 Оценка 550
Оценка 550 
 Оценить
Оценить 





| Оценка 550 Оценить
|
Исходные тексты
Сравнение segmented_list, std::list, std::deque и std::vector
Несколько лет назад мне пришлось писать текстовый редактор. Подогнать RichEdit под требования не получалось, и пришлось делать свой компонент для работы с текстом. Для манипуляции строками в компоненте нужно было реализовывать класс TextFile с примерно таким интерфейсом:
class TextFile
{
public:
class TextLineIterator
{
const std::string& getText() const;
int getLineIdx() const;
int getFirstCharPos() const;
TextLineIterator& operator++();
TextLineIterator& operator--();
booloperator < (const TextLineIterator &it) const;
booloperator == (const TextLineIterator &it) const;
};
public:
int linesCount () const;
int charsCount () const;
void insertTextLine (int lineIdx, const std::string &content);
void eraseTextLine (int lineIdx);
TextLineIterator textLineFromCharPos (int charPos);
TextLineIterator getTextLine (int lineIdx);
};
|
Первая версия TextFile была основана на std::vector:
class TextFile
{
struct TextLine
{
std::string text;
int firstCharPos;
booloperator < (int charPos)
{
return (this->firstCharPos < charPos);
}
};
typedef std::vector<TextLine> Lines;
Lines lines_;
public:
class TextLineIterator
{
Lines::iterator data_;
int lineIdx_;
friend TextFile;
TextLineIterator(Lines::iterator data, int lineIdx)
{
data_ = data;
lineIdx_ = lineIdx;
}
public:
const std::string& getText() const { return data_->text; }
int getLineIdx() const { return lineIdx_; }
int getFirstCharPos() const { return data_->firstCharPos; }
TextLineIterator& operator++()
{
++data_;
++lineIdx_;
return *this;
}
TextLineIterator& operator--()
{
--data_;
--lineIdx_;
return *this;
}
booloperator < (const TextLineIterator &it) const
{
return (lineIdx_ < it.lineIdx_);
}
booloperator == (const TextLineIterator &it) const
{
return (data_ == it.data_);
}
};
friendclass TextLineIterator;
public:
int linesCount() const { return lines_.size(); }
int charsCount() const
{
return (lines_.size()
? lines_.back().firstCharPos + lines_.back().text.size() : 0);
}
void insertTextLine(TextLineIterator it, const std::string &textLine)
{
TextLine tl;
tl.text = textLine;
tl.firstCharPos =
(it.lineIdx_ == linesCount() ? charsCount() : it.data_->firstCharPos);
for(Lines::iterator lit = it.data_; lit != lines_.end(); ++lit)
lit->firstCharPos += textLine.size();
lines_.insert(it.data_, tl);
}
void eraseTextLine(TextLineIterator it)
{
int diff = it.getText().size();
for(Lines::iterator lit = it.data_; lit != lines_.end(); ++lit)
lit->firstCharPos -= diff;
lines_.erase(it.data_);
}
TextLineIterator textLineFromCharPos(int charPos)
{
Lines::iterator it = std::lower_bound(
lines_.begin(), lines_.end(), charPos);
return TextLineIterator(
it,
std::distance(
lines_.begin(),
((it->firstCharPos != charPos) ? --it : it)));
}
TextLineIterator getTextLine(int lineIdx)
{
return TextLineIterator(lines_.begin() + lineIdx, lineIdx);
}
};
|
Из приведенного кода видно, что операции получения строки по индексу (getTextLine) и определения строки, которой принадлежит символ в заданной позиции (textLineFromCharPos), выполняются за время порядка O(1) и O(log N) соответственно. С другой стороны, вставка (insertTextLine) и удаление (eraseTextLine) строк реализованы неэффективно. Во-первых, вставка/удаление элемента в std::vector в произвольное место имеет сложность порядка O(N), а во-вторых, при вставке/удалении строки приходится пересчитывать позиции символов, с которых начинаются все строки, следующие за вставленной/удаленной строкой.
Чтобы избавиться от недостатков, связанных с использованием std::vector, TextFile был переделан на std::list:
class TextFile
{
typedef std::list<std::string> Lines;
Lines lines_;
int charsCount_;
public:
class TextLineIterator
{
Lines::iterator data_;
int lineIdx_;
int lineFirstCharPos_;
friend TextFile;
TextLineIterator(Lines::iterator data, int lineIdx, int lineFirstCharPos)
{
data_ = data;
lineIdx_ = lineIdx;
lineFirstCharPos_ = lineFirstCharPos;
}
public:
const std::string& getText() const { return *data_; }
int getLineIdx() const { return lineIdx_; }
int getFirstCharPos() const { return lineFirstCharPos_; }
TextLineIterator& operator++()
{
lineFirstCharPos_ += data_->size();
++data_;
++lineIdx_;
return *this;
}
TextLineIterator& operator--()
{
--data_;
--lineIdx_;
lineFirstCharPos_ -= data_->size();
return *this;
}
booloperator < (const TextLineIterator &it) const
{
return (lineIdx_ < it.lineIdx_);
}
booloperator == (const TextLineIterator &it) const
{
return (data_ == it.data_);
}
};
friendclass TextLineIterator;
public:
TextFile(): charsCount_(0) {}
int linesCount() const { return lines_.size(); }
int charsCount() const { return charsCount_; }
void insertTextLine(TextLineIterator it, const std::string &textLine)
{
charsCount_ += textLine.size();
lines_.insert(it.data_, textLine);
}
void eraseTextLine(TextLineIterator it)
{
charsCount_ -= it.data_->size();
lines_.erase(it.data_);
}
TextLineIterator textLineFromCharPos(int charPos)
{
TextLineIterator res(lines_.begin(), 0, 0);
while(charPos >= res.getFirstCharPos())
++res;
return --res;
}
TextLineIterator getTextLine(int lineIdx)
{
TextLineIterator res(lines_.begin(), 0, 0);
while(lineIdx != res.getLineIdx())
++res;
return res;
}
};
|
В результате использования std::list время выполнения insertTextLine/eraseTextLine улучшилось и стало иметь порядок O(1), но зато время выполнения getTextLine/textLineFromCharPos ухудшилось и стало порядка O(N). Таким образом, используя стандартные структуры данных (двухсвязный список или динамический массив), реализовать все методы класса TextFile одинаково эффективно не получается. Другими словами, нет такого STL-контейнера, который бы удовлетворял следующим требованиям:
| ПРИМЕЧАНИЕ “Порядок, близкий к O(1)” означает, что время выполнения операции не должно зависеть от числа элементов в контейнере, либо зависимость должна быть слабой, например O(log N). |
Ниже описан контейнер на основе двухсвязного списка, удовлетворяющего всем указанным выше требования.
std::list, как реализация структуры данных "двухсвязный список", позволяет эффективно, т.е. за фиксированное время, не зависящее от размера последовательности, вставлять и удалять элементы. С другой стороны, обращение к произвольному элементу списка по индексу требует времени, пропорционального его положению в списке. Не прибегая к каким-то ухищрениям, обращение к произвольному элементу списка можно реализовать так:
template <class T> std::list<T>::iterator at(int idx, std::list<T> &ctnr)
{
if(idx <= (ctnr.size() / 2))
{
std::list<T>::iterator it = ctnr.begin();
for(int i = idx; i; --i)
++it;
return it;
}
std::list<T>::reverse_iterator it = ctnr.rbegin();
for(int i = ctnr.size() - idx; i; --i)
++it;
return it.base();
}
|
Необходимость перебора min(i – 1, N – i – 1) элементов, где N – размер списка, для получения доступа к i-ому, является платой за эффективность операций вставки/удаления, и от этого недостатка избавиться нельзя. Однако для списка небольшого размера это не является большой проблемой. Отталкиваясь от этого утверждения, положим, что время обращения к произвольному элементу списка размером K является приемлемым. Используя такой подход, список размером больше K, разделим на сегменты по K элементов. После того, как список разделен на сегменты, обращение к элементу списка по индексу будет производиться так:
На рисунке 1 показан список из 10 элементов (тип элементов значения не имеет) разделенный на три сегмента: в два первых попадает по 4 элемента (K=4), в третий оставшиеся 2. Пунктирные стрелки указывают на элементы списка, первыми попадающие в тот или иной сегмент.
| ПРИМЕЧАНИЕ На практике размер сегментов (K) должен быть порядка 100-1000, так что разделение небольших списков на сегменты неэффективно. |
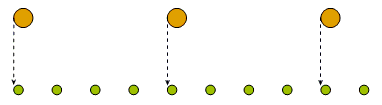
Рисунок 1. Разделение списка на сегменты.
Сегмент можно представить в виде следующей C++-структуры:
template <class T>
struct segment
{
std::list<T>::iterator element;
std::list<T>::size_type position;
std::list<T>::size_type size;
};
|
element – итератор, адресующий элемент списка, с которого начинается сегмент, position – индекс элемента списка, с которого начинается сегмент, size – количество элементов списка, попадающих в сегмент.
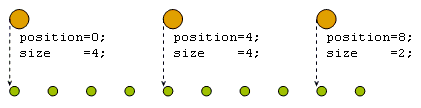
Рисунок 2. Значения сегментов.
На рисунке 2 изображены сегменты с установленными значениями полей position и size.
Количество элементов в списке может меняться. Это должно отражаться на структуре сегментов, т.е. приводить к изменению их размеров, положений и/или количества. Чтобы определить, что делать при вставке/удалении элементов, можно ввести понятия минимального (min_size), максимального (max_size) и нормального (norm_size) размера сегмента. При этом должно быть верно, что 1 <= min_size <= norm_size <= max_size.
Если вставка элемента в список приводит к тому, что размер соответствующего сегмента становится больше max_size, то сегмент разбивается на сегменты размером norm_size. При этом последний созданный сегмент может быть меньшего размера, но не меньше min_size (рисунок 3).
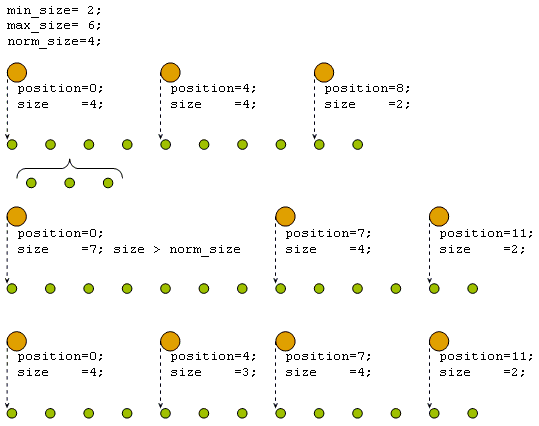
Рисунок 3. Увеличение количества сегментов при вставке элементов в список.
Если при удалении элемента из списка размер соответствующего сегмента становится меньше min_size, сегмент объединяется с соседним (рисунок 4).
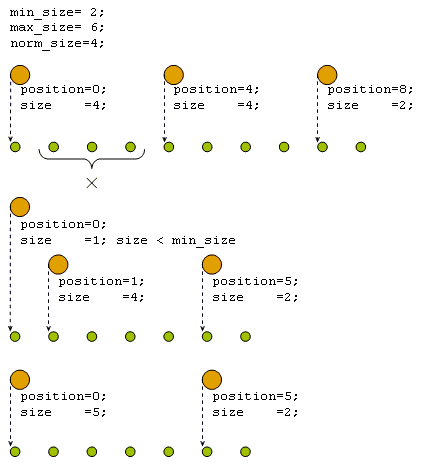
Рисунок 4. Уменьшение количества сегментов при удалении элементов из списка.
Для эффективной работы механизма обращения к произвольному элементу списка с использованием сегментов необходимо реализовать быстрый поиск сегментов. Для этого подойдет бинарный поиск, т.к. сегменты отсортированы по позициям. Остается определить, какой контейнер использовать для хранения сегментов. Перед тем, как перейти к этому этапу, следует обратить внимание на то, что изменение размера/положения одного сегмента влечет пересчет позиций (position) всех последующих сегментов. Это серьезный недостаток, но его можно устранить, если убрать из структуры segment поле position. В таком случае позиция сегмента рассчитывается путем сложения размеров всех предшествующих ему сегментов (рисунок 5).
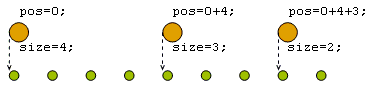
Рисунок 5. Вычисление позиций сегментов по размерам предшествующих сегментов.
Удаление из структуры segment поля position приведет к тому, что станет невозможно использовать бинарный поиск, т.к. для определения позиции искомого сегмента придется перебирать всех его предшественников. Чтобы разрешить это противоречие, можно хранить сегменты в дереве двоичного поиска.
Для этого структуру segment следует изменить так:
template <class T>
struct segment
{
segment *left;
segment *right;
segment *parent;
std::list<T>::iterator element;
std::list<T>::size_type size;
std::list<T>::size_type offset;
};
|
offset – смещение сегмента относительно позиции сегмента, расположенного в родительском узле дерева. Рисунок 6 иллюстрирует преобразование линейной последовательности сегментов в древовидную структуру и расчет значений offset. Для простоты список, с которым ассоциированы сегменты, на рисунке 6 не показан.
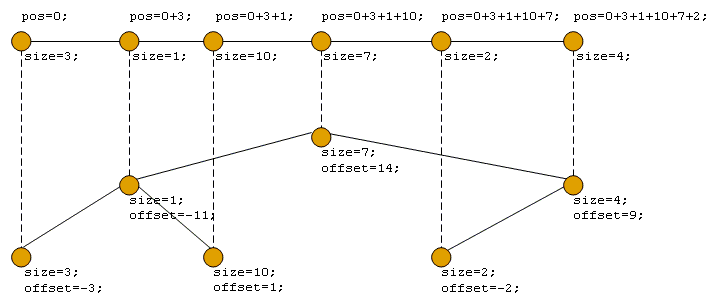
Рисунок 6. Размещение сегментов в дереве двоичного поиска.
| ПРИМЕЧАНИЕ Значение offset сегмента, расположенного в корне дерева, равно абсолютной позиции этого сегмента в линейной последовательности сегментов. |
Функция для поиска сегмента в таком дереве выглядит следующим образом:
template <class T>
class segmented_list : public std::list<T>
{
typedef segment<T> seg;
seg *root;
seg* find(size_type idx, size_type &segment_pos) const
{
seg* s = root;
seg* cp = 0;
size_type cp_pos = root->offset;
segment_pos = root->offset;
while(1)
{
if(idx > segment_pos)
{
if(!s->right)
return s;
cp = s;
cp_pos = pos;
s = s->right;
}
elseif(idx < segment_pos)
{
if(!s->left)
{
if(!cp)
return s;
segment_pos = cp_pos;
return cp;
}
s = s->left;
}
else
{
return s;
}
segment_pos += s->offset;
}
}
};
|
Функция find возвращает указатель на сегмент (узел дерева), которому принадлежит элемент списка с индексом idx. В segment_pos записывается позиция найденного сегмента, при этом segment_pos <= idx верно для idx >= 0, в противном случае segment_pos будет равен 0. Как видно из приведенного кода, find – типичная реализация поиска узла в дереве. В нее лишь добавлен расчет позиции сегмента. Функция find является вспомогательной. Окончательный вариант реализации operator [] для сегментированного списка выглядит так:
template <class T>
class segmented_list : public std::list<T>
{
typedef segment<T> seg;
seg* find(size_type idx, size_type &segment_pos);
public:
const_reference operator [] (size_type idx) const
{
size_type segment_pos;
const_iterator res = find(idx, segment_pos)->element;
for(idx -= segment_pos; idx >= 0; --idx)
++res;
return *res;
}
};
|
Из-за хранения сегментов в иерархической структуре (дереве) несколько усложняется переход к следующему/предыдущему сегменту из текущего сегмента по сравнению с хранением сегментов в линейной структуре, например, векторе.
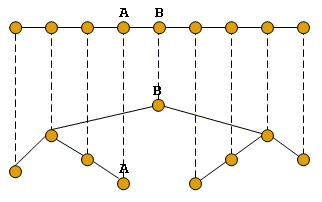
Рис 7. "Соседство" сегментов в линейной и иерархической структурах
На рисунке 7 изображена линейная последовательность сегментов и соответствующая ей иерархическая структура. Видно, что два соседних сегмента A и B, будучи размещенными в дереве, перестают быть "соседями". Для итерации по сегментам в структуру segment добавлены функции получения следующего/предшествующего сегмента. Код функций приведен ниже.
template <class T>
struct segment
{
...
segment* next()
{
segment* s = this->right;
if(s)
{
while(s->left)
s = s->left;
return s;
}
segment* t = this;
do
{
s = t;
t = t->parent;
}
while(t && (s == t->right));
return t;
}
segment* prev()
{
segment* s = this->left;
if(s)
{
while(s->right)
s = s->right;
return s;
}
segment* t = this;
do
{
s = t;
t = t->parent;
}
while(t && (s == t->left));
return t;
}
};
|
| ПРИМЕЧАНИЕ Хотя функции next и prev не используются в реализации operator [], тем не менее, они необходимы для реализации вставки/удаления сегментов и некоторых других операций. |
Как уже было сказано выше, поиск элемента по индексу в списке, разделенном на сегменты, заключается в поиске подходящего сегмента в дереве сегментов и переборе элементов списка, начиная с элемента списка, первым попадающего в найденный сегмент, и заканчивая искомым.
Время поиска сегмента (узла) в дереве двоичного поиска имеет в среднем порядок O(log N), где N - количество узлов в дереве. Время перебора элементов в сегменте в худшем случае не больше времени перебора max_size элементов списка.
Таким образом, в худшем случае для поиска элемента в сегментированном списке будет затрачено время, необходимое для обхода log N узлов дерева и перебора max_size элементов списка.
Для простого списка операции вставки/удаления элемента выполняются за фиксированное время независимо от размера списка. Поскольку при изменении состава сегментированного списка необходимо обновлять структуру сегментов, то время выполнения этих операций возрастает по сравнению со списком без сегментов. В худшем случае вставка/удаление элемента в сегментированный список может привести к необходимости вставить/удалить сегмент (узел) в дерево сегментов. Время выполнения операций вставки/удаления узла в дерево двоичного поиска имеет порядок O(log N), где N – количество узлов в дереве.
Таким образом, разница во времени выполнения операций вставки/удаления элемента в сегментированный и обычный список имеет порядок O(log N).
По большому счету, реализация сегментированного списка свелась к реализации дерева сегментов. Однако вместо простого дерева двоичного поиска для хранения сегментов было реализовано АВЛ-дерево с тем, чтобы вставка/удаление узлов не нарушали его балансировку.
Объявление класса дерева сегментов выглядит следующим образом:
template <
class ValueType,
class AllocatorType = std::allocator<hopper_node<ValueType> >
> class hopper;
|
ValueType – тип элемента, хранимого в узле дерева, hopper_node<ValueType> – тип узла дерева, другими словами, hopper_node<ValueType> – это тип сегмента, адаптированного для хранения в АВЛ-дереве. Объявление hopper_node показано ниже.
template <class ValueType>
struct hopper_node
{
typedef ValueType value_type;
typedeftypename value_type::size_type size_type;
hopper_node* l;
hopper_node* r;
hopper_node* p;
value_type val;
size_type size;
size_type height; // специфика АВЛ-дерева
hopper_node* imbalanced_child() const// специфика АВЛ-дереваvoid set_height(); // специфика АВЛ-дерева
hopper_node* next();
hopper_node* prev();
};
|
| ПРИМЕЧАНИЕ Типы hopper и hopper_node определены в файле hopper.h. |
Пользовательский тип ValueType должен инкапсулировать итератор списка и позицию элемента, адресуемого итератором, в списке. Условно ValueType можно описать так:
template <class T>
class iterator_with_position
{
public:
typedeftypename std::list<T>::iterator value_type;
typedeftypename std::list<T>::size_type size_type;
protected:
value_type val_;
size_type pos_;
public:
size_type get_pos() const { return pos _; }
void set_pos(size_type pos) { pos _ = pos; }
const value_type& get_val() const { return val_; }
iterator_with_position& operator++()
{
++pos_;
++val_;
return *this;
}
iterator_with_position& operator--()
{
--pos_;
--val_;
return *this;
}
booloperator < (const iterator_with_position &n) const
{
return idx_ < (n.pos_);
}
booloperator == (const iterator_with_position &n) const
{
return (val_ == n.pos_);
}
};
|
| ПРИМЕЧАНИЕ В файле hopper_node.h определены две класса node_trivial и node_sized с интерфейсом соответствующим требованиям к типу ValueType. |
Для итерации по элементам сегментированного списка в классе hopper определены два типа итераторов: iterator и const_iterator. Класс const_iterator представляет собой просто обертку над объектом типа ValueType. Класс iterator также “оборачивает” объект типа ValueType, но дополнительно содержит указатель на сегмент, в который попадает элемент списка, адресуемый итератором, инкапсулированным в объекте типа ValueType. Для получения первого и следующего за последним элементов сегментированного списка в классе hopper определены функции begin и end соответственно.
template <
class ValueType,
class AllocatorType = std::allocator<hopper_node<ValueType> >
>
class hopper
{
public:
iterator begin();
const_iterator begin() const;
iterator end();
const_iterator end() const;
...
};
|
Пример использования итераторов класса hopper:
typedef std::list<int> ctnr_type;
typedef hopper<node_trivial<ctnr_type> > hopper_type;
ctnr_type ctnr;
hopper_type hopper;
// распечатать содержимое ctnr, используя данные из hopper-а
print_from_hopper()
{
// заполнить ctnr и hopper
...
hopper_type::const_iterator b = hopper.begin();
hopper_type::const_iterator e = hopper.end();
printf("в списке %d элементов\n", e->get_pos());
for(; b != e; ++b)
printf("%d: %d\n", b->get_pos(), *b->get_val());
}
// распечатать содержимое ctnr, используя данные из ctnr-а
print_from_ctnr()
{
// заполнить ctnr и hopper
...
ctnr_type::const_iterator b = ctnr.begin();
ctnr_type::const_iterator e = ctnr.end();
printf("в списке %d элементов\n", ctnr.size());
for(int i = 0; b != e; ++b, ++i)
printf("%d: %d\n", i, *b);
}
|
Функции print_from_hopper и print_from_ctnr делают одно и то же, только разными способами.
Для поиска элементов в ассоциированном с деревом сегментов списке служит функция lower_bound:
template <
class ValueType,
class AllocatorType = std::allocator<hopper_node<ValueType> >
>
class hopper
{
public:
template<class Key> iterator lower_bound(const Key &key);
template<class Key> const_iterator lower_bound(const Key &key) const;
...
};
|
Тип Key – тип ключа, по которому производится поиск элемента. В классе hopper определена структура cmp_idx – тип ключа для поиска элемента списка по индексу. Ниже приведен пример использования функции lower_bound с ключом типа cmp_idx.
typedef std::list<int> ctnr_type;
typedef hopper<node_trivial<ctnr_type> > hopper_type;
typedeftypename hopper_type::cmp_idx cmp_idx;
ctnr_type ctnr;
hopper_type hopper;
// заполнить ctnr и hopper
...
// найти десятый элемент в ctnr, используя hopper
ctnr::iterator it = hopper.lower_bound(cmp_idx(10))->get_val();
// найти десятый элемент в ctnr без использования hopper-a
ctnr::iterator it = ctnr.begin();
for(int i = 0; i != 10; ++i)
++it;
|
| ПРИМЕЧАНИЕ Пример использования в lower_bound типа ключа, отличного от cmp_idx, приведен в файле TextFile.h. |
Для обновления дерева сегментов предназначены следующие функции:
template <
class ValueType,
class AllocatorType = std::allocator<hopper_node<ValueType> > >
class hopper
{
public:
typedef ValueType node_type; // не путать с hopper_node!
...
// f - итератор списка, адресующий первый вставленный в список элемент// it - итератор hopper-а, адресующий элемент списка, перед которым// были вставлены новые элементы// diff - количество вставленных в список элементов
iterator after_elems_inserted(
consttypename node_type::value_type& f,
iterator& it,
consttypename node_type::pos_type& diff);
// f - итератор списка, адресующий элемент списка следующий // за последним удаленным элементом списка// it - итератор hopper-а, адресующий элемент списка, начиная // с которого были удалены элементы из списка// diff - количество удаленных из списка элементов void after_elems_erased(
consttypename node_type::value_type& f,
iterator& it,
consttypename node_type::pos_type& diff);
};
|
after_elems_inserted должна вызываться каждый раз после вставки, а after_elems_erased – после удаления элемента(ов) в ассоциированный с деревом сегментов список.
Для удобства дерево сегментов и ассоциированный с ним список целесообразно инкапсулировать в одном классе – segmented_list. Ниже приведен фрагмент кода класса segmented_list.
template <class T> class segmented_list
{
typedef std::list<T> ctnr_type;
typedef node_trivial<ctnr_type> node_type;
typedef hopper<node_type> hopper_type;
typedeftypename hopper_type::cmp_idx cmp_idx;
public:
typedeftypename hopper_type::iterator iterator;
typedeftypename hopper_type::const_iterator const_iterator;
typedeftypename hopper_type::policy_type policy_type;
typedeftypename ctnr_type::size_type size_type;
private:
ctnr_type ctnr_;
hopper_type hopper_;
public:
segmented_list(): ctnr_(), hopper_(node_type(ctnr_.begin(), 0))
{
// произвольные значения, просто чтобы более-менее // разумно инициализировать policy
policy_type p;
p.min_size = 100;
p.max_size = 500;
p.normal_size = 200;
set_policy(p);
}
size_type size() const { return ctnr_.size(); }
const policy_type& get_policy() const
{
return hopper_.get_policy();
}
void set_policy(const policy_type &p)
{
hopper_.set_policy(p);
}
iterator begin() { return hopper_.begin(); }
iterator end() { return hopper_.end(); }
iterator at(size_type idx) { return hopper_.lower_bound(cmp_idx(idx)); }
iterator insert(iterator it, const T& v)
{
return hopper_.after_elems_inserted(
ctnr_.insert(it->get_val(), v), it, 1);
}
iterator erase(iterator it)
{
hopper_.after_elems_erased(ctnr_.erase(it->get_val()), it, 1);
return it;
}
const T& operator [] (size_type idx) const
{
return *(at(idx)->get_val());
}
};
|
| ПРИМЕЧАНИЕ Класс segmeneted_list определен в файле segmeneted_list.h. |
Для сравнения были измерены следующие параметры:
Для тестирования segmented_list инициализировался так:
segmented_list<int> ctnr; segmented_list<int>::policy_type p; p.min_size = 100; p.max_size = 1000; p.normal_size = 500; ctnr.set_policy(p); |
| ПРИМЕЧАНИЕ Исходный код приложения, использованного для измерений, находится в файле hopper_cmp_performance.cpp. Полный цикл измерений реализован в скрипте performance_test.sh. Об использовании performance_test.sh написано в файле README (раздел “Performance testing”). |
Измерения делались на сервере 4xIntel Xeon 2.60GHz, 512KB cache, 2GB ОЗУ под управлением Red Hat Linux 7.3 (kernel 2.4.20-24.7smp).
Далее представлены выборки из результатов измерений.
| ПРИМЕЧАНИЕ В файле performance_test_results.zip находится полный отчет о результатах измерений. |
| Обозначение | Расшифровка |
|---|---|
| vector | std::vector<int> |
| rvector | std::vector<int>, с предварительным резервированием места для N элементов |
| deque | std::deque<int> |
| List | std::list<int> |
| slist | segmented_list<int> |
| N | vector | rvector | deque | list | slist |
|---|---|---|---|---|---|
| 1000 | 0,771 | 0,724 | 0,059 | 0,07 | 0,217 |
| 10000 | 58,419 | 58,248 | 0,525 | 0,615 | 2,298 |
| 100000 | 7729,65 | 8158,162 | 5,292 | 6,193 | 24,835 |
| 1000000 | - | - | - | 65,164 | 257,186 |
| 10000000 | - | - | - | 653,69 | 2698,554 |
| N | vector | rvector | deque | list | slist |
|---|---|---|---|---|---|
| 1000 | 0,063 | 0,012 | 0,066 | 0,068 | 0,221 |
| 10000 | 0,316 | 0,131 | 0,578 | 0,599 | 2,405 |
| 100000 | 2,445 | 1,413 | 5,772 | 6,065 | 28,481 |
| 1000000 | - | - | - | 63,704 | 278,206 |
| 10000000 | - | - | - | 689,09 | 3044,451 |
| N | vector | rvector | deque | list | slist |
|---|---|---|---|---|---|
| 1000 | 0,509 | 0,464 | 1,322 | 0,064 | 0,213 |
| 10000 | 30 | 29,862 | 114,283 | 0,566 | 2,469 |
| 100000 | 2881,076 | 2840,101 | 11457,18 | 5,363 | 28,096 |
| 1000000 | - | - | - | 56,571 | 319,957 |
| 10000000 | - | - | - | 554,954 | 3613,337 |
| N | vector | rvector | deque | list | slist |
|---|---|---|---|---|---|
| 1000 | 0,566 | 0,518 | 0,889 | 0,677 | 1,53 |
| 10000 | 30,595 | 30,442 | 66,669 | 93,938 | 31,683 |
| 100000 | 3322,684 | 3407,135 | 6653,3 | 112233,1 | 2439,051 |
| 1000000 | - | - | - | - | 56182,85 |
| 10000000 | - | - | - | - | - |
| N | list | slist |
|---|---|---|
| 1000 | 0,002 | 0,002 |
| 10000 | 0,013 | 0,001 |
| 100000 | 0,404 | 0,002 |
| 1000000 | 4,719 | 0,008 |
| 10000000 | 47,312 | 0,008 |
Время доступа к N/2-у элементу последовательности (мс)
Примером использования segmented_list может служить реализация на его основе класса TextFile, описанного в начале статьи:
class TextFile
{
typedef std::list<std::string> ctnr_type;
typedef node_sized<
ctnr_type,
meter<ctnr_type::value_type, ctnr_type::size_type>,
ctnr_type::size_type
> node_type;
typedef node_type::pos_type pos_type;
typedef hopper<node_type> hopper_type;
ctnr_type lines_;
hopper_type hopper_;
typedef hopper_type::cmp_idx cmp_idx;
class cmp_char_idx
{
node_type::size_type key_;
public:
cmp_char_idx(node_type::size_type key) : key_(key)
{
}
booloperator < (const pos_type& v) const
{
return (key_ < v.offset);
}
booloperator > (const pos_type& v) const
{
return (key_ > v.offset);
}
};
public:
class TextLineIterator
{
hopper_type::iterator data_;
friend TextFile;
TextLineIterator(hopper_type::iterator data): data_(data) {}
public:
const std::string& getText() const { return *data_->get_val(); }
int getLineIdx() const { return data_->get_pos().idx; }
int getFirstCharPos() const { return data_->get_pos().offset; }
TextLineIterator& operator++()
{
++data_;
return *this;
}
TextLineIterator& operator--()
{
--data_;
return *this;
}
booloperator < (const TextLineIterator &it) const
{
return (data_->idx() < it.data_->idx());
}
booloperator == (const TextLineIterator &it) const
{
return (data_ == it.data_);
}
};
friendclass TextLineIterator;
public:
TextFile(): lines_(), hopper_(node_type(lines_.begin(), pos_type(0, 0)))
{
hopper_type::policy_type p;
p.min_size = 100;
p.max_size = 500;
p.normal_size = 200;
hopper_.set_policy(p);
}
int linesCount() const { return lines_.size(); }
int charsCount() const { return hopper_.end()->get_pos().offset; }
void insertTextLine(TextLineIterator it, const std::string &textLine)
{
hopper_.after_elems_inserted(
lines_.insert(it.data_->get_val(), textLine),
it.data_,
pos_type(1, textLine.size()));
}
void eraseTextLine(TextLineIterator it)
{
pos_type diff(1, it.getText().size());
hopper_.after_elems_erased(
lines_.erase(it.data_->get_val()), it.data_, diff);
}
TextLineIterator textLineFromCharPos(int charPos)
{
TextLineIterator res(hopper_.lower_bound(cmp_char_idx(charPos)));
return (charPos != res.getFirstCharPos()) ? --res : res;
}
TextLineIterator getTextLine(int lineIdx)
{
return TextLineIterator(hopper_.lower_bound(cmp_idx(lineIdx)));
}
};
|
Данная реализация обеспечивает выполнение функций insertTextLine, eraseTextLine, getTextLine и textLineFromCharPos за время, практически не зависящее от количества хранимых строк. Следует учесть, что использовать segmented_list вместо стандартных контейнеров имеет смысл только для манипуляции достаточно большими последовательностями.
| ПРИМЕЧАНИЕ Все три версии реализации класса TextFile приведены в файле TextFile.h |
Все приложения тестирования и сравнения производительности собираются под g++ 2.96 и MS VC 6.0. Соответствующие Makefile/dsp+dsw файлы находятся в каталоге test/build.
Автор выражает благодарность Евгению Долгову, Владимиру Дюжеву (http://dozen.ru), Сергею Габдурахманову и Дмитрию Робустову за критику и советы, благодаря которым статья стала лучше.
| Оценка 550 Оценить
|
