 Оценка 535
Оценка 535 
 Оценить
Оценить 





| Оценка 535 Оценить
|
Исходные коды алгоритма (ImageRegTest_src.zip)
Бинарные файлы (ImageRegTest_bin.zip)
Регистрация (сопоставление, наложение) двух изображений – это процедура поиска наилучшего в некотором смысле соответствия между пикселями данных изображений. Чтобы регистрация была успешной, изображения должны быть подобными, то есть, в результате преобразования первого изображения (или какой-либо его части) может быть получено второе изображение (либо его часть). Кроме того нужно, чтобы изображения уже сами по себе находились в приближенном соответствии, то есть должно быть задано начальное приближение, от которого будет производиться поиск оптимальных параметров соответствия изображений.
Например, регистрация применяется при решении задачи построения панорамы, имея несколько изображений, полученных с камеры (рис. 1). Если имеются несколько фотографий, на которых сняты с различающихся точек зрения части одного и того же пейзажа, то получить панораму (одно большое изображение, совмещающее в себе все части), можно путем регистрации (наложения) фотографий.

Рис. 1. Сферическая панорама, полученная из набора из 54 фотографий. Иллюстрация взята из работы [1].
Регистрация изображений применяется также при решении задачи трекинга (англ. tracking, отслеживание) визуальных объектов. Например, если нужно отследить движение головы человека (рис. 2) между последовательными видеокадрами, то можно воспользоваться алгоритмом регистрации для поиска параметров движения модели головы.
| ПРИМЕЧАНИЕ В подходе на рис. 2 в качестве модели головы берется трехмерная поверхность (цилиндр), покрытая текстурой. Поверхность позиционируется в трехмерном пространстве таким образом, чтобы ее проекция (используется перспективная проекция) совпадала с изображением головы на первом видеокадре. Когда с камеры поступает новый кадр, поверхность проецируется на плоскость, и затем изображение-проекция регистрируется с текущим полученным с камеры видеокадром. В результате определяются параметры межкадрового движения модели головы, и ее положение в пространстве обновляется, приходя в соответствие с текущим кадром. |
Одним из подходов к решению задачи регистрации изображений является метод [2], предложенный Брюсом Д. Лукасом и Такео Канаде. В данном методе регистрация пары изображений сводится к задаче нелинейной оптимизации, а для поиска параметров наилучшего совпадения изображений используется градиентный метод Ньютона.
В работе [3] Саймоном Бэкером, Фрэнком Деллаертом и Иэном Мэтьюзом предложена модификация метода Лукаса-Канаде, которая называется инверсно-композиционным (inverse-compositional) алгоритмом наложения изображений. В соответствии с такой терминологией оригинальный метод Лукаса-Канаде называют прямо-аддитивным (forwards-additive) алгоритмом. Инверсно-композиционный метод регистрации является более эффективным в вычислительном плане, чем прямо-аддитивный метод.
![]()
Рис. 2. Отслеживание движения модели головы между последовательными видеокадрами. Иллюстрация взята из работы [4].
В данной статье рассматривается программная реализация инверсно-композиционного метода регистрации изображений средствами языка C++ и библиотеки OpenCV. Язык C++ выбран по той причине, что он позволяет писать быстродействующий код, а быстродействие является критическим фактором для многих приложений. Библиотека OpenCV (Open Computer Vision Library, открытая библиотка компьютерного зрения) используется по той причине, что предоставляет удобные средства для манипуляции изображениями и матрицами.
Описание алгоритмов регистрации изображений я встречал только на английском языке и в форме, не очень понятной для начинающего исследователя. Читатель должен иметь возможность в целом представить себе, о чем в статье идет речь без отсылки к внешним источникам. Поэтому перед тем как приступить к описанию кода программы считаю необходимым привести интуитивный вывод математических формул для алгоритма регистрации.
Подчеркну, что выводимые закономерности были до меня получены Лукасом-Канаде [2], Бэкером-Деллаертом-Мэтьюзом [3; 5] и др. Я лишь хочу познакомить читателей со своим авторским пониманием данных закономерностей.
В растровой графике изображение является двумерным массивом, состоящим из дискретных элементов (точек) также называемых пикселями. Растровое изображение может содержать различный набор цветов, например, 256 градаций серого цвета либо палитру, содержащую несколько миллионов цветов.
Если изображение содержит оттенки серого (grayscale), то значение пикселя такого изображения называется его интенсивностью (pixel intensity). Интенсивность пикселя – скалярная величина, принимающая целые значения в диапазоне от 0 до 255. Мы будем работать с растровыми grayscale-изображениями. Если изображение цветное, его всегда можно преобразовать в grayscale.
Итак, постановка задачи регистрации изображений состоит в следующем.
Пусть имеются два растровых изображения (рис. 3), первое из которых (либо некая его часть) может быть переведено во второе изображение (либо в часть второго изображения) посредством заданного преобразования W, зависящего от набора параметров.
Необходимо, задавшись начальным приближением параметров, определить такие параметры данного преобразования W, при которых устанавливается наилучшее (в смысле, определяемом далее) соответствие между двумя изображениями.
![]()
Рис. 3. Два изображения, между которыми можно установить соответствие (в данном случае соответствие устанавливается между областями, содержащими проекцию игрушечной машинки). Иллюстрация взята из работы [6].
Начну рассуждения с простой модели сопоставления пикселей – параллельного переноса.
Пусть имеем два grayscale-изображения I1 и I2 (см. рис. 3). Интенсивность любого пикселя x=(x,y)T изображения I1 обозначим за I1(x), а интенсивность любого пикселя изображения I2 обозначим за I2(x).
| ПРИМЕЧАНИЕ Здесь и далее T – значок транспонирования матрицы. |
Пусть мы знаем, что некому конкретному пикселю xn=(xn,yn)T изображения I1 семантически (по смыслу) соответствует пиксель x′n=(xn+Δx,yn+Δy)T изображения I2, причем интенсивности этих пикселей равны между собой (графически я буду обозначать соответствие пикселей через xn→x′n):
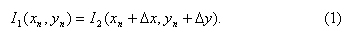
Если бы удалось решить уравнение (1) относительно неизвестных Δx и Δy, то мы бы определили соответствие между изображениями I1 и I2.
Возникает первая проблема – уравнение (1) является нелинейным относительно неизвестных Δx и Δy. Это обусловлено тем, что интенсивность пикселя изображения в общем случае нелинейно зависит от аргумента x. Если бы мы дальше продолжали работать с нелинейным уравнением, то увидели бы, насколько громоздкими получаюся выражения. Чтобы решить данную проблему, удобно линеаризовать выражение (1).
Как известно из курса математического анализа [7, с. 157], для приближенного вычисления значений функции применим ее дифференциал – главная линейная часть приращения функции, отличающаяся от соответствующего приращения на бесконечно малую величину более высокого порядка, чем приращение независимого аргумента.
| ПРИМЕЧАНИЕ В некоторых работах [3; 5; 6] вместо замены приращения функции на полный дифференциал используется разложение в ряд Тэйлора [8, с. 107] и отбрасывание членов ряда высших порядков малости. На мой взгляд, использование полного дифференциала более удобно (и просто), поскольку разложение в ряд Тейлора требует дополнительного доказательства того, что сумма ряда в заданной окрестности действительно сходится к конечному числу, и что это число является значением функции. |
Итак, если приращение аргумента мало, то правая часть выражения (1) может быть аппроксимирована путем замены приращения функции на ее полный дифференциал:
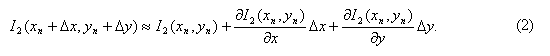
Изображение можно себе представить в виде функции от двух переменных – x и y. Поэтому дифференцировать его можно точно так же, как и обычную функцию от двух переменных.
Заменяя правую часть в уравнении (1) на (2), получим приближенное равенство
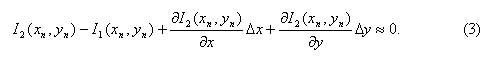
Итак, мы получили линеаризованное выражение (3). Но имея два неизвестных в одном уравнении, невозможно найти единственное решение. Если кратко, то чтобы получить единственное решение, далее нам придется рассматривать не один пиксель, а группу из N пикселей, и для них решать систему из N уравнений (3). Но об этом далее, а сейчас я хочу обобщить рассуждения на случай любой модели сопоставления пикселей.
Известно, что существует много параметрических моделей сопоставления пикселей [1]. К их числу, помимо параллельного переноса, можно также отнести операции вращения, масштабирования, аффинное преообразование, проецирование, искажение линзы (lens distortion), и так далее. Поэтому целесообразно ввести обобщенную модель сопоставления пикселей (pixel mapping model):
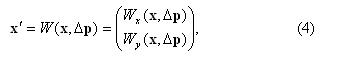
где W(x,Δp) – некая вектор-функция, ставящая в соответствие пикселю x=(x,y)T на изображении I1 пиксель x′=(x′,y′)T на изображении I2; Δp=(Δp1, Δp2,…,Δpm)T – m-мерный вектор приращений параметров. Введем требование, чтобы при равенстве вектора приращений параметров Δp нулю функция (4) переводила пиксель в самого себя: W(xn,0)=xn. При введенном условии приращение параметров Δp отмеряется от точки 0.
|
Функция W(x,Δp) может зависеть от Δp как линейно (например, аффинное преобразование), так и нелинейно (например, перспективная проекция). |
Отметим, что в различных источниках, в зависимости от постановки задачи, функцию (4) также называют моделью движения, motion model [4], либо функцией деформации, warp function [3].
В частности, для рассмотренного выше случая 2D параллельного переноса, функция (4) будет иметь вид W(x,Δp)=(x+Δx,y+Δy)T, а Δp=(Δx,Δy)T.
Используя введенное понятие обобщенной модели сопоставления пикселей W(x,Δp), равенство (1) можем переписать в следующем виде:
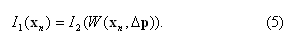
Выражение (5) будем называть прямым (forwards) соответствием. Недостатком этого выражения является то, что формулы, получаемые на его основе (здесь я не буду их выводить), являются не самыми эффективными в плане вычислений.
В своем алгоритме [3] Саймон Бэкер, Фрэнк Деллаерт и Иэн Мэтьюз предложили записать выражение (5) в «инверсном» виде (отсюда первая часть названия алгоритма – «инверсный»):
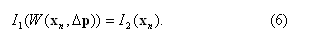
В выражении (6) условимся, что хотя вид функции W(xn,Δp) и не изменится, но она будет переводить пиксели от изображения I2 к изображению I1. То есть, если функция (4) задавала соответствие xn→x′n, то W(x,Δp) в выражении (6) будет задавать соответствие между пикселями в обратном направлении x′n→xn. Я не буду обозначать функцию W в (6) каким-то другим значком (потому что на это нет оснований), просто еще раз подчеркну, что факт «инверсности» должен быть учтен позже, когда нужно будет построить композицию моделей сопоставления пикселей.
Левая часть выражения (6) может быть аппроксимирована путем замены приращения функции на ее полный дифференциал (при написании формулы также используем свойство инвариантности первой формы дифференциала [9, с. 220]):
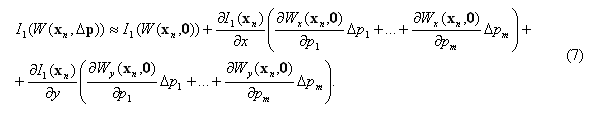
Выражение (7) накладывает на функцию W(x,Δp) требование дифференцируемости в точке (xn,0), а, следовательно, эта функция должна быть и непрерывной в данной точке.
Подставим (7) в (6), заменяя знак приближенного равенства, и учитывая, что I1(W(xn,0))=I1(xn):
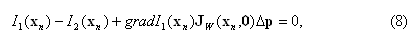
где gradI1(xn)=(∂I1(xn)/∂x,∂I1(xn)/∂y) – градиент изображения I1, вычисленный в точке xn; Jw(xn,0) – матрица первых частных производных (матрица Якоби) функции W(xn,Δp), вычисленная в точке (xn,0):
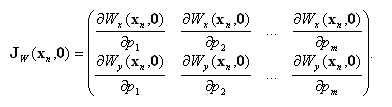
Уравнение (8) является линейным относительно компонентов вектора Δp. Однако решить данное уравнение не представляется возможным, так как число неизвестных m больше числа уравнений (m>1). Поэтому далее перейдем к составлению системы уравнений для группы пикселей изображения.
В изображении I1 можно выделить некую целевую область Ω, содержащую в себе N пикселей. Например, это может быть область, содержащая все пиксели визуального объекта, за исключением пикселей фона. Если предположить, что все N пикселей можно сопоставить со вторым изображением, применяя функцию W(x,Δp), то можно записать систему из N линейных неоднородных уравнений.
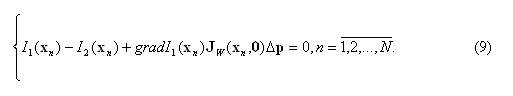
В силу отсутствия точного решения переопределенных систем (в которых число уравнений больше числа неизвестных), на практике принято вместо него отыскивать вектор, наилучшим образом удовлетворяющий всем уравнениям, то есть минимизирующий норму невязки системы в какой-нибудь степени. Данная проблема изучается в разделе математической статистики под названием регрессионный анализ. Обычно минимизируют квадрат отклонений от оцениваемого решения, для чего применяют так называемый метод наименьших квадратов [10, с. 160].
Для поиска решения системы (9) по методу наименьших квадратов, составим функционал
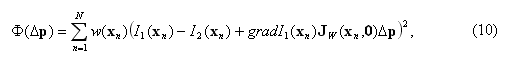
где w(xn) – скалярный вес n-го пикселя.
Очевидно, что значение Δp, при котором реализуется минимум функционала (10), будет наиболее близким к решению системы (9).
Вес w(xn) не равен нулю, если пиксель принадлежит области Ω, в противном случае вес равен нулю. Например, удобно присвоить пикселю вес 255, если он принадлежит области Ω, в противном случае присвоить пикселю нулевой вес. В зависимости от решаемой задачи, значения весов пикселей могут варьироваться.
Веса пикселей w(xn) удобно хранить в виде отдельного изображения C (см. рис. 4). Это изображение будем называть картой уверенности (confidence map). Термин «уверенность» здесь характеризует нашу уверенность в том, что конкретный пиксель с большим весом должен дать больший вклад в сумму (10).

Рис. 4. Карта уверенности. Белый прямоугольник – область Ω.
Для минимизации функционала (10) можно применить градиентный метод Ньютона [11, с. 45; 12]. Итерационная схема метода Ньютона представляет собой выражение
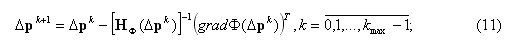
где Δpk+1 и Δpk – соответственно текущее и предыдущее приближения вектора Δp; k и kmax – соответственно текущий номер (начиная с нуля) итерации и максимально возможное число итераций; gradФ(Δpk) – градиент (вектор порядка m первых частных производных) функционала (10), вычисляемый по формуле:
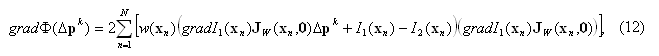
H Ф(Δp) – матрица (порядка m×m) вторых частных производных (матрица Гессе), которая для функционала (10) находится по формуле
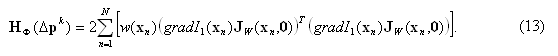
Сложный вид выражений (12) и (13) может несколько смутить, однако данные выражения легко вывести самостоятельно, применяя формулы дифференцирования элементарных функций и сложной функции [8, с. 197] и перенося их на случай функции многих переменных.
Заметим, что в данной задаче матрица Гессе (13) фактически не зависит от вектора Δpk, поэтому далее будем опускать аргумент Δpk и писать HФ. Достаточно вычислить HФ однократно на фазе предварительных вычислений, что привлекательно в плане вычислительной эффективности.
В качестве начального приближения вектора Δp0 принимаем нулевой вектор 0. То есть вначале функция (4) будет переводить пиксель в самого себя. Поэтому я выше упоминал, что для того, чтобы регистрация была успешной, изображения уже должны быть в примерном соответствии.
В качестве основного критерия останова итераций примем
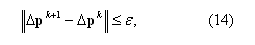
где значок ║.║ обозначает норму вектора; в качестве нормы берется максимальный по модулю компонент вектора; ε – заданная точность (в моем эксперименте ε=10-3). Смысл критерия (14) заключается в том, чтобы прекратить поиск, когда отличие нового приближения Δpk+1 от предыдущего Δpkпренебрежимо мало.
На случай, если процесс расходящийся введем ограничение на максимальное число итераций kmax (к вопросу о выборе максимального числа итераций я еще вернусь позже).
Наконец, ниже приведу полную схему алгоритма минимизации функционала (10).
Фаза предварительных вычислений.
Фаза итераций.
Приведенную выше схему минимизации я буду называть внутренним итерационным циклом (дальше я объясню почему).
Так как в формуле (7) мы упрощенно использовали лишь линейную часть приращения функции, то найденное на выходе внутреннего цикла итераций решение Δp является всего лишь приближенным.
Чтобы улучшить точность поступают следующим образом. Имея приближение Δp, можно с помощью функции W(x,Δp) деформировать одно из изображений (I1 или I2), таким образом «сближая» его со вторым изображением. Если для пары изображений мы вычислим в этот момент значение функционала (10), то оно окажется меньше, чем было в начале, то есть изображения станут лучше «соответствовать» друг другу.
Затем снова ищем вектор Δp, подавая на вход внутреннего цикла уже не исходное, а деформированное изображение. Этот внешний итерационный цикл (рис. 5) будем продолжать до тех пор, пока не выполнится некий критерий останова, либо пока не будет превышено максимально возможное число итераций.
В принципе не важно, какое из изображений (I1 или I2) деформировать, так как они равноправны. Но с точки зрения вычислительной эффективности выгоднее деформировать I2. Если будем деформировать изображение I1, то затем придется вновь вычислять градиент изображения grad I1, а следовательно и матрицу Гессе HФ. Кроме того придется деформировать и карту уверенности C. Если же будем деформировать изображение I2, то градиент grad I1, матрица HФ и карта уверенности C остаются неизменными. Поэтому деформируют именно изображение I2.
Ранее договорились, что в формуле (6) модель сопоставления пикселей осуществляет преобразование x=W(x′,Δp), где x – пиксель изображения I1, а x′ – пиксель изображения I2. Вот мы и переведем пиксели изображения I2 в направлении сближения с изображением I1, положив I2(W(x,Δp)):=I2(x), для любого x, принадлежащего Ω. В [3] эта процедура называется «warping backwards onto the coordinate frame of the template» («деформацией назад в координатную систему шаблона»), где под шаблоном подразумевается изображение I1.

Рис. 5. Иллюстрация к внешнему итерационному циклу. Слева показано изображение I1. Изображение I2 получено путем сдвига и вращения первого изображения. Справа показан ряд сближающих деформаций изображения I2(0)– I2(7), полученных на итерациях 0-7.
Рассмотрим подробнее, как именно реализуется алгоритм деформации изображения I2 на практике. Пусть необходимо получить деформированное изображение I2(0), имея исходное изображение I2. Неудобно выполнять операцию присваивания пикселю I2(W(x,Δp)), так как координаты W(x,Δp) могут быть дробными. Поэтому поступают наоборот. В цикле для каждого пикселя x=(x,y)T, принадлежащего области Ω изображения I2, вычисляются координаты x′ =(x′,y′)T по формуле
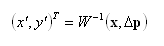
где W-1(x,Δp) – функция, обратная к функции (4). Следовательно, функция (4) должна (помимо дифференцируемости) обладать свойством инвертируемости.
После этого пикселю изображения I2(1) с координатами (x,y)T присваивается интенсивность I2(x′,y′). Подчеркнем, что координаты (x,y)T всегда принимают целые значения, а координаты (x′,y′)T в силу непрерывности функции W(x,Δp) могут быть дробными (термин субпиксельная точность, subpixel accuracy). Для того чтобы вычислить значение интенсивности пикселя I2(x′,y′) с субпиксельной точностью (см. рис. 6), применяем формулу билинейной интерполяции [13]:
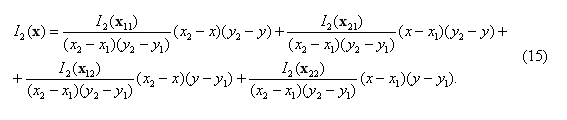
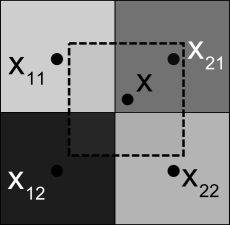
Рис. 6. Иллюстрация к методу билинейной интерполяции. Показан фрагмент растрового изображения. Точками обозначены центры пикселей. Интерполируемый пиксель, расположенный «между» соседними пикселями, обозначен пунктиром.
Внимательный читатель может заметить, что если деформировать изображение I2, затем деформировать результат деформации I2(0), и т.д., то из-за дискретности пикселей через несколько итераций возникнет эффект размытия и потери качества изображения I2(l), где l-номер итерации. Для того чтобы сохранить приемлемое качество результата деформации, можно всегда деформировать исходное изображение I2, но для его деформации использовать композицию W(l)(x)=W-1(...W-1(W-1(x,Δp0),Δp1),...,Δpl). Отсюда вторая часть названия алгоритма – «композиционный». Композиция и будет представлять собой результат работы алгоритма регистрации изображений.
Теперь снова вернемся к критерию останова для внешнего цикла итераций. В качестве критерия останова итераций примем условие ║ Δpl ║<γ, где l – номер итерации; γ – заданная точность (в моем эксперименте γ=10-3). Данный критерий имеет следующий смысл: при достижении достаточно малого Δp можно считать, что разница между изображениями I1 и I2 пренебрежимо мала. На случай, если процесс расходящийся, стоит ввести ограничение на максимальное число итераций lmax (в моем эксперименте lmax=100).
При осуществлении поиска Δpl с помощью деформированного изображения I2(l) иногда может обнаружиться, что значение целевой функции Ф(Δpl) оказалось даже больше, чем было достигнуто на предыдущем внутреннем цикле поиска Ф(Δpl-1). Т.е. могут наблюдаться осцилляции (колебания), хотя в целом процесс регистрации сходится на последующих итерациях (а может и не сходиться). Данный факт можно объяснить тем, что приближенное решение может отличаться от точного как с избытком, так и с недостатком. Поэтому я введу еще один критерий останова: выйти из цикла, если в течении q итераций подряд (я использую q=5) значение целевой функции Ф(Δpl) не становится меньше минимально достигнутого ранее значения Фmin.
Схема внешнего итерационного цикла:
Итак, на выходе получаем композицию моделей сопоставления пикселей. Для чего ее можно использовать? По определению композиция W(l)(x) позволяет по заданному пикселю x изображения I1 определить соответствующий ему пиксель x′ изображения I2.
Как хранить композицию в памяти? На практике функция (4) представляет собой матричное преобразование (я покажу это дальше на конкретном примере). Поэтому композицию обычно можно хранить как простую матрицу.
Можно ли извлечь из композиции параметры? Ведь работать удобнее с набором чисел, а не с матрицей. Кроме того, параметры количественно характеризуют состояние системы, чего не скажешь о матрице. Ответ – способы извлечения параметров из композиции существуют, но эти способы зависят от конкретного вида функции (4). Далее я покажу, как можно извлечь параметры из композиции, используемой мной в коде данной статьи.
То, что на выходе у инверсно-композиционного алгоритма получается именно композиция, можно, на мой взгляд, отнести к его недостаткам. Для сравнения, оригинальный алгоритм Лукаса-Канаде позволяет получать на выходе именно набор параметров (но зато метод Лукаса-Канаде меннее вычислительно эффективен).
Теперь перейдем к программной реализации вышеописанных математических выкладок на языке С++. В коде программы я буду использовать средства библиотеки компьютерного зрения OpenCV. Читателям, не знакомым с OpenCV, рекомендую обратиться к приложению 1, где я постарался кратко рассказать об основах работы с этой библиотекой.
Начну с определения абстрактного базового класса CPixelMappingModel для модели сопоставления пикселей W(x,Δp). Его определение приведено ниже (также см. файл InvCompAlgorithm.h).
// Абстрактный класс, задающий поведение для
// модели сопоставления пикселей.
class CPixelMappingModel
{
public:
// Возвращает число параметров.virtualint GetParamCount() = 0;
// Вычисляет координаты пикселя pDstPixel, которому соответствует // заданный пиксель pSrcPixel, используя текущуее состояние модели // сопоставления пикселей.// Возвращает true в случае успеха, false в случае ошибки.virtualbool MapPixel(
CvPoint2D32f* pSrcPixel, // [in] Координаты исходого пикселя.
CvPoint2D32f* pDstPixel // [out] Координаты пикселя, соотв. исходному.
) = 0;
// Сбрасывает внутреннее состояние модели сопоставления пикселей в начальное.// Возвращает true в случае успеха, false в случае неудачи.virtualbool Reset() = 0;
// Обновляет текущее состояние модели сопоставления пикселей.// Возвращает true в случае успеха, false в случае неудачи.virtualbool Update(
CvMat* pMatParams // [in] Вектор параметров.
) = 0;
// Вычисляет компоненты матрицы Якоби для функции сопоставления пикселей.// Возвращает true в случае успеха, false в случае неудачи.virtualbool CalcJacobianMat(
CvMat* pMatJacobian, // [out] Матрица Якоби.
CvPoint2D32f* pPixel // [in] Координаты пикселя.
) = 0;
}; |
Базовый класс CPixelMappingModel задает поведение для модели сопоставления пикселей. Метод GetParamCount() служит для того, чтобы узнать количество параметров, от которых зависит модель, так как число параметров может быть различным для каждой модели.
Метод MapPixel() вычисляет координаты пикселя x′, которому соответствует пиксель x. На выходе координаты x′ могут вполне получиться дробными. То, как модель осуществляет преобразование координат пикселя, зависит от ее текущего состояния. Сразу после создания модели, она будет переводить пиксель в самого себя. Состояние модели можно обновить методом Update(), который на вход берет вектор Δp. Для сброса модели в исходное состояние предназначен метод Reset().
И наконец, метод CalcJacobianMat() служит для того чтобы вычислить матрицу Якоби для функции W(x, Δp) в заданной точке (xn,0).
В качестве конкретной модели сопоставления пикселей для реализации в программе я решил использовать модель с тремя параметрами (с тремя степенями свободы, 3 degrees of freedom, 3DOF), которая сочетает в себе операции параллельного переноса и вращения в плоскости изображения.
Эту модель я реализовал в классе CPixelMappingModel3DOF (см. файл PixelMapping3DOF.h), который унаследован от абстрактного класса CPixelMappingModel. Я не стал перечислять методы, унаследованные от базового класса, и заменил их троеточием.
// Класс, реализующий модель сопоставления с тремя степенями свободы
// (с тремя параметрами). Модель допускает параллельный перенос
// и вращение в плоскости изображения.
class CPixelMappingModel3DOF : public CPixelMappingModel
{
public:
// Конструктор.
CPixelMappingModel3DOF();
// Деструктор.
~CPixelMappingModel3DOF();
/* Далее идут методы, наследуемые от CPixelMappingModel. */
...
// Возвращает композицию моделей сопоставления пикселей.
CvMat* GetComposition();
// Извлекает параметры параллельного переноса (fOffsX, fOffsY) // и угол Эйлера fRotAngle из композиции.bool ExtractParams(
// [in] Точка, вокруг которой производится вращение.
CvPoint2D32f ptRotCenter,
float& fRotAngle, // [out] Угол поворота в плоскости изображения.float& fOffsX, // [out] Смещение вдоль оси OX.float& fOffsY // [out] Cмещение вдоль оси OY.
);
private:
/* Переменные, использующиеся внутри класса. */
CvMat* m_pMatComposition; // Композиция моделей сопоставления пикселей 3 x 3.
CvMat* m_pMatTwist; // Матрица-твист 3 x 3.
CvMat* m_pMatA; // Вспомогательная матрица размера 3 x 3.
}; |
Теперь я вынужден снова вернуться к математике, чтобы объяснить, как работает данная модель сопоставления пикселей.
В компьютерной графике преобразование координат обычно осуществляется умножением некой матрицы преобразования G слева на вектор однородных координат X точки: Y=GX, где Y – результат преобразования, также является вектором однородных координат.
Параметризовать вращение можно несколькими способами [1, p. 11]. Один из наиболее распространенных – использование углов Эйлера. Например, вращение точки вокруг вектора (0,0,1)T можно задать матрицей
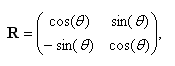
которая зависит от параметра θ – угла вращения (угла Эйлера).
| ПРИМЕЧАНИЕ Ось вращения (0,0,1)T – это вектор, имеющий основание в пикселе (0,0)T изображения и направленный перпендикулярно к плоскости изображения в сторону наблюдателя. Вращение вокруг этой оси еще называют вращением в плоскости изображения. |
Но известно, что использование углов Эйлера не способствует упрощению аналитических выражений (синусы и косинусы добавляют вычислительной работы).
Рассмотрим еще один, более удобный для нас, способ параметризации вращения. Вращение точки вокруг произвольного трехмерного вектора v=(vx,vy,vz)T единичной длины (║v║=1) на угол θ можно задать формулой Родригеса [14, p. 27]:
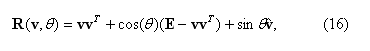
где E – единичная матрица;
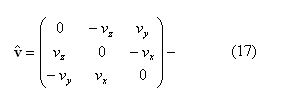
осесимметричная матрица.
При малых углах θ (а при регистрации мы обычно работаем с малыми углами вращения) можно приближенно считать
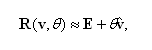
что делает эту формулу вычислительно привлекательной для параметризации малых вращений.
Если взять за основу матрицу вращения (17) и добавить в эту матрицу еще и возможность параллельного переноса, то получим матрицу (18). Эту матрицу будем называть твист-преобразованием (англ. twist, винтовое движение):
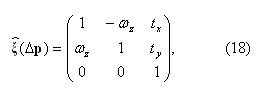
где Δp=(ωz,tx,ty)T.
Я кратко поясню структуру матрицы (18). Для более полного понимания рекомендую читателю открыть какую-нибудь книгу по компьютерной графике в разделе, описывающем однородные координаты и матричные преобразования. Итак, так как мы для простоты ограничимся вращением в плоскости изображения, то компоненты в третьем ряду и в третьем столбце матрицы (17) превратятся в нули. Чтобы можно было не только вращать, но и перемещать, в третий столбец вставляем компоненты tx, и ty, которые задают смещение соответственно вдоль осей OX и OY. Наконец, в главную диагональ ставим единицы (так как используем однородные координаты). Через ωz=θ я обозначил угол вращения вокруг вектора (0, 0, 1)T.
Используя твист-преобразование (18), модель сопоставления пикселей примет вид
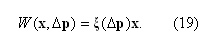
Расписав (19) подробнее, получим
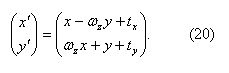
Класс CPixelMappingModel3DOF содержит три переменных-члена: m_pMatComposition служит для хранения композиции моделей движения; m_pMatTwist служит для задания твист-матрицы; m_pMatA – вспомогательная матрица, в которой я буду хранить промежуточный результат умножения.
Преобразование (20) реализовано в методе MapPixel().
bool CPixelMappingModel3DOF::MapPixel(
CvPoint2D32f* pSrcPixel,
CvPoint2D32f* pDstPixel
)
{
// Перемножить композицию и вектор координат.
pDstPixel->x =
CV_MAT_ELEM(*m_pMatComposition, float, 0, 0)*pSrcPixel->x +
CV_MAT_ELEM(*m_pMatComposition, float, 0, 1)*pSrcPixel->y +
CV_MAT_ELEM(*m_pMatComposition, float, 0, 2);
pDstPixel->y =
CV_MAT_ELEM(*m_pMatComposition, float, 1, 0)*pSrcPixel->x +
CV_MAT_ELEM(*m_pMatComposition, float, 1, 1)*pSrcPixel->y +
CV_MAT_ELEM(*m_pMatComposition, float, 1, 2);
returntrue;
} |
Вычисляя первые частные производные (20) по компонентам вектора Δp, получим матрицу Якоби:
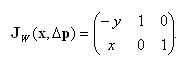
Как видим, данная матрица Якоби не зависит от Δp. Вычисление матрицы Якоби в точке (xn,0) реализовано в виде метода CalcJacobianMat().
bool CPixelMappingModel3DOF::CalcJacobianMat(
CvMat* pMatJacobian,
CvPoint2D32f* pPixel
)
{
CV_MAT_ELEM(*pMatJacobian, float, 0, 0) = -pPixel->y;
CV_MAT_ELEM(*pMatJacobian, float, 1, 0) = pPixel->x;
CV_MAT_ELEM(*pMatJacobian, float, 0, 1) = 1;
CV_MAT_ELEM(*pMatJacobian, float, 1, 1) = 0;
CV_MAT_ELEM(*pMatJacobian, float, 0, 2) = 0;
CV_MAT_ELEM(*pMatJacobian, float, 1, 2) = 1;
returntrue;
} |
Композиция функций (19) представляет собой произведение
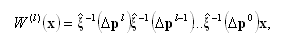
где минус-первая степень при матрице (18) обозначает ее обращение.
Как видим, хранить композицию можно в виде матрицы (вектор x очевидно из этой матрицы исключается). Обновление матрицы-композиции реализовано в методе Update().
bool CPixelMappingModel3DOF::Update(
CvMat* pMatParams
)
{
// Извлечь компоненты вектора Delta_p=(wz,tx,ty).float wz = CV_MAT_ELEM(*pMatParams, float, 0, 0);
float tx = CV_MAT_ELEM(*pMatParams, float, 1, 0);
float ty = CV_MAT_ELEM(*pMatParams, float, 2, 0);
// Инициализировать твист-матрицу.
cvSetIdentity(m_pMatTwist);
CV_MAT_ELEM(*m_pMatTwist, float, 0, 1) = -wz;
CV_MAT_ELEM(*m_pMatTwist, float, 1, 0) = wz;
CV_MAT_ELEM(*m_pMatTwist, float, 0, 2) = tx;
CV_MAT_ELEM(*m_pMatTwist, float, 1, 2) = ty;
// Инвертировать твист-матрицу.double dDet = cvInvert(m_pMatTwist, m_pMatA);
if(dDet==0)
{
returnfalse;
}
// Получить композицию матриц.
cvGEMM(m_pMatA, m_pMatComposition, 1, NULL, 0, m_pMatTwist);
cvCopy(m_pMatTwist, m_pMatComposition);
returntrue;
} |
Для решения задачи обращения матрицы я воспользовался функцией cvInvert() библиотеки OpenCV, прототип которой приведен ниже:
double cvInvert( const CvArr* src, CvArr* dst, int method=CV_LU ); |
Данная функция сводит проблему обращения матрицы к последовательному приведению матрицы к треугольному виду и решению системы линейных уравнений методом исключения Гаусса [15, с. 128]. Функция cvInvert() возвращает определитель исходной матрицы. Если он равен нулю, то матрица вырождена, и ее обращение невозможно.
Сбросить состояние модели в первоначальное позволяет метод Reset(), который сбрасывает матрицу-композицию в единичную матрицу.
bool CPixelMappingModel3DOF::Reset()
{
cvSetIdentity(m_pMatComposition);
returntrue;
} |
Теперь перейдем к возможности выделения параметров из матрицы-композиции. Я хочу определить угол поворота (угол Эйлера) и компоненты параллельного переноса. Начнем с выделения угла поворота из подматрицы вращения. Выше я приводил вид матрицы вращения, зависящей от угла Эйлера θ. Извлечь угол θ из нашей матрицы-композиции можно путем вычисления минус арксинуса от элемента r21 в ее втором ряду и первом столбце (знак минус потому, что мне нужно, чтобы вращению против часовой стрелки соответствовал положительный угол). И, наконец, компоненты параллельного переноса (с учетом того, что вращение происходит вокруг некоторой заданной точки (xc, yc), например вокруг центра изображения) можно определить как Δx = r13 - (1-cos θ )*xc + sin θ * yc;Δy = r23 – sin θ*xc – (1-cos θ) * yc.
Извлечение параметров из композиции реализовано в виде метода ExtractParams().
bool CPixelMappingModel3DOF::ExtractParams(
CvPoint2D32f ptRotCenter,
float& fRotAngle,
float& fOffsX,
float& fOffsY
)
{
// Извлечь угол вращения.float r_21 = CV_MAT_ELEM(*m_pMatComposition, float, 1, 0);
fRotAngle = -asin(r_21);
float cos_a = cos(fRotAngle);
float sin_a = sin(fRotAngle);
fRotAngle *= 180.0f/(float)M_PI;
// Извлечь параметры параллельного переноса.
fOffsX = CV_MAT_ELEM(*m_pMatComposition, float, 0, 2) -
(1-cos_a)*ptRotCenter.x + sin_a*ptRotCenter.y;
fOffsY = CV_MAT_ELEM(*m_pMatComposition, float, 1, 2) -
sin_a*ptRotCenter.x - (1-cos_a)*ptRotCenter.y;
returntrue;
} |
Сам инверсно-композиционный алгоритм регистрации изображений реализован в виде класса CInvCompAlgorithm (см. файл InvCompAlgorithm.h).
С точки зрения пользователя в этом классе можно выделить две группы методов: высокого уровня и низкого уровня. Если нужно просто провести регистрацию изображений, причем не требуется доступа к низкоуровневым настройкам, то можно воспользоваться методом RegisterImages(), код которого представлен ниже:
bool CInvCompRegistrationAlgorithm::RegisterImages(
IplImage* pImgI1,
IplImage* pImgConfMap,
IplImage* pImgI2,
CPixelMappingModel* pPixelMapping,
float fAccuracy,
int nMaxIters,
int nMaxOscillatingIters,
int* pnActualIters,
float fInnerAccuracy,
int nInnerMaxIters
)
{
// Инициализировать выход (число итераций) в нуль.if(pnActualIters)
*pnActualIters = 0;
CriteriaContext context;
// Выделяем ресурсы.
CvSize ImageSize = cvSize(pImgI1->width, pImgI1->height);
if(!AllocResources(ImageSize, pPixelMapping))
returnfalse;
// Фаза предварительных вычислений.if(!Precompute(pImgI1, pImgConfMap, pPixelMapping))
returnfalse;
// Внешний итерационный цикл.int l;
for(l=0; ; l++)
{
// Деформируем изображение I2.
WarpImageI2(pImgI2, pImgConfMap, pPixelMapping);
// Устанавливаем первоначальное приближение // вектора приращений параметров в нуль.
cvSet(m_pMatPrevParams, cvScalar(0));
// Значение функционала Ф.float F = 0;
// Внутренний цикл итераций.int k;
for(k = 0; ; k++)
{
// Вычислить новое приближение вектора приращений параметров.
F = ApproximateParameterIncrement(pImgI1, pImgConfMap,
pPixelMapping, m_pMatPrevParams, m_pMatNewParams);
if(F<0)
returnfalse;
// Проверить критерий останова внутреннего цикла.
CRITERIA_TYPE InnerLoopReady = IsInnerLoopReady(m_pMatPrevParams,
m_pMatNewParams, fInnerAccuracy, k, nInnerMaxIters);
// Обновить предыдущее приближение вектора приращений параметров.
cvCopy(m_pMatNewParams, m_pMatPrevParams);
// Выйти из цикла, если критерий останова выполнен.if(InnerLoopReady!=NONE)
break;
}
// Обновить композицию моделей сопоставления пикселей.if(!pPixelMapping->Update(m_pMatNewParams))
returnfalse;
// Проверить критерий останова внешнего цикла итераций.if(IsReady(m_pMatNewParams, fAccuracy, l, nMaxIters,
F, nMaxOscillatingIters, context ))
break;
}
// Возвратить реально достигнутое число итераций внешнего цикла.if(pnActualIters)
*pnActualIters = l;
returntrue;
} |
На вход данный метод берет grayscale-изображение pImgI1, карту уверенности pImgConfMap, второе изображение pImgI2 (все эти три изображения имеют тип IPL_DEPTH_8U, что соответствует uchar) и указатель на объект CPixelMappingModel, который скрывает под собой конкретную модель сопоставления пикселей. Также можно задать требуемую точность fAccuracy и максимальное число итераций nMaxIters внешнего цикла, максимально допустимое число «осциллирующих» итераций nMaxOscillatingIters, требуемую точность fInnerAccuracy и максимальное число итераций nInnerMaxIters внутреннего цикла. На выходе объект pPixelMappingModel будет содержать композицию моделей сопоставления пикселей, а также переменная *pnActualIters будет содержать реально достигнутое число итераций внешнего цикла (это может пригодиться для статистического анализа производительности алгоритма).
Но иногда простого вызова метода RegisterImages() может быть недостаточно. Например, в случае, когда надо контролировать какие-то внутренние параметры. В таком случае стоит рассмотреть низкоуровневые методы (AllocResources(), FreeResources(), Precompute(), ApproximateParameterIncrement(), IsReady(), IsInnerLoopReady()) и переменные-члены класса.
В алгоритме используются несколько матриц и изображений, которые хранятся в виде переменных-членов класса. Кратко рассмотрим их.
Изображения m_pImgGradI1x и m_pImgGradI1y предназначены для хранения компонентов градиента изображения I1, вычисленных с помощью оператора Собеля. Для избежания возможных проблем с потерей точности и переполнения я использую тип float для элементов этих изображений (IPL_DEPTH_32F). В изображении m_pImgWarpedI2 хранится деформированное изображение (его тип IPL_DEPTH_8U). В динамическом массиве m_apImgSteepestDescent хранятся изображения наискорейшего спуска (их тип также IPL_DEPTH_32F для избежания потери точности). Размер массива m_apImgSteepestDescent совпадает с числом параметров, от которых зависит модель сопоставления пикселей.
Матрица m_pMatGradF нужна для хранения градиента функционала (10), причем хранится он уже в транспонированном виде. Матрица m_pMatInverseHessianF содержит обращение матрицы Гессе (13), определенное на этапе предварительных вычислений. Матрицы m_pMatA и m_pMatV – вспомогательные, в них я храню промежуточный результат умножения. Векторы m_pMatPrevParams и m_pMatNewParams содержат соответственно предыдущее и текущее приближение вектора приращений параметров Δp. Тип всех этих матриц – CV_32FC1.
Выделение ресурсов происходит в методе AllocResources(). Я постарался сделать выделение ресурсов максимально гибким. Если размер матриц/изображений не совпадает с требуемым размером, то они выделяются повторно. Высвобождение ресурсов происходит в методе FreeResources(), который обычно вызывается в деструкторе.
Метод Precompute() реализует фазу предварительных вычислений из внутреннего итерационного цикла (схемы минимизации функционала (10)).
// Данный метод производит предварительное вычисление
// градиента изображения, изображений "наискорейшего спуска"
// и матрицы Гессе для целевой функции Ф.
bool Precompute(
IplImage* pImgI1, // [in] Изображение I1.
IplImage* pImgConfMap, // [in] Карта уверенности для I1.
CPixelMappingModel* pPixelMapping // [in] Модель сопоставления пикселей.
); |
Для вычисления градиента I1(xn)=(∂I1(xn)/∂x,∂I1(xn)/∂y) я использую функцию OpenCV сvSobel(), прототип которой приведен ниже:
void cvSobel( const CvArr* src, CvArr* dst, int xorder, int yorder,
int aperture_size=3 ); |
Стандартная функция библиотеки OpenCV cvSobel() использует оператор Собеля [16, p. 112] для аппроксимации градиента функции двух переменных:
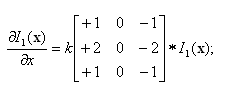
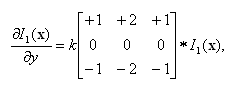
где через * обозначена операция 2D свертки (convolution), а в квадратных скобках приведена матрица-ядро свертки размерности 3×3, k=1/8 – скалярный нормализующий коэффициент. Координата x здесь возрастает «направо», а y — «вниз».
Оператор Собеля сочетает в себе операции гауссовой фильтрации и дифференцирования, так что результат более или менее нечувствителен к шуму. Функция cvSobel() берет на вход исходное изображение, а на выходе получается изображение, каждый пиксель которого содержит частную производную в соответствующей точке исходного изображения. Таким образом, чтобы вычислить градиент grad I1(xn), необходимо получить два изображения, первое из которых содержит ∂I1(xn)/∂x, а второе – ∂I1(xn)/∂y. Отмечу, что функция cvSobel()не производит умножение на нормализующий коэффициент k формулы оператора Собеля. Это обусловлено технической причиной – стремлением избежать потери точности при округлении (например, когда в качестве элемента изображения-градиента используется uchar или short), поэтому необходимо нормализовать результат операции самостоятельно, умножив каждый элемент полученных изображений на 1/8. Также существует опасность переполнения элемента изображения. Чтобы избавиться от этих проблем, я использую IPL_DEPTH_32F в качестве элемента изображения-градиента.
Метод ApproximateParameterIncrement() позволяет произвести одну итерацию внутреннего цикла минимизации функционала (10). Его декларация представлена ниже:
// Выполняет одну итерацию поиска вектора приращений параметров.
// Возвращает текущее значение для функционала Ф в случае успеха,
// в случае ошибки возвращает отрицательное число.
float ApproximateParameterIncrement(
IplImage* pImgI1, // [in] Изображение I1.
IplImage* pImgConfMap, // [in] Карта уверенности для изображения I1.
CPixelMappingModel* pPixelMapping, // [in] Модель сопоставления пикселей. // [in] Предыдущее приближение вектора приращений параметров.
CvMat* pMatPrevParams,
// [out] Новое приближение вектора приращений параметров.
CvMat* pMatNewParams
); |
На вход этот метод берет изображение pImgI1, карту уверенности pImgConfMap, второе изображение pImgI2, указатель на объект CPixelMappingModel, который скрывает под собой конкретную модель сопоставления пикселей и вектор pPrevParams (предыдущее приближение вектора приращений параметров Δp). На выходе получается вектор pNewParams - соответственно новое приближение вектора Δp.
Чтобы узнать, когда можно завершить внутренний итерационный цикл, служит метод IsInnerLoopReady(). Этот метод проверяет, выполняется ли критерий останова (14), и не превышено ли максимально возможное число итераций.
// Данный метод проверяет критерий выхода из внутреннего
// итерационного цикла. Возвращает ненулевое значение,
// если должен быть совершен выход из цикла.
CRITERIA_TYPE IsInnerLoopReady(
CvMat* pMatPrevParams, // [in] Предыдущее приближение // вектора приращений параметров.
CvMat* pMatNewParams, // [in] Новое приближение вектора // приращений параметров.float fAccuracy, // [in] Требуемая точность.int nCurrentIter, // [in] Номер текущей итерации, начиная с нуля.int nMaxIters // [in] Максимальное число итераций.
); |
Метод IsInnerLoopReady() возвращает значение типа CRITERIA_TYPE, которое представляет собой код критерия останова, который выполняется в данный момент. Если ни один из критериев не выполняется, то это значение равно нулю.
// Тип критерия останова.
enum CRITERIA_TYPE
{
NONE = 0, // Ни один критерий не выполнен.
ACCURACY_REACHED = 1, // Достигнута требуемая точность.
MAX_ITERS_REACHED = 2, // Достигнуто макс. число итераций.
OSCILLATION = 3 // Возникли колебания вблизи минимума.
}; |
Во внешнем итерационном цикле происходит деформация изображения I2 c помощью найденного на внутреннем цикле приближения вектора Δp,которое в предварительно было инкорпорировано в модель сопоставления пикселей вызовом CPixelMappingModel::Update(). Деформация производится с помощью метода WarpImageI2().
// Преобразует (деформирует) изображение I2 в соответствии
// с текущим состоянием модели сопоставления пикселей, таким образом
// "сближая" его с изображением I1.
IplImage* WarpImageI2(
IplImage* pImgI2, // [in] Изображение I2.
IplImage* pImgConfMap, // [in] Карта уверенности для изображения I1.
CPixelMappingModel* pPixelMapping // [in] Модель сопоставления пикселей.
); |
Данный метод использует алгоритм билинейной интерполяции для вычисления интенсивности пикселя с дробными координатами (субпиксельная точность). Алгоритм билинейной интерполяции реализован в виде метода InterpolatePixelIntensity().
float
CInvCompRegistrationAlgorithm::InterpolatePixelIntensity(
IplImage* pImg,
float x,
float y
)
{
// Вычислить ближайшие меньшие целые координаты пикселя (xi;yi).int xi = cvFloor(x);
int yi = cvFloor(y);
// Коэффициенты для интерполяционной формулы.float k1 = x-xi;
float k2 = y-yi;
// Проверить, что существуют пиксель справа // и пиксель снизу.int f1 = xi<pImg->width-1;
int f2 = yi<pImg->height-1;
uchar* row1 = &CV_IMAGE_ELEM(pImg, uchar, yi, xi);
uchar* row2 = &CV_IMAGE_ELEM(pImg, uchar, yi+1, xi);
// Интерполировать интенсивность пикселя.float fInterpolatedValue = (1.0f-k1)*(1.0f-k2)*(float)row1[0] +
(f1 ? ( k1*(1.0f-k2)*(float)row1[1] ):0) +
(f2 ? ( (1.0f-k1)*k2*(float)row2[0] ):0) +
((f1 && f2) ? ( k1*k2*(float)row2[1] ):0) ;
return fInterpolatedValue;
} |
И наконец, для внешнего итерационного цикла также есть свой метод для проверки критериев останова под названием IsReady().
// Критерий выхода из внешнего цикла. Возвращает ненулевое значение, если
// должен быть совершен выход из цикла.
CRITERIA_TYPE IsReady(
CvMat* pMatParams, // [in] Вектор параметров.float fAccuracy, // [in] Требуемая точность.int nCurrentIter, // [in] Номер текущей итерации, начиная с нуля.int nMaxIters, // [in] Максимально возможное число итераций.float fObjFuncVal, // [in] Текущее значение функционала Ф. int nMaxOscillatingIters, // [in] Максимальное число осциллирующих итераций.
CriteriaContext& context // [in] Контекст критерия.
); |
Фух… пора бы перейти к наиболее увлекательной части повествования – к демонстрации результатов работы алгоритма. Советую читателю теперь открыть решение ImageRegTest.sln и обратиться к файлам под названием main.cpp и Tests.cpp.
| ПРИМЕЧАНИЕ Скомпилировать решение ImageRegTest.sln можно в Visual C++ версии 2005 или более поздних версий. Конечно, перед сборкой решения необходимо установить библиотеку OpenCV и настроить директории включаемых и библиотечных файлов (см. прил. 1). |
Программа может работать в трех режимах – в режиме пошаговой демонстрации, в режиме теста производительности и в режиме проверки на корректность внутренних операций. Функционал для работы в этих трех режимах реализован в виде соответственно методов класса CTest::RunStepByStepDemo(), CTest::RunPerformanceTest() и CTest::RunCorrectnessTest().
Режим демонстрации нужен для того, чтобы наглядно увидеть (см. рис. 7), как происходит регистрация пары изображений. Первое из этих изображений я загружаю из файла Koala.JPG, и оно соответственно содержит изображение медведя коалы. Второе изображение я получаю путем деформации первого (немного смещаю и вращаю изображение вокруг его центра, используя случайно сгенерированные параметры). Для первого изображения я также задаю карту уверенности, на которой область Ω показана в виде закрашенного белого прямоугольника. Все действия по созданию тестовых изображений реализованы в виде метода CTest::CreateTestImages().
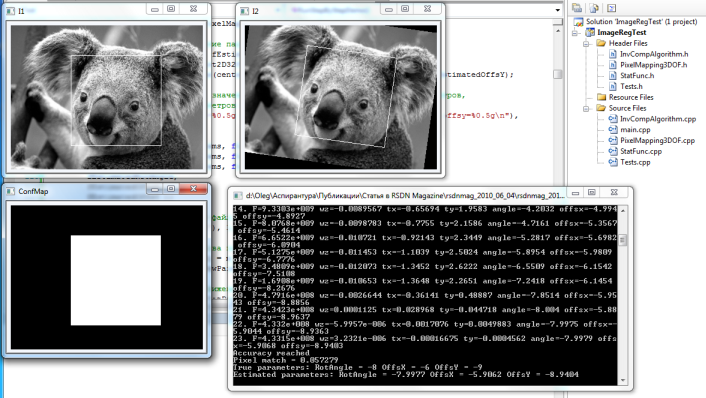
Рис. 7. Режим наглядной демонстрации.
В ходе работы алгоритма регистрации видно, как происходит сближение изображений на каждой итерации внешнего цикла.
Результат работы алгоритма визуально показан в виде прямоугольника на первом изображении, и соответствующего ему прямоугольника на втором изображении. Также я вычисляю точность соответствия пикселей на первом и втором изображениях. Это реализовано в виде метода CTest::CalcImageRegistrationAccuracy().
// Определяет точность регистрации путем вычисления среднего
// расстояния между положением трех углов прямоугольника после их преобразования с помощью
// эталонной матрицы pMatWarp и их положением после преобразования вычисленной в результате
// регистрации изображений матрицы pMatEstimatedWarp.
float CalcImageRegistrationAccuracy(
CvRect& rcROI, // [in] Прямоугольник, углы которого используются как контрольные точки.
CvMat* pMatWarp, // [in] Эталонная матрица деформации.
CvMat* pMatEstimatedWarp) // [in] Матрица деформации, вычисленная в ходе регистрации.
{
// Берем на прямоугольнике три контрольные точки (координаты трех его углов).
CvPoint2D32f ControlPoints[3];
ControlPoints[0] = cvPoint2D32f(rcROI.x, rcROI.y);
ControlPoints[1] = cvPoint2D32f(rcROI.x+rcROI.width, rcROI.y+rcROI.height);
ControlPoints[2] = cvPoint2D32f(rcROI.x+rcROI.width, rcROI.y);
float fMeanDistance = 0;
int i;
for(i=0; i<3; i++)
{
// Вычисляем положение точки после трансформации эталонной матрицей.
CvPoint2D32f ptWarped = WarpPoint(&ControlPoints[i], pMatWarp);
// Вычисляем положение точки после трансформации матрицей, найденной в// ходе регистрации изображений.
CvPoint2D32f ptWarped2 = WarpPoint(&ControlPoints[i], pMatEstimatedWarp);
// Найти расстояние между точками.float fDiffX = (ptWarped2.x-ptWarped.x);
float fDiffY = (ptWarped2.y-ptWarped.y);
fMeanDistance += sqrt(fDiffX*fDiffX + fDiffY*fDiffY);
}
fMeanDistance /= 3;
return fMeanDistance;
} |
Кроме того я извлекаю из композиции параметры вращения и параллельного переноса, используя метод CPixelMappingModel3DOF::ExtractParams().
И наконец, я записываю значение функционала (10) на каждой итерации внешнего цикла в текстовый файл log.txt. Пример графика зависимости значения функционала (10) от номера итерации показан на рис. 8.

Рис. 8. График зависимости значения функционала Ф от номера l итерации внешнего цикла. По горизонтальной оси отложены номера итераций, по вертикальной – значения функционала Ф.
Данный режим используется для оценки быстродействия алгоритма регистрации и его точности. Для этого я генерирую сто пар изображений, полученных с использованием случайных параметров вращения и параллельного переноса, и пытаюсь их регистрировать.
Кроме того я ранее обещал вернуться к вопросу о выборе числа итераций для внутреннего цикла итераций. Ответ следующий – лучше вообще ограничить внутренний цикл одной итерацией. Почему? Во-первых, потому что в различных источниках выполняют только одну итерацию из схемы Ньютона. Во-вторых, когда я сам провел сравнительные тесты регистрации с одной итерацией внутреннего цикла и с двумя итерациями, то увидел, что две итерации не дают абсолютно никакого преимущества. Результаты теста производительности записываются в два файла – stat1.txt и в stat2.txt, соответственно для случая с одной итерацией внутреннего цикла и с двумя итерациями. Пример файла stat1.txt приведен ниже.
Image registration time sample size (N) = 100 Image registration time minimum value (min) = 0.022 Image registration time maximum value (max) = 0.168 Image registration time mean value (E) = 0.04839 Image registration time std. dev. (sigma) = 0.0278962 Image registration time sample std. dev (s) = 0.0280367 Control point matching accuracy sample size (N) = 100 Control point matching accuracy minimum value (min) = 0.00149214 Control point matching accuracy maximum value (max) = 0.0688004 Control point matching accuracy mean value (E) = 0.0218244 Control point matching accuracy std. dev. (sigma) = 0.0153124 Control point matching accuracy sample std. dev (s) = 0.0153895 Iteration count sample size (N) = 100 Iteration count minimum value (min) = 2 Iteration count maximum value (max) = 30 Iteration count mean value (E) = 6.73 Iteration count std. dev. (sigma) = 5.3551 Iteration count sample std. dev (s) = 5.38208 |
Результаты представлены в табл. 1. Как следует из таблицы, если использовать две итерации на внутреннем цикле, то требуется почти столько же итераций внешнего цикла, но зато времени регистрация занимает больше, а точность при этом не увеличивается. Это можно объяснить тем, что, даже вычислив на внутреннем цикле итераций приближение вектора Δp c высокой точностью, мы все равно получим приближенное решение (так как используется линеаризация), значит одной итерации внутреннего цикла вполне достаточно.
Хочу еще пояснить, почему в качестве максимального числа итераций внешнего цикла я беру lmax=100, хотя из таблицы видно, что максимально было достигнуто 30 итераций, и в среднем тратится 6,73 итерации. Дело в том, что в условиях, когда различия между изображениями более значительные, может потребоваться больше итераций, поэтому lmax=100 берется с запасом.
|
Число итераций внутреннего цикла |
Время регистрации изображений, сек. |
Число итераций внешнего цикла, единиц. |
Точность сопоставления контрольных точек, в пикселях. |
||||||
|
мин. |
среднее |
макс. |
мин. |
среднее |
макс. |
мин. |
среднее |
макс. |
|
|
1 |
0.022 |
0.048 |
0.168 |
2 |
6.73 |
30 |
0.001 |
0.022 |
0.069 |
|
2 |
0.027 |
0.065 |
0.25 |
2 |
6.72 |
30 |
0.001 |
0.022 |
0.069 |
В данном режиме проводится тестирование различных внутренних операций. Например, важно убедиться, что модель сопоставления пикселей изначально переводит пиксель в самого себя, и что ее внутреннее состояние обновляется как и задумано. Тесты охватывают модель сопоставления пикселей, алгоритм билинейной интерполяции, алгоритм деформирования изображения, а также алгоритмы проверки критериев останова.
Во время процедуры тестирования, если все операции работают корректно, на экран ничего выводиться не должно. Если же какая-нибудь функция работает не так как ожидается, то выведется сообщение об ошибке, например такое:
ASSERTION FAILED IN FUNCTION:void __thiscall CTest::TestIsReady(void) EXPRESSION:crit==ACCURACY_REACHED |
В данной статье рассмотрены математическая формулировка и программная реализация инверсно-композиционного алгоритма сопоставления (регистрации) изображений средствами языка С++ и библиотеки компьютерного зрения OpenCV.
Пригодиться подобный алгоритм может, например, при решении задач создания панорамной фотографии по ее отдельным фрагментам и отслеживания визуальных объектов на видео.
Я постарался сделать реализацию алгоритма максимально гибкой, чтобы облегчить его адаптацию к конкретной решаемой задаче. Кроме того, я постарался сделать ее модульной, а значит более понятной и наглядной.
Конечно сделать код полностью пригодным под все задачи не возможно. Например, критически важным для некоторых задач может являться быстродействие кода. Для оптимизации быстродействия разработчику придется создать максимально монолитный код, по максимуму использовать макросы вместо вызовов функций. В таком случае выделение модели сопоставления пикселей в отдельный класс окажется не очень эффективным.
Данное приложение будет полезно читателю для освоения основ работы с библиотекой OpenCV. Здесь я привожу описание только основных функций и структур OpenCV, которые используются мной в приведенном выше коде.
Напомню, что библиотека компьютерного зрения OpenCV (англ. Open Computer Vision Library) –это коллекция функций, написанных на языке C, реализующих многие популярные алгоритмы обработки изображений и алгоритмы компьютерного зрения.
Зачем нужна OpenCV? Дело в том, что при реализации любого алгоритма из области компьютеного зрения, встречаются общие, низкоуровневые, базовые моменты, без реализации которых невозможно двигаться в плане разработки самого алгоритма. К таким элементам относится манипулирование изображениями, организация структур памяти, захват видеоизображения с камеры и загрузка изображения из файла. В результате многие исследователи вынуждены были выполнять одни и те же типовые работы. Однако, как и в любой другой области знания, в компьютерном зрении со временем появляются свои стандарты. Так, де-факто стандартом является открытая библиотека OpenCV. Ее значимый вклад заключается в наличии множества функций и алгоритмов, которые можно использовать как базу для создания новых алгоритмов. Помимо базовых функций, в библиотеку OpenCV включены многие алгоритмы компьютерного зрения, успешно зарекомендовавшие себя. Изначально OpenCV разрабатывалась под эгидой компании Intel. В настоящее время библиотека OpenCV развивается как международный open-source проект. Свой вклад в ее разработку внесли исследователи из многих стран мира.
При написании статьи я использовал версию OpenCV 1.0. Скачать данную версию библиотеки можно отсюда. Не могу сказать, что OpenCV 1.0 является самой новой (в настоящее время вышла уже версия OpenCV 2.1), но я успешно применяю версию 1.0 в течение уже довольно долгого времени, и поэтому тяготею именно к ней.
Установка библиотеки OpenCV сводится к запуску исполняемого файла и следованию нехитрым инструкциям инсталятора.
После установки файлов OpenCV необходимо настроить Visual C++, чтобы компилятор и линковщик смогли узнать о местоположении заголовочных и библиотечных файлов OpenCV. Для этого в окне Visual C++ выберите пункт меню Tools | Options… (Инструменты | Настройки), а в появившемся окне диалога щелкните Projects and Solutions | VC++ Directories (Проекты и решения | Каталоги VC++). Затем в выпадающем списке выберите Include files (Включаемые файлы) и добавьте в список каталогов следующие строки:
<OPENCV_HOME>\cxcore\include
<OPENCV_HOME>\cv\include
<OPENCV_HOME>\otherlibs\highgui
Вместо <OPENCV_HOME> нужно подставить реальный каталог, куда была установлена библиотека OpenCV.
Далее в выпадающем списке выберите Library files (Файлы библиотек) и добавьте в список директорий следующую строку:
<OPENCV_HOME>\lib
Здесь опять нужно заменить <OPENCV_HOME> на название каталога, куда была установлена OpenCV.
Библиотека OpenCV предоставляет довольно богатые средства для работы с растровыми изображениями и матрицами. Эти средства вынесены в подраздел OpenCV под названием CXCORE (дословно, ядро).
Чтобы использовать функции OpenCV, необходимо добавить в начало своего кода заголовочный файл cv.h, а в список подключаемых библиотек – cxcore.lib и cv.lib.
// Заголовочный файл OpenCV.
#include <cv.h> |
Если вы планируете использовать GUI-подсистему HighGUI (о ней я расскажу далее), то нужно также добавить включаемый файл highgui.h, а в список подключаемых библиотек – highgui.lib.
// Заголовочный файл HighGUI.
#include <highgui.h> |
В OpenCV информация об изображении хранится в структуре IplImage. Объявление данной структуры приведено ниже (несущественные для нас поля структуры опущены и заменены троеточиями).
typedef
struct _IplImage
{
...
// Число каналов в изображении (от одного до четырех).int nChannels;
...
// Глубина элемента изображения в битах.int depth;
...
// Начало в левом верхнем (==0) или в левом нижнем (==1) углу. int origin;
// Ширина изображения в пикселях. int width;
// Высота изображения в пикселях.int height;
// Прямоугольный регион интереса (если NULL, то все изображение целиком).struct _IplROI *roi;
...
// Размер данных изображения в байтах (==image->height*image->widthStep).int imageSize;
// Указатель на данные изображения.char *imageData;
// Размер ряда изображения в байтах (с учетом выравнивания).int widthStep;
...
}
IplImage; |
Как видим, структура IplImage является легковесной оберткой над данными изображения и не запрещает доступ к данным напрямую, что обеспечивает определенную гибкость. Изображение в общем случае может иметь от одного до четырех каналов, каждый из которых представляет собой двумерную матрицу пикселей (например, grayscale-изображение имеет 1 канал, RGB изображение имеет 3 канала, а RGBA – четыре). В изображении можно задать прямоугольный регион интереса roi, пиксели внутри которого участвуют в операциях, остальные пиксели изображения при этом игнорируются.
Регион интереса учитывается многими функциями, например функцией копирования изображения cvCopy().
void cvCopy( const CvArr* src, CvArr* dst, const CvArr* mask=NULL ); |
Создать изображение можно с помощью функции cvCreateImage(), ее прототип приведен ниже.
IplImage* cvCreateImage( CvSize size, int depth, int channels ); |
Параметр size задает размер изображения по горизонтали и вертикали (в пикселях). Параметр depth задает глубину (размерность) элемента изображения. Название для типа глубины формируется по схеме IPL_DEPTH_<bit_count>(S|U|F), где <bit_count> указывает число бит в элементе изображения, S и U задают соответственно знаковое или беззнаковое целое, а F – число с плавающей точкой. Например, тип IPL_DEPTH_8U соответствует unsigned char, IPL_DEPTH_16S соответствует short, IPL_DEPTH_32F соответствует float. Число каналов задается параметром channels.
Обращаться к элементам изображения в OpenCV принято с помощью макроса IPL_IMAGE_ELEM. Использование макроса вместо вызова функции позволяет экономить время. Это очередное проявление гибкости OpenCV, за счет которой обеспечивается быстродействие кода. Прототип макроса представлен ниже:
#define CV_IMAGE_ELEM( image, elemtype, row, col ) \
(((elemtype*)((image)->imageData + (image)->widthStep*(row)))[(col)]) |
Уничтожить изображение после того как оно стало ненужным можно функцией cvReleaseImage().
void cvReleaseImage( IplImage** image ); |
Ниже представлен небольшой пример кода, который позволяет создать изображение размером 320x240 с элементами типа unsigned char и тремя каналами, присвоить пикселю в нулевом ряду и десятом столбце красный цвет RGB(255, 0, 0), а затем уничтожить изображение. Обратите также внимание, как обыгрывается наличие в изображении трех каналов в макросе IPL_IMAGE_ELEM (последний параметр макроса умножается на 3, что с непривычки может смутить).
// Создадим изображение размером 320x240 с тремя каналами.
IplImage* pImage = NULL;
CvSize ImageSize = cvSize(320, 240);
pImage = cvCreateImage(ImageSize, IPL_DEPTH_8U, 3);
// Присвоим пикселю с координатами (10;0) красный цвет.
IPL_IMAGE_ELEM(pImage, uchar, 0, 10*3) = 0; // B
IPL_IMAGE_ELEM(pImage, uchar, 0, 10*3+1) = 0; // G
IPL_IMAGE_ELEM(pImage, uchar, 0, 10*3+2) = 255; // R// Уничтожим изображение.
cvReleaseImage(&pImage); |
Обратите внимание, как конструируется структруа CvSize – с помощью специальной функции-конструктора сvSize(). Для многих структур есть такие специальные функции-конструкторы, например функция cvRect() для структуры СvRect и функция cvScalar() для структуры CvScalar.
Работа с матрицами в OpenCV во многом аналогична работе с изображениями. Матрицу принято хранить в структуре CvMat. Cоздать матрицу можно функцией cvCreateMat(), ее прототип приведен ниже:
CvMat* cvCreateMat( int rows, int cols, int type ); |
Название типа элемента матрицы формируется по схеме CV_<bit_depth>(S|U|F)C<number_of_channels>, где <bit_depth> - число бит на элемент, <number_of_channels> – число каналов, S и U задают знаковое или беззнаковое целое, а F – число с плавающей точкой. Например, CV_32FC1 задает элемент матрицы в виде числа с плавающей точкой (float), и матрица будет иметь один канал. Вы могли уже заметить, что в матрице, как и в изображении может быть несколько каналов.
Обращение к элементу матрицы производится также через специальный макрос CV_MAT_ELEM.
#define CV_MAT_ELEM( mat, elemtype, row, col ) \
(*(elemtype*)CV_MAT_ELEM_PTR_FAST( mat, row, col, sizeof(elemtype))) |
Уничтожается матрица функцией cvReleaseMat()
void cvReleaseMat(CvMat ** pMat); |
Следующий пример кода показывает, как создать матрицу размером 3x1 (фактически создадим вектор), присвоить элементу матрицы в первом ряду и нулевом столбце значение 5.78, а затем уничтожить матрицу. Обратите внимание, что при использовании CV_MAT_ELEM есть одно отличие от макроса CV_IMAGE_ELEM – звездочка (оператор разыменования), которую можно забыть вставить, и потом удивляться, почему же компилятор ругается.
// Создадим матрицу (вектор) размером 3x1:
CvMat* pMat = NULL;
pMat = cvCreateMat(pMat, CV_32FС1, 3, 1);
// Присвоить элементу вектора (1,0) значение 5.78.// Обратите внимание на оператор разыменования (*) перед pMat.
CV_MAT_ELEM(*pMat, 1, 0) = 5.78;
// Уничтожаем матрицу (вектор).
cvReleaseMat(&pMat);
|
Вы могли уже заметить, что я обозначаю переменные, хранящие изображения, префиксом pImg, а матрицы – префиксом pMat. На мой взгляд, это помогает по имени переменной легко определить, что в ней хранится.
Многие функции OpenCV могут одинаково работать как с матрицами, так и с изображениями. Для этого они используют тип CvArr, который в зависимости от ситуации может быть либо матрицей, либо изображением.
typedef
void CvArr; |
Функция cvSet() позволяет заполнить элементы матрицы либо изображения скалярным значением CvScalar.
void cvSet( CvArr* arr, CvScalar value, const CvArr* mask=NULL ); |
Определение структуры CvScalar приведено ниже:
typedef
struct CvScalar
{
double val[4];
}
CvScalar; |
Как видим, тип CvScalar, хотя и задает скаляр, фактически представляет собой вектор с четырьмя компонентам. Это необходимо, чтобы за один вызов функции можно было заполнить все четыре канала изображения (матрицы).
// Создаем матрицу.
CvMat* pMat = cvCreateMat(CV_32FС1, 3, 3);
// Заполнить матрицу нулями.
cvSet(pMat, cvScalar(0)); |
Функция cvSetIdentity() позволяет заполнить элементы главной диагонали скалярным значением, а все остальные – нулями. Ей удобно пользоваться для инициализации единичной матрицы.
void cvSetIdentity( CvArr* mat, CvScalar value=cvRealScalar(1) ); |
Например:
// Создаем матрицу.
CvMat* pMatIdentity = cvCreateMat(CV_32FС1, 3, 3);
// Инициализируем единичную матрицу.
cvSetIdentity(pMatIdentity); |
Функция cvConvertScale() позволяет за одну операцию умножить каждый элемент массива на скаляр scale и прибавить к каждому элементу массива скаляр shift.
void cvConvertScale(const CvArr* src, CvArr* dst, double scale = 1, double shift =0); |
Вообще для OpenCV характерно стремление все оптимизировать и объединять операции в одну. Например, для умножения матриц можно пользоваться функцией cvGEMM(), которая позиционируется как обобщенная операция умножения матриц. Но помимо самого умножения двух матриц, она за одну операцию позволит вам умножить результат умножения матриц src1 и src2 на скаляр alpha и еще прибавить к нему третью матрицу src3, умноженную на скаляр beta: dst = src1*src2*alpha+src3*beta.
void cvGEMM( const CvArr* src1, const CvArr* src2, double alpha,
const CvArr* src3, double beta, CvArr* dst, int tABC=0 ); |
Конечно, с помощью функции cvGEMM() можно и просто перемножить пару матриц С=A*B. Для этого код должен быть таким:
cvGEMM(A, B, 1, NULL, 0, C); |
Напомню, что операция умножения матриц некоммутативна. Кроме того, размеры матриц должны быть согласованы (число столбцов первой матрицы должно быть равно числу строк во второй).
В OpenCV 1.0 существует набор функций для работы с окнами под названием HighGUI (что, наверное, расшифровывается как «High-Level GUI»). Пригодиться такой интерфейс может только в самых простых случаях, например, когда нужно создать простой оконный интерфейс для демонстрации результатов работы программы, и нецелесообразно тратить время и силы на создание полноценного оконного интерфейса с применением WinAPI, MFC или WTL. Ниже приведены прототипы основных функций HighGUI, которые позволяют создать именованное окно (обращение к окну всегда происходит по имени) и показать на нем изображение.
// Создает именованное окно.
int cvNamedWindow( constchar* name, int flags = CV_WINDOW_AUTOSIZE );
// Уничтожает именованное окно.void cvDestroyWindow( constchar* name );
// Отображает в именованном окне изображение.void cvShowImage( constchar* name, const CvArr* image );
// Ожидает некоторый период времени либо ожидает нажатия клавиши.int cvWaitKey(int delay = 0); |
Следующий пример кода показывает, как можно создать окно и вывести на него изображение:
IplImage* pImg; // Подразумевается, что здесь хранится изображение. cvNamedWindow("Image"); // Создать именованное окно. cvShowImage("Image", pImg); // Отобразить в окне изображение. cvWaitKey(0); // Ожидаем нажатие на клавишу. |
Кроме того в библиотеке HighGUI есть полезная функция cvLoadImage(), которую можно использовать для загрузки изображений из внешних графических файлов (JPG, PNG, BMP).
IplImage* cvLoadImage( constchar* filename, int iscolor = CV_LOAD_IMAGE_COLOR); |
Обычно загружаемые из файлов изображения являются цветными. Преобразовать цветное изображение в grayscale можно с помощью функции cvCvtColor(), указав в качестве параметра code константу CV_RGB2GRAY:
void cvCvtColor( const CvArr* src, CvArr* dst, int code ); |
| Оценка 535 Оценить
|
