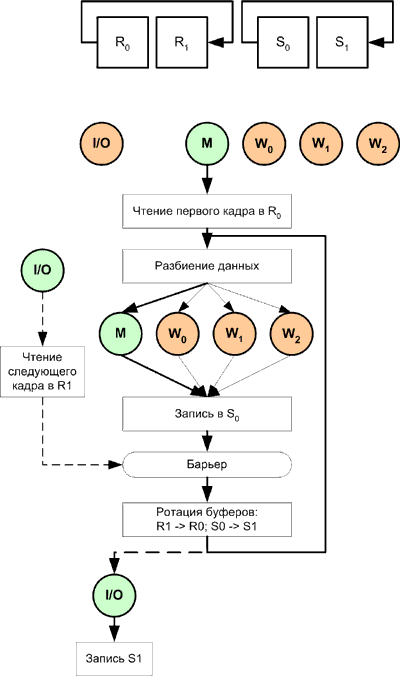
Рисунок 10. Функциональная декомпозиция и декомпозиция по данным для приложения редактирования видеозаписи.
На рисунке 10 логика управляющего потока показана жирными линиями. При запуске приложения создается группа потоков (число процессоров + 1); один из потоков предназначен для управления вводом/выводом, а другой выделен в качестве управляющего потока. Остальные потоки используются в качестве рабочих.
При запуске приложения управляющий поток считывает первый кадр в буфер R0. Он разделяет данные с учетом ситуации непреднамеренного совместного использования и вызывает поток ввода/вывода для считывания следующего кадра в буфер R1. Во время выполнения операции ввода/вывода управляющий поток вызывает все рабочие потоки и разделяет работу между ними. Рабочие потоки записывают свою часть обработанных данных в буфер записи S0. После выполнения задания все потоки ждут у барьера (включая поток ввода/вывода). По завершении обработки текущего кадра управляющий поток производит ротацию буферов путем переименования R1 в R0, а R0 в R1, а также буферов записи – S0 в S1, а S1 в S0 и приостанавливает рабочие потоки. Теперь следующий кадр, считанный потоком ввода/вывода, находится в буфере R0, а только что обработанный кадр – в буфере S1. Затем управляющий поток передает потоку ввода/вывода запрос на запись обработанного кадра, находящегося в буфере S1, на диск и начинает обработку следующего кадра в буфере R0 путем разделения его на задания. По завершении записи поток ввода/вывода приступает к считыванию следующего кадра в R1.
Представленный здесь алгоритм упрощен; для его реального использования необходимо внедрить элементы синхронизации буферов для предотвращения их ротации до завершения считывания. При использовании такого подхода время на выполнение ввода/вывода может быть уменьшено в несколько раз по отношению ко времени, необходимому для этого в предыдущей многопоточной версии благодаря асинхронному выполнению операции. Допуская, что время на выполнение ввода/вывода может быть сокращено на 5%, предполагаемая эффективность масштабирования для нового алгоритма равна 4 при использовании 4 рабочих потоков на четырехпроцессорной системе, как показано на рисунке 10.
Как и ранее, предполагается, что в области обработки спецэффекта достигнут наилучший возможный показатель масштабирования. Применив и параллелизм задач, и параллелизм данных, мы добились улучшения эффективности масштабирования примерно с 2,5 до 4 для системы с 4 процессорами.
При проектировании многопоточного приложения решающим фактором является учет всех аспектов. Разработчик, плохо знающий конкретное приложение, попытавшись распараллелить последовательную версию приложения, скорее всего, остановится на первой многопоточной версии этого приложения. Но если разработчик плохо знаком с методикой распараллеливания, некоторые проблемы производительности, рассмотренные в разделе об эффективных методиках распараллеливания, могут значительно ухудшить производительность любого многопоточного приложения. Поэтому при проектировании приложения и применении функционального параллелизма и параллелизма данных очень важно учитывать возможные ловушки.
После получения многопоточной версии приложения необходимо определить верхний предел масштабирования, чтобы выяснить, насколько удалось приблизиться к теоретически рассчитанной производительности. Приложение с автоматическим созданием потоков по количеству процессоров в системе может недостаточно хорошо масштабироваться из-за малого объема параллельной работы или других ограничивающих факторов.
Во второй версии нашего многопоточного приложения профиль приложения содержит 5% последовательных фрагментов и 20% параллельных фрагментов. Однако мы знаем, что поток ввода/вывода, выполняемый в фоновом режиме, занимает ~10% времени на чтение и еще 10% – на запись. В этом сценарии потоки разного типа (ввода/вывода и спецэффектов) на обработку своих задач тратят одно и то же время. Однако увеличение числа потоков для обработки спецэффектов окажет отрицательное влияние на общий коэффициент ускорения, поскольку на обработку спецэффектов потребуется меньше времени, чем на выполнение чтения и записи в фоновом режиме.
Благодаря наличию механизма синхронизации рабочие потоки и поток управления должны ожидать завершения операций ввода/вывода. Если для обработки всех этих потоков нужно приблизительно одно и то же время, то для исключения дополнительных затрат следует использовать объект CRITICAL_SECTION, реализующий пустой цикл с ожиданием.
Использование примитивов пустого цикла с ожиданием для обеспечения синхронизации в сценариях, где потоки становятся несбалансированными, может оказаться вредным в системах с применением гиперпоточной технологии. Пустой цикл с ожиданием использует ресурсы ЦП и не производит полезной работы, воздействуя таким образом на другие потоки, исполняемые на том же процессоре.
Целью этапа анализа является проведение базовых измерений производительности последовательного приложения и определение фрагментов приложения, подходящих для распараллеливания. Для измерения производительности последовательного приложения используйте тестовую нагрузку (или нагрузки), позволяющую проверить большинство анализируемых путей, описанных в коде. Выбранные нагрузки должны быть по возможности малы, чтобы минимизировать объем используемой памяти и время исполнения приложения. Основным инструментом, используемым на этом этапе, является анализатор производительности VTune. Этап анализа показан на рисунке 11 в виде блок-схемы.
После выбора нагрузки или нагрузок приложение запускается, а анализатор производительности VTune собирает статистику. По схеме вызываемых функций анализируются критические пути, и выбирается путь, выполнение которого занимает наибольшее время. Затем выбранный путь проверяется путем анализа последовательности вызовов, чтобы выявить наиболее подходящие для распараллеливания функции (узлы).
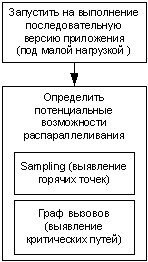
Рисунок 11. Фаза анализа.
Рекомендуется применять анализ схемы вызываемых функций, поскольку данные, полученные с помощью выборки, могут оказаться неподходящими для некоторых типов приложений. Данные выборки иногда имеют "плоские" профили, а выбор правильного уровня выборки не всегда возможен; критические точки могут указывать на функции, которые получают наибольшее число вызовов, но не могут быть распараллелены в силу своего уровня в коде. Для получения правильной картины следует использовать данные схемы вызываемых функций, несмотря на то, что при этом искажается время исполнения за счет внедрения в программу средств измерения.
После выявления в коде фрагментов, наиболее подходящих для распараллеливания, необходимо определить тип параллелизма. Большинство важных решений принимается на этом этапе.
На этапе проектирования проверяется выбранный для реализации тип параллелизма и производятся необходимые изменения в структуре. Если выбранный тип параллелизма может быть реализован с помощью функций библиотек поддержки многопоточности, уже включенных в состав пакета Intel MKL или Intel IPP, некоторые элементы этапа проектирования можно исключить.
Большая часть усилий на этапе проектирования затрачивается на реструктурирование данных и кода. Для этого прежде всего необходимо идентифицировать все обращения потоков к глобальным данным. Без использования специальных инструментов эта задача может быть достаточно громоздкой, особенно для приложений среднего и большого размера, поскольку требуется пройти последовательность всех вызовов потока и проверить все обращения к памяти на наличие запроса глобальных данных.
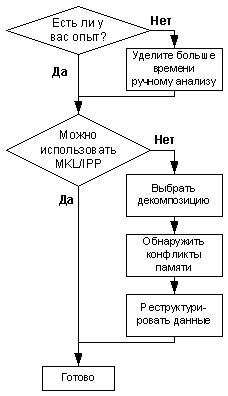
Рисунок 12. Блок-схема этапа проектирования.
Общая методика этапа проектирования показана на рисунке 12 и может быть вкратце описана следующим образом:
a. Выберите тип декомпозиции.
b. Используйте анализатор потоков и OpenMP для обнаружения конфликтов при доступе к памяти. Более подробная информация приведена в документации по анализатору потоков.
c. Проведите реструктуризацию данных в соответствии со специфическими требованиям производительности, как описано в разделе "Реструктуризация данных".
Тип декомпозиции определяет тип реструктуризации данных (в случае необходимости такой реструктуризации).
Функциональная декомпозиция
При решении проблемы функциональной декомпозиции используйте OpenMP в сочетании с компиляторами Intel и анализатором потоков для быстрого обнаружения всех конфликтов памяти в выбранной ветви программы.
Для подготовки ветви программы, которую предполагается распараллелить, сделайте следующее:
// // Global data to the OpenMP // threads // Buffer data1; Buffer data2; #pragma omp parallel sections { // // Operate on the data // #pragma omp section FunctionThread(&data1); #pragma omp section FunctionThread(&data1); } |
После добавления к выбранной для распараллеливания функции псевдокомментариев "#pragma omp sections" библиотека реального времени OpenMP создаст принятое по умолчанию число потоков для системы и выполнит вызов функции FunctionThread() дважды в параллельных потоках. Для выявления конфликтов доступа к памяти, возникающих в данном примере при одновременном обращении нескольких потоков к глобальным данным, используйте анализатор потоков. Затем выявленные ошибки следует тщательно проанализировать и определить требуемые изменения для реструктуризации данных.
При использовании Intel Threading Tools задача, на решение которой обычно тратится от нескольких часов до нескольких дней, может быть решена за несколько минут. Используйте псевдокомментарии OpenMP только для обнаружения конфликтов доступа к памяти. На этапе реализации эти псевдокомментарии следует удалить и заменить соответствующими вызовами подходящих функций распараллеливания.
Декомпозиция данных
OpenMP является идеальным средством распараллеливания данных. Механизмы этого стандарта можно использовать для декомпозиции данных и на этапе проектирования, и на этапе реализации. Элементы OpenMP можно добавлять в приложение постепенно, и обычно, не внося значительные изменения в код. Использование OpenMP практически не затрагивает исходный последовательный код и не влияет в значительной степени на его сопровождение.
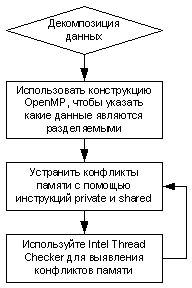
Рисунок 13. Модель решения проблем декомпозиции данных.
Компиляторы OpenMP имеются для большинства ОС. Компиляторы, не поддерживающие OpenMP, просто игнорируют эти псевдокомментарии и выполняют компиляцию исходного последовательного кода. Модель решения проблем декомпозиции данных показана на рисунке 13.
Для устранения конфликтов доступа к памяти используйте итеративный подход. Использование инструкций shared или private, приведенное здесь для описания конкретной модели применения, не означает необходимости использования только таких инструкций для декомпозиции данных.
Основной целью реструктуризации данных является исключение проблем избыточной синхронизации и непреднамеренного совместного использования.
Избыточная синхронизация
Если в профиле потока встречаются обращения к глобальным данным, каждый случай обращения должен быть защищен специальным механизмом синхронизации. Это может привести к росту затрат системных ресурсов вследствие избыточной синхронизации и вызвать снижение производительности.
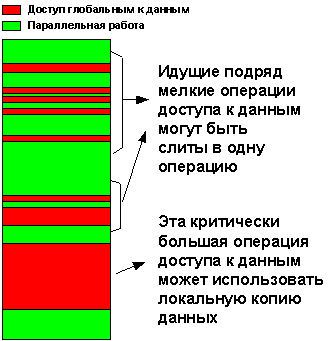
Рисунок 14. Профиль потока с многократными обращениями к глобальным данным.
На Рис. 14 показан профиль потока с многократными обращениями к глобальным данным, отмеченными красным цветом, и параллельной работой, показанной зеленым цветом. Все обращения к общим глобальным данным должны быть защищены механизмами синхронизации для предотвращения конфликтов при доступе к данным. Как показано на рисунке, несколько обращений к глобальным данным, которые расположены рядом друг с другом, можно объединить одной общей точкой синхронизации, что уменьшает общее число точек синхронизации. Если есть два обращения к глобальным данным, и если данные, доступ к которым осуществляется во втором обращении, не изменяются с момента первого обращения, второе обращение можно выполнить сразу же после первого. При защите этих двух обращений к данным с помощью синхронизации две точки можно заменить одной. Кроме того, в случае крупных критических секций можно создать локальную копию общих данных для каждого потока (если организация данных допускает такую оптимизацию).
За счет объединения ближайших обращений к глобальным данным и создания локальных копий блоков общих данных можно значительно увеличить коэффициент ускорения многопоточного приложения. Кроме того, обращения к глобальным данным без их изменения (только для чтения) не требуют синхронизации. Соблюдение этих простых правил реструктуризации данных позволит добиться значительного повышения эффективности масштабирования.
Другим затруднением, которое можно устранить путем реструктуризации данных, является проблема непреднамеренного совместного использования. Два потока могут использовать отдельные блоки данных из одной и той же строки кэша для чтения и записи. Когда один из потоков производит запись данных в строку кэша, эта строка становится недоступной. Любые обращения к данным, хранящимся в этой строке кэша, из второго потока завершатся неудачей (отсутствие кэша), и эту строку кэша придется считывать из памяти заново. Эта ситуация известна как непреднамеренное совместное использование, и если при работе приложения возникает такая ситуация, это может привести к серьезному снижению его производительности.
Проблема непреднамеренного совместного использования обычно проявляет себя, когда приложения используют глобальные массивы состояний для хранения информации о каждом из потоков, как показано ниже в коротком фрагменте кода в примере 10. Проблема непреднамеренного совместного использования проще всего решается на этапе проектирования. Тем не менее, это затруднение можно легко обнаружить на этапе настройки с помощью анализатора производительности VTune.
При использовании функций организации потоков, как показано в примере 10, глобальная переменная sumLocal вызывает ситуацию непреднамеренного совместного использования, когда оба потока производят запись в массив, а используемые ими элементы находятся в одной строке кэша. Каждый раз, когда thread_1 производит запись в этот элемент строки кэша, копия той же самой строки кэша для thread_2 становится недоступной. Теперь поток thread_2 вынужден перезагрузить строку кэша, содержащую эту переменную, перед тем, как записать этот элемент в массив, что в свою очередь делает недоступной копию, используемую потоком thread 1.
double sumLocal[N_THREADS]; ..... ..... void ThreadFunc { ...... int id = p->threadId; sumLocal[id] = 0.0; ...... ...... for (i = 0; i < N; i++) sumLocal[id] += p[i]; // Делает недействительной линию кэша ...... } |
Этот пример демонстрирует экстремальный случай непреднамеренного совместного использования, ведущий к значительному снижению производительности. Для устранения этой проблемы блоки данных каждого потока можно дополнить незначащей информацией, чтобы элементы данных, используемые разными потоками, находились в разных строках кэша.
Другим возможным решением является использование локальной копии данных кэша для проведения всех изменений и последующее глобальное обновление данных, отражающее эти изменения в глобальном блоке данных.
После рассмотрения всех аспектов на этапе проектирования приложение может быть разбито на потоки путем реализации выявленного параллелизма, используя выбранную модель распараллеливания. Рекомендуемая модель распараллеливания зависит от типа декомпозиции:
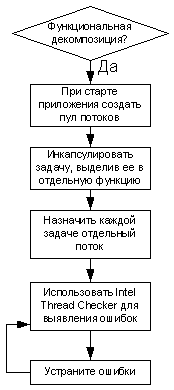
Рисунок 15. Блок-схема методики реализации функциональной декомпозиции.
Блок-схема, показанная на рисунке 15, иллюстрирует только один из примеров методики реализации это далеко не единственный сценарий функциональной декомпозиции. Методику, описанную в этом примере, можно применять для решения большинства проблем функциональной декомпозиции. Там, где возможно применение групп потоков, весьма эффективным решением является использование именно этого типа распараллеливания и распределения задач между неактивными потоками. Данная методика включает следующие этапы:
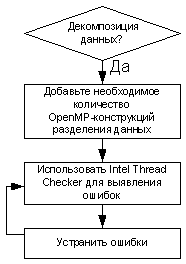
Рисунок 16. Блок-схема методики декомпозиции данных.
Реализация метода декомпозиции данных основывается на средствах OpenMP. OpenMP позволяет легко разбить различные фрагменты приложения на потоки.
Рассмотрим пример расчета числа "пи". Код последовательной программы показан в примере 11.
#include <stdio.h> #include <omp.h> int numIterations = 1000000; int main() { double x; double pi; double sum = 0.0; double step = 1. / (double)num_steps; for (int I = 1; i < numIterations; i++) { x = (i - .5) * step; sum = sum + 4.0 / (1. + x * x); } pi = sum*step; return 0; } |
Число "пи" вычисляется путем численного интегрирования, при этом точность числового значения увеличивается с числом итераций. Этот пример содержит ярко выраженную проблему параллельного выполнения, кроме того, он достаточно прост и может быть использован при объяснении метода декомпозиции. Для понимания этого примера требуются некоторые знания OpenMP.
Для расчета числа "пи" этот фрагмент программы выполняет функцию оценки numIterations раз. Если для этой программы применить анализатор VTune, критическая точка будет обнаружена в цикле for.
Для создания многопоточной версии этого кода с помощью OpenMP используйте блок-схему на рисунке 16. Выделите цикл for в параллельную область OpenMP. Это позволит выполнять цикл for параллельно несколькими потоками, число которых определяется по умолчанию во время работы с OpenMP.
#include <stdio.h> #include <omp.h> int numIterations = 1000000; int main() { double x; double pi; double sum = 0.0; double step = 1. / (double)num_steps; #pragma omp parallel { for (int I = 1; i < numIterations; i++) { x = (i - .5) * step; sum = sum + 4.0 / (1. + x * x); } } pi = sum * step; return 0; } |
В примере 12 показан исходный код, модифицированный за счет применения конструкций OpenMP. Для обнаружения конфликтов доступа к памяти в модифицированной версии программы можно использовать анализатор потоков Intel. Для этого надо прежде всего скомпилировать исходный код с помощью компилятора Intel с параметром /Qopenmp.
Модифицированный исходный код этой программы с учетом конфликтов при обращении к памяти показан в Примере 13.
#include <stdio.h> #include <omp.h> int numIterations = 1000000; int main(int argc, char* argv[]) { double x; double pi; double sum = 0.0; double step = 1. / (double)num_steps; #pragma omp parallel private(x) shared(sum) { #pragma omp for reduction(+: sum) for (int I = 1; i < numIterations; i++) { x = (i - .5) * step; sum = sum + 4.0 / (1. + x * x); } } pi = sum * step; printf("Pi = %f\n", pi); return 0; } |
Эта методика применяется до тех пор, пока не будут исключены все обнаруженные ошибки. В данном примере быстрое распараллеливание обеспечивает конструкция разделения заданий omp for.
После разбиения приложения на потоки необходимо проверить правильность его работы, и сравнить результаты его работы с результатами, полученными при выполнении последовательной версии. В большинстве случаев этапы отладки и тестирования чередуются.
На этапе отладки устраняются все несоответствия, обнаруженные на этапе тестирования. Этот циклический процесс продолжается до тех пор, пока полученные результаты не совпадут с результатами выполнения последовательного приложения.
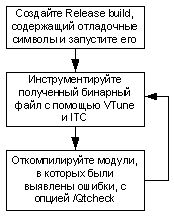
Рисунок 17. Методика отладки.
На рисунке 17 показан метод, предлагаемый для отладки больших приложений. Release-версия с символами отладки выполняется быстрее. Дополнительное преимущество заключается в отсутствии потребности компилировать приложение со средствами измерения, встроенными в исходный код. Использование release-версии особенно удобно для приложений, сборка которых занимает несколько часов. После выявления конфликтов доступа к памяти данная методика предлагает использовать встраиваемые в исходный код средства измерения только для тех модулей, в которых анализатор потоков Intel обнаружил ошибки.
С помощью параметра /Qtcheck средства измерения, встроенные в исходный код, позволяют выделить информацию о переменных, которые привели к появлению этих конфликтов. Этот метод значительно экономит время при отладке.
На рисунке 18 приводится копия экрана анализатора потоков, на которой показаны конфликты при доступе к памяти. Двойной щелчок мышью на ошибке показывает строки исходного кода, которые привели к появлению этой ошибки.
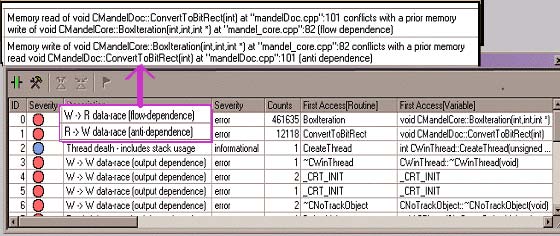
Рисунок 18. Экран анализатора потоков, на котором показаны конфликты при доступе к памяти.
Ошибки указывают на две переменные, x и sum. Эти переменные являются глобальными по отношению к потокам и вызывают конфликты при выполнении параллельной версии. Для устранения конфликтов переменная x объявляется private, а переменная sum помечается инструкцией reduction.
Показанный на рисунке 19 метод позволяет оценить безопасность использования DLL при распараллеливании; на основании полученных результатов принимается решение о возможности использования функций этой DLL.

Рисунок 19. Проверка DLL на безопасность использования при распараллеливании.
Для проверки DLL на безопасность использования при распараллеливании следует сделать следующее:
У этого подхода есть один недостаток: если DLL используют OpenMP и исходный код этих библиотек не доступен, анализатор потоков может давать ложные положительные заключения. В примере 14 показан фрагмент кода, в котором псевдокомментарии OpenMP использованы для определения безопасности использования DLL при распараллеливании.
Buffer data[2]; . . . . . . . #pragma omp parallel sections { #pragma omp section DllFunc(&data[0]); #pragma omp section DllFunc(&data[1]); } |
При тестировании приложения сравниваются результаты работы многопоточной и последовательной версий приложения. Если на этом этапе анализатор потоков не обнаружит ошибок, то можно смело предположить, что большинство конфликтных ситуаций при выполнении выявлены и устранены.
Если результаты выполнения многопоточной версии приложения совпадут с результатами последовательной версии, то приложение можно считать согласованным.
После проверки работы многопоточного приложения на отсутствие ошибок можно сконцентрировать усилия на настройке приложения с целью получения оптимальной производительности. К началу этого этапа разработки большинство долго исполняющихся операций уже оптимизировано при реструктуризации данных.
Чтобы выявить потенциальные проблемы производительности, используйте следующие инструментальные средства:
Для анализа производительности OpenMP-приложений используйте профилировщик потоков в составе анализатора VTune. Для просмотра статистических данных о производительности приложения OpenMP соберите приложение с параметром /Qopenmp_profile для подключения инструментальных библиотек времени исполнения.
В качестве альтернативы можно собрать приложение с параметром /Qopenmp, но запускать его следует в среде VTune, чтобы на время выполнения библиотека OpenMP была заменена ее инструментальной версией.
Если приложение собрано с параметром /Qopenmp_profile, его можно запускать из командной строки. По завершении работы приложения создается файл .gvs, который можно просмотреть в среде VTune.
Профилировщик потоков позволяет просматривать данные нескольких сеансов выполнения приложения и сравнивать их. Он поддерживает несколько видов представления данных, предоставляя сводные данные о производительности приложения или данные с разбивкой по потокам.
Поскольку конструкции OpenMP носят структурированный характер, характеристики приложения можно просматривать по фрагментам, например, по параллельным фрагментам, по последовательным фрагментам и т. п.
На рисунке 20 (а) показан пример результатов Activity (действий) в представлении Summary (Сводный отчет) профилировщика потоков для приложения с дисбалансом потоков. На рисунке 20 (б) показаны результаты для исправленного приложения.
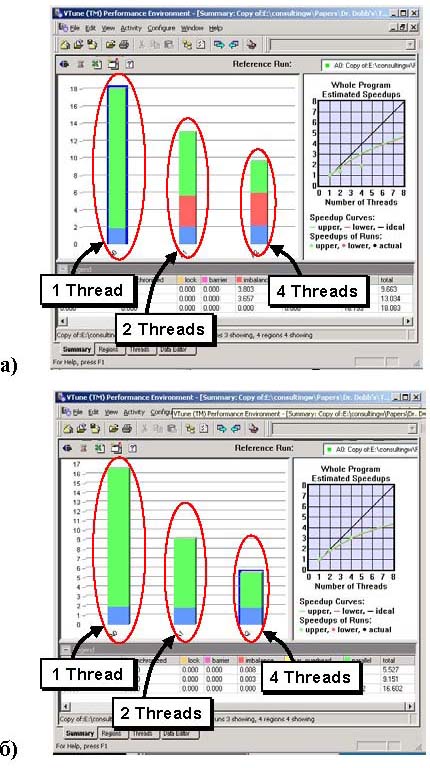
Рисунок 20. (a) – экран профилировщика потоков, демонстрирующая дисбаланс нагрузки; (б) – исправленная версия.
В этом примере показатель масштабирования для приведенной на рисунке 20 (а) несбалансированной версии составляет для двух и четырех потоков соответственно ~1,4 и ~2,1.
Представление Summary (Cводный отчет) содержит следующие временные категории, обозначенные различными цветами: последовательная, последовательная с затратами системных ресурсов, синхронизированная, с блокировками, с барьерами, несбалансированная, параллельная с затратами системных ресурсов и параллельная.
В документе Developing Multithreaded Applications: A Platform Consistent Approach (Разработка многопоточных приложений: совместимость с платформами), который находится на web-узле, посвященном инструментальному пакету Threading Tools, приведены советы о том, как избежать проблем распараллеливания, например, дисбаланса нагрузки.
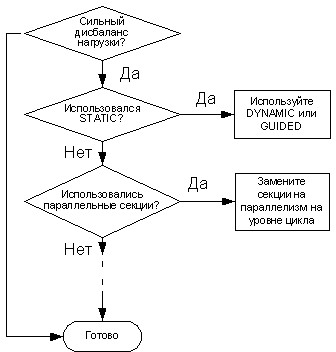
Рисунок 21. Простая блок-схема алгоритма действий по устранения дисбаланса нагрузки.
За счет устранения дисбаланса показанная на рисунке 20 (a) проблема была устранена со значительным выигрышем в производительности. На рисунке 20 (б) отражена производительность того же приложения после применения рекомендаций, приведенных для данной проблемы. Показатель масштабирования, полученный после внесения исправлений, для двух и четырех потоков стал равным ~1,8 и ~2,9 соответственно. На рисунке 21 показана типовая блок-схема решения проблемы дисбаланса нагрузки.
Ниже обсуждаются данные, предоставляемые профилировщиком потоков для Windows API, а также использование этих данных для выявления и локализации критических мест, ограничивающих производительность параллельного выполнения многопоточных приложений. Анализатор потока оснащает приложение инструментальными средствами измерения, вставляя вызовы функций сбора статистики из библиотеки анализатора потока. Анализатор потока исполняет программу и анализирует критические ветви, чтобы определить, оказывает ли какая-либо задержка многопоточного приложения влияние на общее время выполнения приложения. Критический путь – это ветвь приложения с наибольшим временем выполнения. Для получения более подробной информации о критических путях и их анализе см. интерактивную документацию по профилировщику потоков.
Для работы приложения с подключением средств инструментирования в среде VTune оно должно быть скомпоновано с параметром /fixed:no. После подключения этих средств и запуска приложения в среде VTune в программе просмотра профилировщика потоков можно увидеть результаты действий. Теперь все готово для выявления критических мест, ограничивающих производительность.
На рисунке 22 показан экран профилировщика потоков, представляющий Critical Path (критический путь) в случае приложения с одним основным и четырьмя рабочими потоками. Этот профиль показывает время последовательного выполнения приложения (оранжевый цвет), когда один поток блокирует выполнение других за счет удерживания какого-либо ресурса, время параллельного выполнения (зеленый цвет) и затраты системных ресурсов (желтый цвет).

Рисунок 22. Critical Path (критический путь) в случае приложения с одним основным и четырьмя рабочими потоками.
Для получения более подробной информации дважды щелкните мышью на критическом пути, и на экран будет выведено представление Profile (Профиль). На рисунке 23 показано представление Threads (Потоки), выбранное в представлении Profile (Профиль). Это представление содержит информацию обо всех выполняемых в системе потоках, время, затраченное на критический путь, и время жизни потоков. Время жизни потоков отмечено полупрозрачным зеленым цветом. Темно-зеленым полупрозрачным цветом отмечено время, затраченное каждым потоком на прохождение критического пути, а непрозрачным цветом обозначено состояние каждого потока на критическом пути.
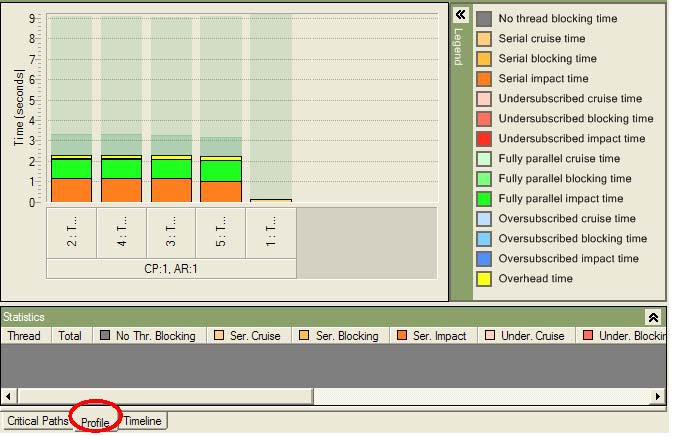
Рисунок 23. Представление Threads (Потоки) на вкладке представления Profile (Профиль).
С помощью представления Threads (Потоки) можно судить о сбалансированности потоков и необходимости внесения изменений в используемые алгоритмы. Другим важным представлением на вкладке Profile (Профиль) является представление Objects (Объекты). Здесь показаны все используемые приложением объекты синхронизации и распараллеливания, а также влияние каждого из этих объектов на время выполнения. Пример копии экрана представления Objects (Объекты) показан на рисунке 24.
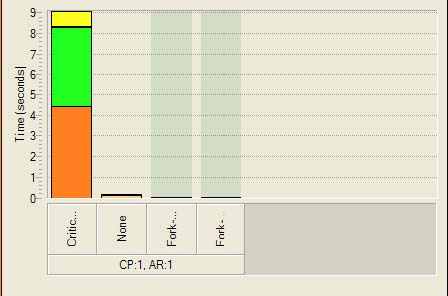
Рисунок 24. Представление Objects.
Во взятом для примера приложении используются два основных объекта, которые оказывают воздействие на время выполнения. Объект критической секции, оказывающий наиболее сильное воздействие, и объект разветвления/слияния (WaitForMultipleObjects) с минимальным временем воздействия. Теперь можно сгруппировать объекты с потоками и определить, на какие из потоков приложения оказывают воздействие эти объекты синхронизации. Представление, позволяющее сгруппировать объекты с потоками, показано на рисунке 25.
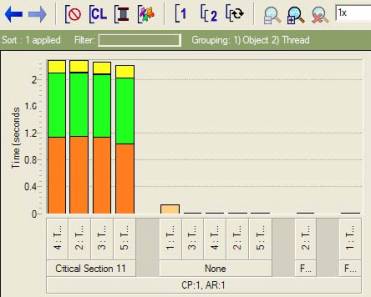
Рисунок 25. Представление, группирующее объекты с потоками.
На рисунке 25 видно, что объект критической секции 11 влияет на выполнение потоков 2, 3, 4 и 5. Строку исходного кода для этого случая можно вывести на экран с помощью всплывающего меню, которое вызывается щелчком правой кнопки мыши. Кроме критических мест, ограничивающих производительность, профилировщик потока также отображает высокоуровневое представление о деятельности каждого потока приложения. Для этого требуется активизировать дополнительные функции – Thread activity (Действия потоков) и Transitions (Переходы). Однако при подключении этих функций выполнение приложения замедлится вследствие затрат системных ресурсов на сбор этой информации. На рисунке 26 показан пример копии экрана такого представления.
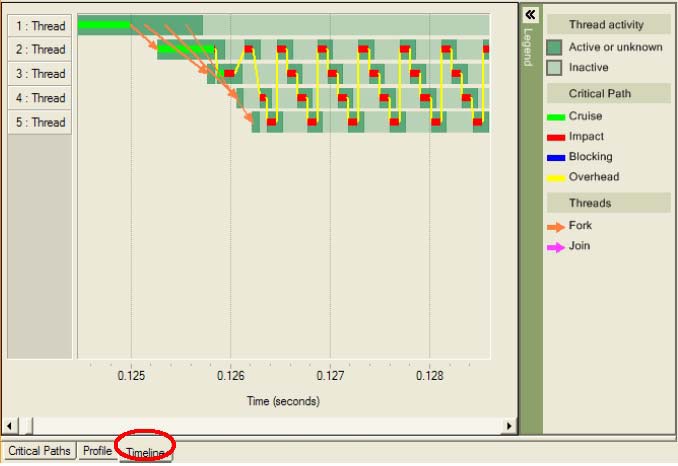
Рисунок 26. Представление Timeline (шкала времени).
В представлении Timeline (Шкала времени), показанной на рисунке 26, четко видно, когда поток заблокирован (светло-зеленый цвет), а когда активен (темно-зеленый цвет). При наведении указателя мыши на желтые линии появляется информация об объектах синхронизации, вызывающих запуск одного потока и блокировку остальных.
Анализатор производительности VTune представляет собой мощный инструмент, анализирующий характеристики приложения с помощью комбинации различных технологий. Вы можете использовать выборку дискретных данных (sampling) для сбора информации о работе системы посредством специальных счетчиков событий, встроенных в микропроцессор.
Информация о параметрах работы приложения записывается и может быть проанализирована для поиска различных данных, например, критических точек, невыполненных команд, неправильно предсказанных ветвлений, потерь данных в кэше, конфликтов при доступе к памяти (memory aliasing), зависаний и многого другого. Можно использовать анализ схемы вызываемых функций для сбора информации о дереве вызовов, числе вызовов функций, времени выполнения функций, времени ожидания функций и выявления критического пути. Для анализа по схеме вызываемых функций анализатор VTune инструментирует загруженный в память программный код, что позволяет собирать информацию о вызовах. Для анализа параллельных приложений можно использовать комбинацию анализа по выборке и анализа по схеме вызываемых функций. Анализатор VTune является дополнением к анализатору потоков Intel и профилировщику потоков. В Таблице 2 приведены некоторые из ключевых различий между этими инструментами.
| Инструмент или функция анализатора производительности VTune | Выборка | Схема вызываемых функций | Анализатор потоков | Профилировщик потоков |
|---|---|---|---|---|
| Типичные затраты системных ресурсов во время выполнения | 1-2%. Зависит от частоты выборки. Может быть намного меньше. | 5-25%. Зависит от числа вызовов функций. | 50-500% или более. Зависит от числа обращений к памяти. | 5-25%. Зависит от числа псевдокомментариев OpenMP*. |
| Какое ПО может анализироваться? | Любое работающее ПО. | ПО, связанное с одним проверяемым процессом. | ПО, связанное с одним проверяемым процессом. | ПО, содержащее псевдокомментарии OpenMP. |
| Требуемая настройка | Нет. Требуются отладочные символы и исходный код. | Параметр компоновщика /fixed:no | Параметр компоновщика /fixed:noПараметр компилятора /Qtcheck для подробного анализа. | Параметр компилятора /Qopenmp_profile для автономного профилирования./Qopenmp для анализа в среде VTune Performance Environment. |
| Какие данные требуются? | Данные процессора, такие как указатель команд и счетчики событий. Возможны сотни событий. | Синхронизация функций и данные дерева вызовов. | Данные потоков, такие как синхронизация, параллельные конструкции и обращения к памяти | Синхронизация параллельных и последовательных переходов, блокировок, барьеров и других ситуаций синхронизации при выполнении псевдокомментариев OpenMP. |
Балансировка нагрузки потоков является одним из самых простых видов оптимизации производительности параллельных приложений. Оптимальной является ситуация, когда все процессоры заняты активной обработкой рабочих заданий, а наихудшей – если один или несколько процессоров простаивают в ожидании завершения других потоков. Балансировка нагрузки требует знаний о том, выполнение каких потоков (по их структуре) должно занимать примерно одинаковое время.
Анализатор VTune представляет информацию для оценки баланса нагрузки двумя способами – в виде схемы вызываемых функций и в виде анализа выборки. При использовании схемы вызываемых функций время автосинхронизации дерева вызовов при надлежащем балансе загрузки должно быть схоже с таковым у других потоков. Не все потоки в системе должны быть сбалансированы – только те, для которых это предусмотрено проектом.
На рисунке 27 показаны два потока, выполнение которых должно занимать одно и то же время, но на самом деле этого не происходит. Следовательно, два этих потока не сбалансированы.
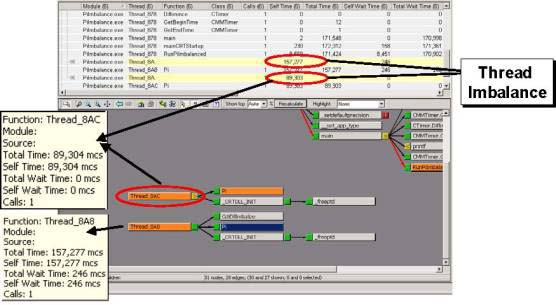
Рисунок 27. Диаграмма вызовов функций анализатора VTune показывает дисбаланс потоков.
Выборка данных – другой метод оценки баланса потоков. Сбалансированные потоки должны иметь приблизительно одинаковое количество событий синхронизации (отметок импульсов синхронизации), и эти события должны быть равномерно распределены между процессорами.
В общем случае для анализа баланса нагрузки с помощью сборщика данных анализатора Vtune следует выполнить следующие действия:
На рисунке 28 показан сеанс выборки для 4 потоков. Допустим, что четыре потока должны затрачивать равное количество времени, поскольку это определено самой структурой программы. Однако видно, что горизонтальные полосы для двух верхних потоков намного короче, чем полосы нижних. Для двух нижних потоков было собрано больше значений, то есть выполнение этих потоков заняло большее время. Эти четыре потока не сбалансированы.
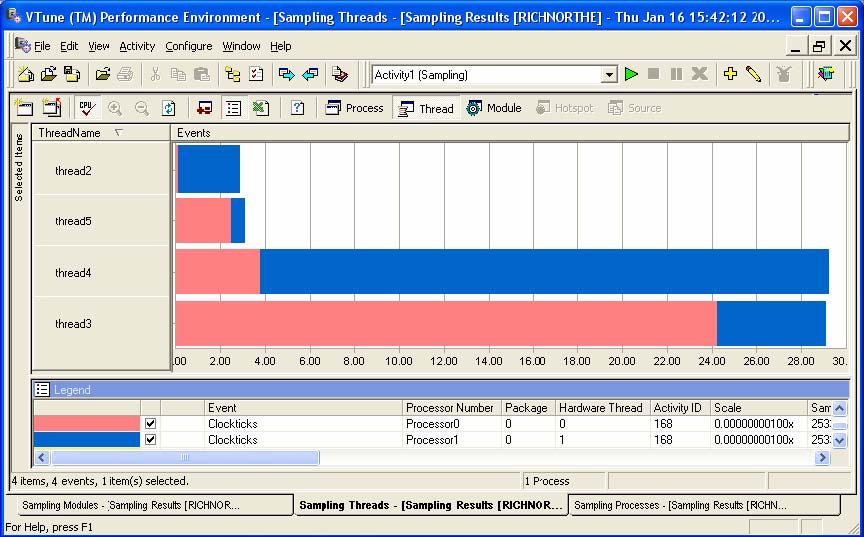
Рисунок 28. Сеанс выборки для 4 потоков.
На рисунке 28 следует отметить интересный факт – хотя выполнение потоков и занимает разное время, работа по их выполнению равномерно распределена между имеющимися процессорами.
Если диаграмма показывает, что по крайней мере один из процессоров активен более других, то это означает появление дисбаланса нагрузки, причины которого следует исследовать.
К сожалению, возможна ситуация, когда кажется, что потоки сбалансированы, хотя на самом деле они выполняются последовательно. Если несколько потоков выполняются в течение равных промежутков времени на разных процессорах, причем это происходит последовательно, график показывает сбалансированную ситуацию. Во избежание таких недоразумений необходимо знать, что потоки в действительности выполняются одновременно и параллельно. Такая ситуация возникает только в том случае, если процессоры простаивают, однако анализатор VTune может быстро и просто обнаружить время простоя.
Выборка по времени (time-based sampling, TBS) определяет время простоя путем замеров в цикле ожидания операционной системы, а также производя максимальное количество измерений. На рисунке 29 показаны данные замеров, собранные в модуле processr.sys, который содержит цикл ожидания операционной системы.
По накоплению данных замеров в processr.sys можно сделать вывод о возникновении простоя. Рисунок 29 также показывает, что многие замеры производились в кольце 0, на привилегированном уровне, зарезервированном для операционной системы, что также свидетельствует о цикле простоя.
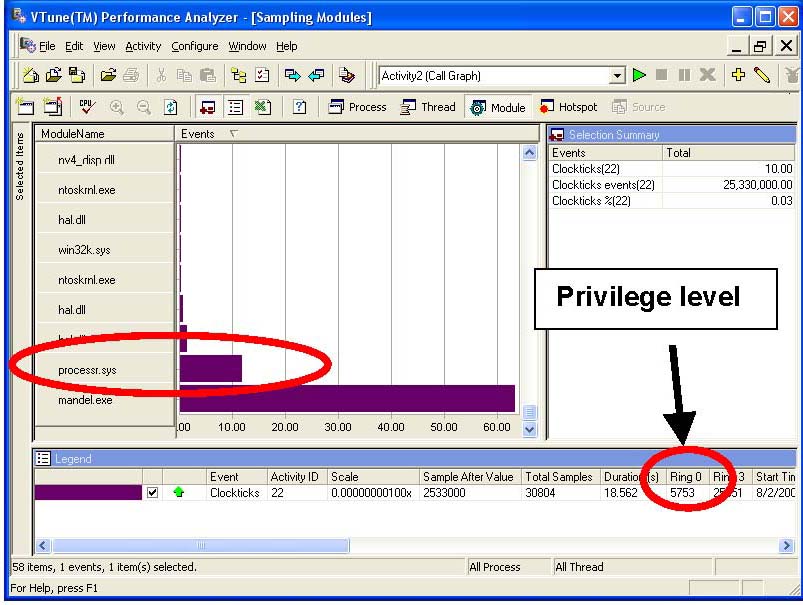
Рисунок 29. Данные замеров, собранные в модуле processr.sys.
Перерасход системных ресурсов – это кошмар с точки зрения производительности независимо от того, используются потоки или нет. Избыточные затраты системных ресурсов могут быть вызваны другими процессами, выполняющимися в системе, другими модулями, выполняющимися в рамках данного процесса, или неэффективностью кода, выполняемого в данном модуле. Анализатор VTune отображает потенциальные затраты системных ресурсов, вызванные другими процессами, выполняемыми в системе, в представлении Process (Процесс). Показанные на рисунке 30 данные замеров, собранные для других процессов, являются свидетельством перерасхода системных ресурсов.
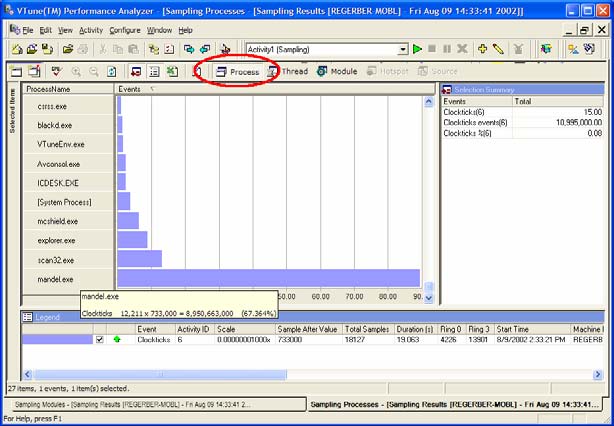
Рисунок 30. Представление Process (Процесс).
Перерасход системных ресурсов можно также обнаружить в представлении Module (Модуль), показанном на рисунке 31, где ряд замеров пришелся на драйвер. Не имея сведений о том, что происходит, нельзя быть на 100% уверенным в том, что эти замеры свидетельствуют об избыточных затратах системных ресурсов. Однако при каждом обнаружении расхода времени за пределами рассматриваемого приложения следует провести дополнительное расследование.
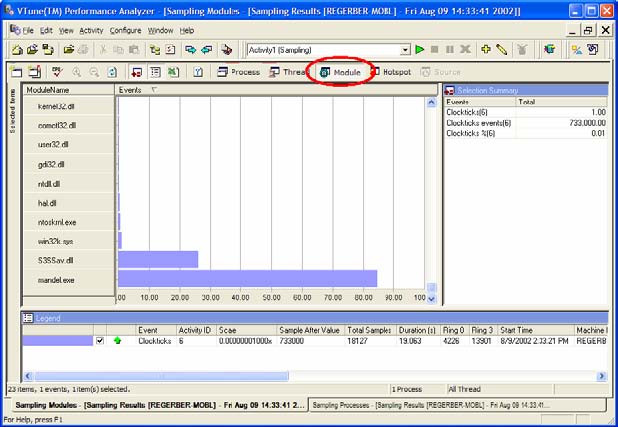
Рисунок 31. Представление Module (Модуль).
Избыточные затраты системных ресурсов могут также происходить в пределах самого приложения. Повторимся – крайне важно четко понимать, какие задачи решает приложение, иначе можно пропустить серьезную проблему в отношении производительности. На рисунке 32 показаны критические точки приложения.
Рисунок 32. Критические точки приложения.
Избыточные затраты системных ресурсов можно обнаружить по затратам времени, зафиксированным в функции _ftol(), преобразующей число с плавающей точкой в целое число. Работа функции _ftol() может расцениваться как перерасход системных ресурсов в любой ситуации, и только при использовании компилятора Intel C++ и компиляции программы для процессора Pentium 4 или более современного, можно полностью исключить эти затраты. В других случаях для устранения или снижения этих затрат в разрабатываемое приложение необходимо внести изменения.
Синхронизация, затраты системных ресурсов, время простоя и переключения контекстов связаны друг с другом. Если предполагается, что затраты системных ресурсов на синхронизацию ухудшают производительность, то разобраться в ситуации могут помочь другие функции анализатора VTune. Используя сборщик данных монитора счетчика (counter monitor data collector), можно отслеживать переключения контекстов, как показано на рисунке 33. Места частых переключений контекста могут означать избыточные затраты системных ресурсов на синхронизацию.
Рисунок 33. Данные монитора счетчика позволяют понять причинно-следственные связи между подсистемами компьютера и вашим приложением.
В целом анализатор VTune и подключаемый модуль профилировщика потоков предоставляют много функций, позволяющих оценить, в какой степени реальная многопоточная производительность совпадает с ожидаемой. Анализатор – это только инструмент, который помогает оценить верхнюю границу производительности для любого многопоточного приложения, в особенности для приложений с параллелизмом данных. Например, если сравнить наблюдаемую загрузку шины двухпоточным приложением при выполнении на четырехпроцессорной системе с загрузкой шины четырехпоточным приложением, можно построить соответствующие графики использования и оценить число потоков, при котором происходит насыщение шины. Эта информация может дать разработчику представление о верхней границе количества потоков, которое приложения могут использовать на четырехпроцессорной системе.
В процессорах, использующих гиперпоточную технологию, возможно иметь несколько логических процессоров на один физический. Информация о состоянии, требуемая для поддержки работы каждого логического процессора, копируется при совместном использовании или разделении ресурсов поддерживающего их физического процессора. Поскольку ресурсы процессора, как правило, недостаточно используются большинством приложений, процессоры, использующие гиперпоточную технологию, позволяют повысить общую производительность приложений. Несколько выполняющихся параллельно потоков позволяют обеспечивать большую степень использования процессора и более высокую пропускную способность.
Первым шагом в распараллеливании приложений для систем с применением гиперпоточной технологии является применение методики проектирования, реализации, отладки, настройки и проверки производительности приложений для симметричных многопроцессорных систем (SMP). Многопоточные приложения, хорошо работающие на системах SMP, будут в общем также хорошо работать на системах с применением гиперпоточной технологии. Однако не следует путать процессоры, использующие гиперпоточную технологию, с системами SMP. Все физические ресурсы каждого процессора в системе SMP доступны, и конфликты на этом уровне исключены. Хорошо спроектированные многопоточные приложения лучше работают на системах SMP и должны давать повышение производительности при выполнении на процессорах с гиперпоточной технологией.
Вторым шагом является ознакомление с документом Intel Pentium 4 and Intel Xeon Processor Optimization Manual (Руководство по оптимизации процессоров Intel Pentium 4 и Intel Xeon) и описанием гиперпоточной технологии, приведенным на web-узле поддержки разработчиков Intel.
Для эффективного использования ресурсов процессора и системы следует закладывать в проект приложения определенную гибкость. Например, многопоточные приложения могли бы определять число физических процессоров в системе и затем создавать соответствующее число потоков.
Процессоры Intel Pentium 4 и Intel Xeon предоставляют информацию о различных уровнях и размерах кэша, доступных для определенного процессора. Поскольку конфигурация кэша не определяется микроархитектурой Intel Netburst, этот ресурс процессора может иметь разные характеристики для разных моделей. Используя гибкие механизмы, связанные с уровнями и размером кэша, приложения могут динамически оптимизировать распределение данных и вычисления для обеспечения максимального использования кэша.
При проектировании приложений для работы на процессорах с применением гиперпоточной технологии учитывайте, что единственная дублируемая сущность – это состояние процессора. Все прочие ресурсы либо совместно используются логическими процессорами, либо разделены между ними.
Совместно используемый ресурс – это ресурс, который может быть полностью использован каждым логическим процессором, однако доступ к этому ресурсу предоставлен всем логическим процессорам. Это может привести к конфликтам при доступе к ресурсам. Несмотря на то, что ресурс может использоваться совместно, он может быть зарезервирован для индивидуального использования отдельным логическим процессором.
Конфликт при доступе к ресурсам может привести к зависанию логического процессора в ожидании доступности занятого ресурса. В случае разделенных ресурсов логический процессор может использовать только выделенную ему часть ресурсов. Если логический процессор не использует выделенную ему часть ресурсов, она все равно не доступна для других логических процессоров.
Иерархии кэш-памяти и для команд, и для данных используются совместно. Буферы хранения данных с комбинированной записью используются совместно. Все ресурсы исполнительных устройств используются совместно. Однако буферы загрузки/хранения данных, буферы поиска в таблицах, очередь команд в исполнительные устройства и буфер реорганизации команд являются раздельными ресурсами. Расшифровка и доставка команд используются совместно по циклическому правилу при условии, что ни одна из очередей команд логического процессора не зависла. В случае зависания любого логического процессора вследствие переполнения очереди команд исполнительных устройств, другие логические процессоры могут воспользоваться доступными ресурсами для продолжения декодирования/доставки дополнительных команд.
Процессор с применением гиперпоточной технологии не увеличивает размер кэша данных, но поддерживает дополнительные логические процессоры. Если приложение было оптимизировано для работы с кэш-памятью определенного размера на определенном количестве физических процессоров, то в системе, использующей процессоры с гиперпоточной технологией, производительность, скорее всего, ухудшится. Это произойдет потому, что каждый из логических процессоров будет пытаться полностью использовать кэш, в результате чего будут возникать конфликты. Но если в приложение заложить определенную гибкость в отношении определения числа логических и физических процессоров, уровней и размера кэша, то можно добиться максимальной производительности приложения и на системах SMP, и на процессорах, использующих гиперпоточную технологию.
Для получения качественных, высокопроизводительных многопоточных приложений нужно еще при проектировании избегать хорошо известных ошибок программирования. Это правило распрастраняется и на остальные этапы разработки ПО. Реализация приложений с применением гиперпоточной технологии в общем случае выходит за рамки собственно приложения и включает компоненты или библиотеки, предоставленные сторонними разработчиками. При реализации таких приложений должны использоваться компоненты или библиотеки, безопасные в отношении многопоточного выполнения и разработанные специально для процессоров, использующих гиперпоточную технологию. Для синхронизации рекомендуется использовать функции библиотек операционной системы и/или библиотек поддержки многопоточности вместо реализации специфических механизмов в самом приложении, например, пустых циклов с ожиданием. Библиотеки операционных систем и поддержки многопоточности вероятнее всего уже оптимизированы для работы с различными процессорами. Оптимизация может быть автоматически использована в приложениях путем их перекомпоновки и/или посредством использования динамических библиотек.
Для многопоточных приложений, работающих на процессорах с гиперпоточной технологией, не существует каких-либо особых методов отладки. Для таких приложений следует использовать те же методы и инструменты отладки, которые применяются для систем SMP.
Для получения наилучшей производительности рекомендуется сначала оптимизировать приложения для работы с процессором Intel Pentium 4, а уже затем для процессоров с гиперпоточной технологией. Если производительность на системах с гиперпоточной технологией не настолько высока, как предполагалось, ознакомьтесь с последней версией документа Intel Pentium 4 and Intel Xeon Processor Optimization Manual (Руководство по оптимизации процессоров Intel Pentium 4 и Intel Xeon), а также с описанием гиперпоточной технологии, которые находятся на web-узле поддержки разработчиков Intel. Обратите внимание на существующие возможности оптимизации гиперпоточной технологии и ловушки, которые могут встретиться в программном коде разрабатываемого приложения.
Если производительность все еще ниже ожидаемой, то на следующем шаге следует ограничиться рассмотрением проблем производительности процессоров с гиперпоточной технологией. Получите результаты оценки производительности по каждой из следующих конфигураций:
При сравнении полученных результатов проверьте, связано ли ухудшение производительности с применением многопроцессорных систем. Убедитесь в том, что производительность системы с двумя процессорами Pentium 4 соответствует предполагаемой и превышает производительность системы с одним процессором Pentium 4 без применения гиперпоточной технологии. Если это не так или если ускорение производительности крайне невелико, то усилия следует сконцентрировать на настройке с помощью стандартной методики SMP.
Затем убедитесь в том, что производительность одного процессора Pentium 4 с многопроцессорным ядром снижается по сравнению с производительностью одного процессора Pentium 4 с однопроцессорным ядром менее, чем на 5%. Обратите внимание на то, что производительность однопоточных (или практически однопоточных) приложений может снизиться за счет затрат системных ресурсов в системах с многопроцессорным ядром, которые отсутствуют в системах с однопроцессорным ядром.
Наконец, убедитесь в том, что производительность на процессорах с применением гиперпоточной технологии ниже, чем на одном процессоре Pentium 4 с многопроцессорным ядром. Предполагая достаточную производительность на системах SMP и пониженную производительность на процессорах с применением гиперпоточной технологии, переходите к поиску основной причины ухудшения производительности с помощью анализатора производительности Intel VTune.
Для выявления проблем и получения рекомендаций по настройке используйте мастер настройки Intel Tuning Assistant, включенный в состав анализатора VTune. Мастер настройки использует методику, учитывающую особенности архитектуры, для выдачи полезных рекомендаций по сбору и интерпретации данных о событиях, полученных от процессора.
В дополнение к данным, собранным для процессоров, использующих гиперпоточную технологию, соберите такие же данные для систем с одним процессором Pentium 4 без гиперпоточной технологии и для систем с двумя процессорами Pentium 4. Сравнение времени, выраженного в tick-ах системного таймера, между системами может ограничить область поиска критической точки, где затрачивается время процессора.
Для многопоточных приложений, работающих на процессорах с гиперпоточной технологией, не существует каких-либо особых методов контроля производительности. Для таких приложений следует использовать те же методы, инструменты и нагрузки для выполнения контроля производительности, которые применяются для систем SMP.
При настройке приложения для работы на процессорах с гиперпоточной технологией следует учитывать известные ловушки. Подробно эти ловушки описаны в документе Intel Pentium 4 and Intel Xeon Processor Optimization Manual (Руководство по оптимизации процессоров Intel Pentium 4 и Intel Xeon) и в описании гиперпоточной технологии, которые находятся на web-узле поддержки разработчиков Intel. Краткое описание каждой из известных проблем приводится в следующих разделах.
Пустой цикл с ожиданием – это метод, используемый в многопоточных приложениях, где один поток ожидает выполнения определенных задач другими потоками. Ожидание может потребоваться для защиты критической секции, для реализации барьеров или для других способов синхронизации. Типичная структура пустого цикла с ожиданием включает цикл, который сравнивает переменную синхронизации с заданным значением (см. Пример 15).
while (sync_var != predefine_value) { __asm PAUSE Sleep (0); } |
На процессоре с суперскалярным спекулятивным исполнительным модулем применение пустого цикла с ожиданием порождает многочисленные запросы чтения, выдаваемые ожидающим потоком из быстро работающего цикла. Эти запросы генерируются хаотически. Когда процессор обнаруживает, что один поток читает данные, изменяемые в этот момент другим потоком, он должен гарантировать отсутствие нарушений порядка доступа к памяти. На обеспечение правильного порядка выполнения ожидающих выполнения операций с данными в памяти процессор затрачивает существенные ресурсы, вследствие чего производительность снижается. Это снижение можно существенно уменьшить путем использования в цикле команды PAUSE.
Если пустой цикл с ожиданием начинается до того, как поток изменит значение переменной, то пустой цикл потребляет ресурсы системы, не выполняя какой-либо полезной работы. Чтобы избежать потерь процессорных циклов, которые могут быть использованы ожидающим потоком, вставьте в цикл вызов функции Sleep(0). Это позволит передать упрвление другому потоку, находящемуся в состоянии ожидания. Но если ожидающего потока нет, то пустой цикл с ожиданием продолжит работу.
На многопроцессорных системах пустой цикл с ожиданием потребляет системные ресурсы, но не оказывает влияния на производительность приложения. В системах с применением гиперпоточной технологии потребление вычислительных ресурсов без выполнения какой-либо полезной работы может отрицательно сказаться на общей производительности приложения.
Поэтому предпочтительным решением для исключения пустых циклов с ожиданием для конкретных приложений является замена таких циклов функцией блокировки потока операционной системы, включенной в интерфейс программирования приложений, например, функцией WaitForMultipleObjects. Вызов этой функции приведет к тому, что операционная система заблокирует ожидающий поток, не давая ему тратить ресурсы процессора.
Если имеется такая возможность, данные считываются из кэша первого уровня, который является самым быстрым. Если данные находятся на другом уровне, процессор попытается считать их со следующего уровня и т. д. Запись данных производится в кэш первого уровня только в том случае, если этот кэш уже содержит определенную записанную строку и производит сквозную запись в кэш второго уровня в любом случае. Если строка кэша данных не находится в кэше второго уровня, ее необходимо извлечь из более отдаленной области в иерархии памяти перед завершением записи.
Операции сохранения данных помещают данные в "буферы хранения", которые остаются зарезервированными до завершения хранения. Имеется также несколько буферов хранения с "комбинированной записью", каждый из которых содержит строку кэша длиной 64 байта. Если сохранение выполняется по адресу, находящемуся в пределах одной из строк кэша буфера хранения, данные зачастую могут быть быстро перемещены в буфер хранения с комбинированной записью и скомбинированы с данными, хранящимися в нем, что позволяет завершить операцию сохранения намного быстрее, чем запись в кэш второго уровня. Эта операция оставляет буфер хранения незанятым для возможного использования в ближайшем будущем, сводя к минимуму вероятность перехода в состояние, в котором все буферы хранения заполнены, а процессор будет вынужден прекратить обработку и ожидать освобождения буфера хранения.
Архитектура Intel NetBurst, реализованная в процессорах Intel Pentium 4 и Intel Xeon, имеет шесть буферов хранения с комбинированной записью. Если приложение производит запись более чем в четыре строки кэша примерно в одно и то же время, буферы хранения с комбинированной записью начинают переносить информацию в кэш второго уровня. Это делается для того, чтобы обеспечить готовность буфера хранения с комбинированной записью к комбинированию данных для записи в новую строку кэша. Для получения наивысшей производительности в документе Intel Pentium 4 Processor and Intel Xeon Processor Optimization приведены рекомендации по выполнению записи во внутреннем цикле не более, чем по четырем различным адресам или массивам, что исключает использование более четырех строк кэша одновременно.
При использовании процессоров с применением гиперпоточной технологии буферы хранения с комбинированной записью совместно используются двумя логическими процессорами одного физического процессора. Поэтому при принятии решения о том, смогут ли буферы хранения с комбинированной записью обработать все операции записи, должно быть учтено общее число одновременно выполняемых операций записи обоими потоками, запущенными на двух логических процессорах. Для того, чтобы быть уверенным в получении максимальной производительности путем полного использования преимуществ буферов хранения с комбинированной записью, рекомендуется разбить код внутреннего цикла на несколько внутренних циклов, каждый из которых производит запись не более чем в две области памяти.
В общем случае нужно следить за тем, чтобы данные записывались в массивы с увеличением индекса, а также за тем, чтобы операции записи по указатели производились с последовательным перемещением по адресному пространству. Операции записи в элементы структуры небольшого размера или в несколько последовательных областей хранения данных обычно могут считаться одной операцией записи, поскольку они часто попадают на одну строку кэша и могут быть скомбинированы для записи в одном буфере хранения с комбинированной записью.
Процессор Intel Xeon с применением гиперпоточной технологии обеспечивает совместное использование логическими процессами кэша данных первого уровня. Если два виртуальных адреса находятся в строках кэша, попадающих в один 64-килобайтный сегмент, это приведет к конфликту в строке кэша данных первого уровня. Этот конфликт наложения может оказывать влияние как на производительность кэша данных первого уровня, так и на блок предсказания ветвлений. Этот эффект особенно опасен для приложений, которые создают много потоков для выполнения одной операции над разными данными.
Разделение работы на задачи меньшего размера, которые выполняют идентичные операции, часто называют декомпозицией домена данных. В операционных системах Microsoft Windows потоки создаются на кратных мегабайту границах.
Потоки, выполняющие сходные задачи и использующие локальные переменные в собственных стеках, сталкиваются с проблемой наложения, в результате чего общая производительность приложения заметно снижается. Во избежание снижения производительности используйте функцию __alloca() для изменения начального адреса стека на некоторую величину. Применение функции __alloca() повышает общую производительность приложений при выполнении на процессорах Intel Xeon, использующих гиперпоточную технологию.
Эффективное использование разбиения кэш-памяти данных – это один из многих факторов, влияющих на производительность кэша. Хорошо известный метод разбиения кэша данных на блоки помогает использовать преимущество локализации кэша данных. Для использования этого метода следует изменить структуру циклов с частыми итераций по большим массивам данных, разделяя большие массивы на небольшие блоки или сегменты, соответствующие размеру кэша данных. Каждый элемент массива повторно используется в пределах блока данных перед переходом к следующему блоку или сегменту.
Метод разбиения кэша данных на блоки может быть весьма эффективным, что, впрочем, зависит от приложения. Этот метод часто используется в вычислительной линейной алгебре и является общим преобразованием. Его могут применять как разработчики приложений, так и компилятор. Поскольку единый кэш второго уровня содержит как команды, так и данные, компиляторы часто пытаются использовать разбиение команд путем группировки связанных блоков команд, которые находятся вблизи друг от друга. Типичными приложениями, извлекающими выгоду из объединения данных в кэше в блоки, являются приложения обработки изображений или видеосигнала, где возможна обработка части изображения или видеокадра. Однако эффективность этого метода в значительной степени зависит от размера блока, размера кэша процессора и числа повторных обращений к данным.
При использовании гиперпоточной технологии кэш совместно используется логическими процессорами, поэтому соотношение между размером блока и размером кэша также сохраняется. Алгоритмы разбиения кэша на блоки должны учитывать этот фактор. Если физический процессор включает два логических процессора, то при разбиении кэша на блоки необходимо предположить, что только половина кэша доступна для использования логическим процессором.
Размер кэша можно определить с помощью команды CPUID, а затем динамически настроить размер сегмента для разбиения кэша на блоки с целью получения максимальной производительности для разных моделей процессоров. Обратите внимание на то, что необходимо установить такой минимальный размер блока, чтобы затраты системных ресурсов на обеспечение многопоточности и синхронизации не свели бы на нет преимущества от распараллеливания. Общее правило – размер блока кэша должен быть равен примерно 1/2 – 3/4 размера физического кэша для процессора, не использующего гиперпоточную технологию и 1/4 – 1/2 размера физического кэша для процессора с гиперпоточной технологией, поддерживающего два логических процессора. Однако размер блока должен выбираться с учетом производительности приложения.
С помощью мастера настройки Intel Tuning Assistant, включенного в состав анализатора Vtune, можно выявлять множество проблем приложений, связанных с гиперпоточной технологией.
Для создания нового проекта, или Activity (действия), а также чтобы сконфигурировать сбор данных о событиях процессора, следуйте указаниям, приведенным в разделе "Configuring for EBS Data Collection" (Настройка конфигурации сбора данных EBS) файла интерактивной справки анализатора VTune. Сконцентрируйте внимание на событиях, сильнее всего влияющих на производительность при гиперпоточной технологии.
После запуска Activity Tuning Assistant анализирует выборку событий, предлагает свое толкование этих событий, а также советы по оптимизации производительности и устранению проблем (см. рисунок 34).
Tuning Assistant предоставляет свои предположения в отношении того, какие счетчики могут указывать на проблему с производительностью. Используйте эту информацию, чтобы понять, как нужно оптимизировать исходный код для наиболее существенного улучшения производительности.
Рис. 34. Пример копии экрана с советами мастера настройки Intel.
| Оценка 481
[+1/-0]
Оценить
|
