 Оценка 40
Оценка 40 
 Оценить
Оценить 





| Оценка 40 Оценить
|
| Введение Терминология, условные обозначения и структуры данных. Правила разрешения конфликта версий. Заключение. Литература |  |
Иногда керосиновый ветер дул с запада, иногда с востока, а иной раз это был северный керосиновый ветер или, может быть, южный, но, прилетал ли он из снежной Арктики, или зарождался в песках пустыни, он всегда достигал нас, насыщенный ароматом керосина. Джером К.Джером. Трое в одной лодке, не считая собаки.
Репликация. Это слово чрезвычайно часто мелькает в темах форумов. Этому термину отведены солидные разделы в руководствах по эксплуатации серверов баз данных (пример — MSDN). Этой теме посвящают статьи и даже диссертации. Казалось бы, все давно известно. Но вот читаешь MSDN к MS SQL 2008 и видишь такие статьи, как: «Пользовательские арбитры на основе технологии COM» [1], «Как реализовать нестандартный арбитр конфликтов на основе хранимых процедур для статьи публикации слиянием» [2]. Потом встречаешь какой-нибудь обзор, например [3]. И, наконец, какой-нибудь коллега просит помощи идеями на форуме. И из описания задачи понимаешь, что коллеге надо реплицировать БД.
Репликация сама по себе — процесс, состоящий из множества этапов. Описывать все их в рамках одной небольшой статьи не имеет смысла. Но при всякой синхронизации данных приходится решать вопрос о том, что делать, если запись об одном и том же объекте предметной области отражена в нескольких БД и хотя бы в одной из них была модифицирована или удалена.
В качестве пояснения приведу пример. Предположим, я внес запись о контрагенте в базу, расположенную на моем компьютере. Затем я реплицировал эту информацию в базу на компьютере коллеги. Коллега внес какие-то изменения в полученную информацию. Возникает вопрос: чья база хранит более правильную информацию о контрагенте? Для того, чтобы можно было решить вопрос технически сразу оговоримся: правило, которое будет давать ответ на этот вопрос не «понимает» смысла данных. Учитывая это, вопрос несколько меняет свою формулировку: «Чья база хранит версию информации о контрагенте, актуальность которой подтверждена формальными параметрами?». В такой постановке разрешение вопроса возможно технически. Каждой записи БД необходимо сопоставить некий идентификатор версии, при репликации сравнивать эти идентификаторы и из результатов сравнения делать вывод о том, какая из записей более актуальна.
Материал этой статьи предназначен в первую очередь тем, кто решил изготовить собственную систему репликации БД. Однако и те из коллег, кому потребовалось создать свой собственный, нестандартный арбитр конфликтов (терминология MSDN), уверен, найдут в ней интересный для себя материал.
Прежде всего, определимся с видом репликации, для которой будем рассматривать алгоритм разрешения конфликтов записей БД. Для этого воспользуемся классификацией, приведенной в [4,5]. Исходя из нее, репликация будет многосторонней, асинхронной, по текущему состоянию, с неопределенным способом передачи информации во время процесса репликации. Иными словами, не будем ограничивать число БД, подвергающихся репликации. Репликация измененной записи будет производится гораздо позже самого изменения. Способ, которым БД будут обмениваться данными рассматривать не будем.
Каков бы ни был алгоритм разрешения конфликта версий, его надо применять к определенным данным. Эти данные, в свою очередь, хранятся в таблицах, структуры которых обладают определенными свойствами. Рассмотрим эти свойства и введем необходимое количество условных обозначений.
Любая запись в таблице может находиться только в одном из четырех состояний с момента последней успешной репликации:
Обратим внимание на п. 4. Он будет существенен только в случае, если запись была внесена в таблицу, реплицирована, а затем удалена. Если удаление произошло до репликации, то можно считать, что записи не существовало вовсе. Придание записи статуса «удалена» еще не является для нее «смертным приговором». Теоретически, каждая запись в рассматриваемой нами системе может быть удалена, а затем восстановлена, затем вновь удалена и вновь восстановлена. Этот процесс может продолжаться бесконечно.
Структура таблиц должна быть такова, чтобы можно было однозначно распознать любое из приведенных выше состояний для каждой записи. Количество вариантов структур, которые обладают необходимыми свойствами, достаточно велико. Не будем описывать их все. Вместо этого остановимся на одной структуре, которая схематично выглядит так:
Table1(PK, Data, RK, Ver_Stamp),
где PK — первичный ключ таблицы, простой или составной, естественный или искусственный. Data — данные, которые хранит таблица. Смысл и назначение оставшихся 2-х элементов поясним более подробно.
Прежде всего, необходимо иметь некий идентификатор, который был бы одинаков для определенной записи во всех таблицах, между которыми она переносится. Назовем его RK — репликационный ключ. При первом внесении запись получает свое собственное значение RK и сохраняет его при репликации в другие таблицы. Репликационный ключ, также как и первичный, может быть естественным и искусственным, простым или составным, может вычисляться из первичного ключа (например, с помощью некоторой функции сериализации), либо от него не зависеть. Есть и еще одна особенность. Код, исполняющий репликацию данных, ОБЯЗАН поддерживать уникальность RK.
| ПРИМЕЧАНИЕ В действительности, дублирование значения RK приведет к неоднозначности информации о записи. К примеру, придется решать вопросы относительно какой из записей определять версию, а также какую из записей, содержащую устаревшую версию данных, следует модифицировать или удалить. В качестве частичной меры обеспечения этого условия можно объединить поля RK в уникальный индекс. Но этот путь не является предпочтительным, потому что целью должна является работа приложения без сбоев, а не анализ ошибок, возникших во время исполнения. |
Идея репликационного ключа не является новой. Например, в [4] приводит три варианта его практической реализации. Тем не менее, все они являются развитием одной и той же идеи: для того, чтобы получить уникальный идентификатор для нескольких БД, нужно взять идентификатор, который будет уникален в пределах одной БД (например, PK) и выполнить его объединение с идентификатором самой БД (DBID). Если же настроить генерацию PK таким образом, чтобы у каждой таблицы был свой уникальный диапазон PK, то можно обойтись и без идентификатора базы.
Если мы используем DBID, то логично определить RK = {PK, DBID}, то есть репликационный ключ является объединением значения первичного ключа и идентификатора базы. Если идентификатор базы не используется, то RK может совпадать с первичным ключом. Не стоит также забывать, что в некоторых СБД можно использовать такой тип данных, как UNIQUEIDENTIFIER. Но, вне зависимости от технологических особенностей, самое главное, чтобы RK сохранял свои логические и функциональные свойства.
Теперь рассмотрим роль версии записи (Ver_Stamp). Структура ее должна быть такова, чтобы можно было однозначно ответить на 2 вопроса:
Для ответа на первый вопрос необходимо и достаточно использовать порядковую шкалу, поскольку для разрешения вопроса о старшинстве версий потребуется использовать операторы больше, меньше или равно. При этом эта шкала будет однонаправленной в сторону увеличения значения. В данном случае, для получения значений номера версии, идеально подходят так называемые генераторы, то есть функциональные объекты, из которых можно получать новые, отличные от прежних значения при условии, что каждое последующее значение будет больше предыдущего [6]. При этом требуется такой генератор, который бы не зависел не только от конкретной БД, но и от конкретного сервера. Он должен существовать отдельно и быть един для всех баз, между которыми выполняется перенос данных.
| ПРИМЕЧАНИЕ Это условие сразу делает непригодным использование типа timestamp в версии от MS SQL 2000 и старше. Штамп времени в этой версии дает необходимый нам результат только в пределах одной БД. Разные базы даже на одном сервере имеют разные экземпляры генераторов timestamp. Также под вопросом использование генераторов Interbase и Firebird. |
Генератор, обладающий такими свойствами, давно известен и активно используется в различных целях. Это всемирное либо поясное время, и отображать его значения можно с помощью типа datetime. В дальнейшем будем обозначать значение этого генератора как TransTime. Очевидно, что используя триггеры, можно легко организовать фиксацию любого момента изменения записи. Очень важно разделять значения TransTime от других полей, которые также имеют тип datetime. Несмотря на похожесть, эти поля хранят принципиально разную информацию. Например, в [7] существует отдельное понятие транзакционного (наш случай TransTime) и модельного времени, которые исполняют совершенно различные функции.
Ответ на второй из вопросов «Какого рода событие произошло с записью?» является значением некоторого перечислимого множества, и, следовательно, кодируется с помощью поля целочисленного типа, которое также обслуживает триггер. В дальнейшем обозначим его как ChType. Таким образом, можно сказать, что Ver_Stamp = {TransTime, ChType}, то есть штамп версии является объединением момента возникновения изменения и характеристики самого изменения.
| ПРИМЕЧАНИЕ При практическом применении этого типа данных datetime следует быть готовым к тому, что существует некоторая, чрезвычайно малая, но не нулевая вероятность совпадения значений атрибутов TransTime для записей с одинаковым RK из таблиц, находящихся в разных БД. Это происходит потому, что тип datetime имеет некоторую предельную точность. Например, в [8] указывается, что точность этого типа данных составляет «округлено до приращения 0,000, 0,003 или 0,007 секунд». Аналогичные ограничения существуют и для других серверов. Это обстоятельство не является препятствием для практического использования типа данных datetime, однако оно вносит коррективы в способ разрешения конфликтов записей. |
| ПРЕДУПРЕЖДЕНИЕ Также при практической эксплуатации следует следить за синхронностью системных часов серверов БД, участвующих в процессе репликации, а при нахождении в различных часовых поясах — приводить локальное время к времени эталонного часового пояса непосредственно перед запуском кода, разрешающего конфликт версий. Строго говоря, требование синхронности системного времени серверов БД не является жестким. При отложенной репликации допускается некоторая погрешность расхождения системного времени серверов. Однако, оценка величины этой погрешности выходит за рамки статьи. |
Приведенная выше схематичная структура таблицы данных не является единственным вариантом, с которым может работать способ разрешения конфликтов версий записей. Во-первых, таблица Table1 может является результатом работы некоторой преобразующей функции: представления, хранимой процедуры или функции, реализованной в клиентском приложении. Исходя из этого, данные в такую таблицу могут собираться из множества реальных таблиц БД. Во-вторых, информацию об изменениях, внесенных в Table1 можно получить и другими способами [3]. Например, можно использовать метод двойного копирования таблиц или метод обнаружения изменений при помощи журнала транзакций, либо применить метод обнаружения изменений при помощи контрольных таблиц. Вне зависимости от применяемых структур и способов получения необходимой информации, в результате должны быть даны ответы на следующие вопросы:
Используя эту информацию несложно создать гибкий способ, с помощью которого однозначно определить действия, которые следует предпринять для разрешения конфликта версий записей БД.
Введем следующие обозначения состояний записей:
Также обозначим через t момент времени, в который произошло изменение. Для состояния nih обозначения момента времени не требуется. Поскольку для работы способа необходимо описать состояние записи во всех базах данных, то для обозначения того, к какой базе относится состояние или момент времени будем использовать нижний индекс.
Пусть имеется две БД, одну из которых обозначим DB1, вторую – DB2. Предположим, что некоторая запись была создана в DB1, а затем реплицирована в DB2. После этого предположим, что в DB1 запись была изменена, а в DB2 – удалена, при этом действие в DB2 произведено позже, чем в DB1. В этом случае общее (учитывающее все БД) состояние записи будем обозначать как
t1<t2 & upd1 & del2,
где нижний индекс указывает индекс БД, в которой произошло относящееся к ней изменение состояние записи.
Результатом работы алгоритма должны явиться некоторые действия, которые следует предпринять для устранения конфликта версий. Для обозначения таких действий возьмем уже введенные нами обозначения:
Как и при обозначении состояний, нижний индекс будет указывать БД, в которой следует произвести действие.
Правило разрешения конфликтов версий записи можно выразить в форме логического следования или импликации (если – то), поэтому будем использовать следующую запись:
t1<t2 & upd1 & del2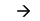 del1 & nih2.
del1 & nih2.
Эту запись следует читать следующим образом: «если изменение в DB1 произошло раньше, чем в DB2 и запись была изменена в DB1 и удалена в DB2, то необходимо ее пометить на удаление в DB1 и ничего не предпринимать в DB2». Заметим, что левая часть этого выражения состоит из трех предикатов (соотношение моментов времени – это один предикат), объединенных оператором логической конъюнкции. Приведенное правило может сработать только в случае, если все три предиката в левой части выражения истинны.
В общем случае правила для разрешения конфликта версий для N баз данных записываются в виде:
t1 i1 t2 i2 … iN-1 tN & s1 & s2 & … & sN a1 & a2 & … & aN,
где ti, i = 1...N – момент времени, в который произошло изменение в БД i;
ij = {<, >, =} или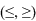 , j=1…N-1 – соотношение моментов времени tj и tj+1;
, j=1…N-1 – соотношение моментов времени tj и tj+1;
si, i = 1...N – состояние записи в БД i;
ai, i = 1...N – действие, которое следует предпринять для разрешения конфликта версий записей в БД i.
Левая часть этой импликации состоит из N+1 предикатов, правая – ровно из N действий. Полностью процесс разрешения конфликта версий записей состоит из набора таких правил. Для того, чтобы левые части импликаций были полными по смыслу и непротиворечивыми, необходимо чтобы они содержали все возможные сочетания предикатов только один раз. В противном случае возможно возникновение ситуации, при которой либо невозможно будет разрешить конфликт версий записи (отсутствует соответствующий набор предикатов), либо этот конфликт будет разрешаться неоднозначно (сочетание предикатов встречается более одного раза). Это простое рассуждение дает нам возможность сделать два вывода. Во – первых, в наборе правил левые части должны иметься для любого случая, который может возникнуть при эксплуатации БД. Во – вторых, эти части в одном наборе не могут повторяться.
Как обнаружить нужное правило? С точки зрения теории следует взять общее состояние конкретной записи и последовательно перебирать все правила, вычисляя левые части импликации до тех пор, пока не найдется такая импликация, в которой все предикаты левой части будут истины. Тогда для разрешения конфликта следует применить к копиям записи с ключом RK в каждой БД соответствующие действия, которые описаны в правой части импликации. После того, как найдено такое правило дальнейшие вычисления производить не следует и алгоритм может перейти к обработке следующего конфликта версий.
С точки зрения практики решение задачи видится несколько по-иному. Прежде всего, обратим внимание на предикат соотношения времен изменения записей. Каково бы не было количество баз, количество вариантов этого предиката не превышает 3N-1, если использовать три вида соотношения времен (<, >, =) и 2N-1 - если использовать два вида соотношения. Таким образом, можно закодировать все соотношения моментов времени изменения записи не более чем 3N-1 значениями, для чего использовать соответствующую функцию. Типы изменения состояний также возможно закодировать, ведь каждая запись может находиться только в одном из состояний. После осуществления этих операций требуется найти такое правило, левая часть которого будет в точности совпадать с полученными кодами.
Как только такое правило найдено, необходимо исполнить действия, описанные в правой его части. При этом полю TransTime присваивается значение реального времени. После урегулирования всех конфликтов версий следует зафиксировать время окончания репликации. Это требуется для того, чтобы внесенные изменения не участвовали в следующей репликации.
| ПРЕДУПРЕЖДЕНИЕ Существует еще одно ограничение. Если запись обновляется в двух и более таблицах, то вопрос о том, каким именно значением модифицировать запись каждой из таблиц выходит за рамки способа. |
Количество правил, которые требуются для разрешения конфликтов версий записей, быстро растет с увеличением количества баз, вовлеченных в процесс репликации. Этот рост носит характер степенной функции. Точная формула, позволяющего определить количество левых частей импликаций, зависит от того, какую схему использовать для синхронизации состояния баз данных. Рассмотрим два варианта таких схем. Первый вариант условно назовем «звезда», второй - «сеть». Вариант «звезда» является базовым, вариант «сеть» строится с использованием вырожденного случая варианта «звезда».
Традиционно считается, что такая структура достаточно проста. В центр «звезды» помещают базу данных, которую считают главной или ведущей. Все прочие базы считаются подчиненными или ведомыми. Обычно, при возникновении конфликта версий он разрешается в пользу состояния, которое имеет запись в главной базе данных. Поскольку рассматриваемые правила позволяют более точно характеризировать состояние записей и предполагают более сложные действия по устранению их конфликта, указанное определение следует расширить.
При рассмотрении схемы синхронизации БД типа «звезда» будем говорить об одновременной синхронизации двух и более баз данных. Например, на рис. 1 синхронизируется состояние трех БД за один сеанс репликации.
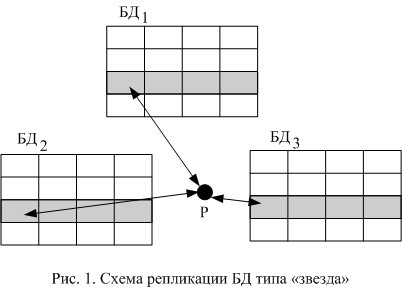
Теперь опишем правила, с помощью которых можно получить левые части всех правил разрешения конфликтов версий записей.
, где К – количество предикатов, зависящих от времени, сочетая их с полученными вариантами состояний.Как было сказано выше, количество левых частей растет пропорционально степенной функции. Например, если для двух БД количество левых частей импликаций равно 16, то для трех БД уже 114. Случай 2-х БД есть вырожденный случай звезды.
В этой схеме за один сеанс репликации синхронизируются состояния только 2-х БД, однако, одна запись может «дрейфовать» по всей сети. Для того, чтобы все БД были синхронны, требуется исполнить все репликации (рис. 2).
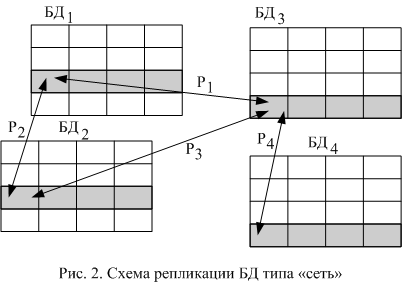
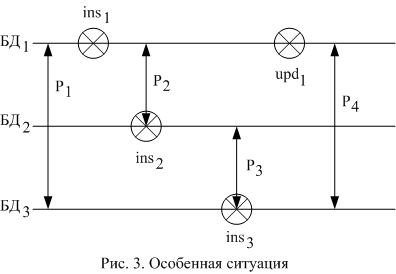
В этой структуре возможна ситуация, которая изображена на рис. 3. После того, как была выполнена синхронизация БД1 и БД3 (Р1) в БД1 добавляется новая запись (ins1). При следующей репликации Р2 эта запись переносится в БД2 (ins2). Затем, при синхронизации состояний БД2 и БД3 (Р3) запись вносится в БД3. После этого запись модифицируется в БД1 (upd1). При разрешении конфликта версий записей при репликации Р4 получается ситуация, при которой для базы БД1 запись имеет статус upd, а для БД3 – ins. Таким образом, для успешного разрешения конфликтов версии в левых частях правил следует предусмотреть ситуацию, в которой символ ins сочетается не только с символом nih, но и с символами upd и del. На первый взгляд, можно исключить эту ситуацию, если для каждой из БД рассматривать изменения, произведенные с момента последней успешной репликации с любой базой. Однако, в этом случае, запись не будет внесена в БД3, поскольку операция ins2 производится до фиксации момента окончания Р2.
Правила образования левых частей для этой схемы аналогичны правилам, применяемым для схемы звезда с учетом приведенной выше особенности.
Ниже приведенный пример лишь демонстрирует общие принципы, пренебрегая особенностями конкретной реализации. Пусть требуется обеспечить репликацию данных между двумя базами DB1 и DB2. Для построения правил разрешения конфликтов версий записей выберем схему «звезда». Пусть в базе данных DB1 существует таблица, схематичная структура которой выглядит следующим образом:
RTable1(PK, Data, DBID, RID, ChType, TransTime),
где PK — первичный ключ;
Data — данные хранимые таблицей;
DBID — идентификатор БД, в которой была создана запись;
RID — идентификатор записи для репликации, который был присвоен при создании записи;
ChType — код типа изменения, произошедшего с записью, целочисленный тип данных;
Для ChType примем следующую кодировку:
TransTime — момент времени, в который произошло изменение записи. Также допустим, что база данных DB2 также содержит таблицу RTable1 идентичной схематичной структуры с теми же наименованиями атрибутов. Несложно заметить, что этот вариант схематичного представления структуры таблицы эквивалентен Table1. При этом RK = {DBID, RID}; Ver_Stamp = {ChType, TransTime}.
Также пусть существует таблица, которая будет разрешать конфликт версий записей указанных таблиц. Ее схематичная структура будет следующей:
Res_Table(time_relation,state1,state2,action1,action2),
где time_relation имеет целочисленный тип и следующую кодировку:
где t1 и t2 – моменты изменения состояния записи соответственно в DB1 и DB2.
state1 и state2 - состояния, в которых находятся записи в соответствующих базах. Их кодировка совпадает с кодировкой ChType.
action1 и action2 – действия, которые следует предпринять для разрешения конфликта версий записей. Тип данных этих полей, а также их кодировка могут выбираться разработчиком по обстоятельствам. Заполним поля time_relation, state1 и state2 таблицы Res_Table в соответствии с правилами образования левых частей схемы «звезда», а поля action1 и action2 в соответствии с тем, как требуется разрешать конфликт версий записей в том или ином случае.
Для распознавания соотношения моментов времени будем использовать следующую функцию:
CREATE
FUNCTION time_moment_relation
(time1 datetime,
time2 datetime)
RETURNS int
ASBEGINdeclare res as int
if time1>time2
beginselect res=1
endelsebeginif time1=time2
beginselect res=2
endelsebeginif time1<time2 select res=3
endendRETURN res
END |
Для того, чтобы обнаружить актуальные изменения в таблице требуется еще одна точка на временной шкале. Это момент завершения последней успешной репликации между этими БД. Обозначим его как SRT. С каждой записью что-то когда-то происходило, и если не установить некоторого порогового значения момента времени, то сравнивать версии придется для всех записей, находящихся в RTable1.
Используя указанное ограничение, запрос
Select
DBID,
RID,
ChType,
TransTime
From
DB1.RTable1
Where
(TransTime > SRT)
|
вернет значения RK и Ver_Stamp всех записей, которые были внесены в таблицу, либо были модифицированы, либо были помечены на удаление с момента SRT. Результат работы этого запроса обозначим через DB1_Change. Для DB2 выполним аналогичный запрос, заменяя повсюду DB1 на DB2. Результат работы этого запроса обозначим через DB2_Change.
Для того, чтобы найти состояние записи во всех базах сразу следует исполнить запрос вида:
Select
time_moment_relation(DB1_Change.TransTime,DB2_Change.TransTime) as moment_relation
ISNULL(DB1_Change.ChType, 0) as St_DB1,
ISNULL(DB2_Change.ChType, 0) as St_DB2,
DB1_Change.DBID as DBID,
DB2_Change.RID as RID
From
DB1_Change fullouterjoin DB2_Change
On ((DB1_Change.DBID = DB2_Change.DBID) and (DB1_Change.RID = DB2_Change.RID))
|
Результат этого запроса обозначим через General_State. Следующий запрос выдаст необходимые действия для разрешения конфликта записей:
Select
Res_Table.action1,
Res_Table.action2
General_State.DBID as DBID,
General_State.RID as RID
From
General_State innerjoin Res_Table on ((General_State.moment_relation = Res_Table.time_relation) and (General_State.St_DB1 = Res_Table.state1) and (General_State.St_DB2 = Res_Table.state2))
|
Основываясь на результатах этой выборки, следует предпринять конкретные действия по устранению конфликтов версий записей. Если разрешение конфликтов версий завершилось удачей, то вычисляется новое значение для последней успешной репликации SRT1. Далее следует выполнить запрос для DB1 вида:
Update
DB1.RTable1
Set
ChType = 0,
TransTime = SRT1
Where
(TransTime > SRT)
|
Для DB2 выполним аналогичный запрос, заменяя повсюду DB1 на DB2.
Какие еще возможности имеет рассмотренный способ? Обратим внимание на то, что в левой части используются только служебные данные. Остальные поля, которые в приведенной схематической структуре скрываются под обозначением Data, никак не участвуют в процессе обработки. Логично предположить, что и их можно задействовать на пользу всего процесса. Для этого в левые части правил разрешения конфликта следует добавить еще один предикат, в котором будут задействованы не только служебные, но и неслужебные данные. Дополнение правил таким предикатом, естественно, еще увеличит количество правил разрешения конфликтов. Однако даст еще большие возможности управления процессом синхронизации БД, поскольку в этом случае возможно не только определить факт, что данные изменились, но и понять как они изменились. Не следует забывать, что правила разрешения конфликтов должны описывать все ситуации, которые могут возникнуть при синхронизации данных.
Рассмотренный способ не является каким-то принципиально новым. В действительности он - простое расширение уже существующих способов. При описании изменения данных используется декларативный подход, что также является его достоинством. Способ может быть реализован с помощью табличной функции, что дает возможность менять правила разрешения конфликтов практически «на лету».
И теперь самый главный вопрос: «А зачем?». А вот затем, чтобы не ломать голову в случае возникновения сложных ситуаций. Обращаясь к эпиграфу статьи, если уже и пришлось столкнуться именно с «керосиновым ветром», то есть способ отличить «северный» от «южного», а также в случае «северного керосинового» точно знать, что «он из снежной Арктики». Что же касается количества правил, то здесь уместно вспомнить различие терминов «большой» и «сложный», определение которых приводится, например, в [9].
| Оценка 40 Оценить
|