Друга ищи не того, кто любезен с тобой, кто с тобой соглашается, а крепкого советника, кто полезного для тебя ищет и противится твоим необдуманным словам.
Здравствуйте, merge, Вы писали:
M>Но даже в Мск слышу часто: "у многих моих подружек смартфоны". Это не эстерика, просто слушаю от дочки в формате "ну что делать мне? у всех есть"
M>там начинается проседание в учебе и дальше снижение интереса ко всему кроме экшнов в играх.
M>как и на что вы рассчитываете в плане детей?
Кароч тема такая. За зеркалом свёрток есть.

Вот смотри, за годы на RSDN обсудили огромное количество программ и методик помогающих в обучении. Я сам предлагал что-то, и другие предлагали, сами создавали топики. Всегда один и тот же вопрос, как обучиться тому-то и тому-то.
Я лично не делю людей именно на детей и взрослых. Если взрослый не может обучиться, то и дети не смогут.
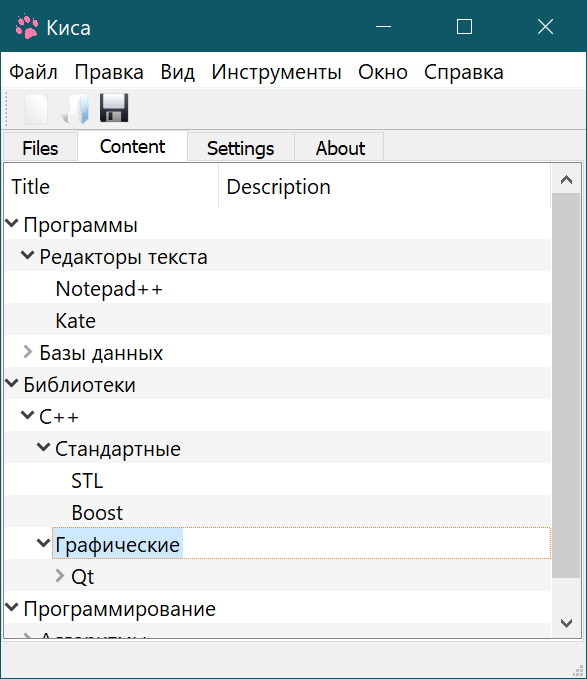
Теперь про смартфоны. Последний мой проект, который в будущем будет удалён.
https://kisa.biz/teacher/download.ru.html
Почему? Потому что на смену нулевой версии будет первая версия.
Хотя это тоже только временная версия, потому что чтобы сделать что-то нужно научиться, а чтобы научиться нужно сделать что-то. И чтобы выйти из замкнутого круга я делаю улучшения поэтапно.
Почему я привёл в пример нулевую версию? Потому что она там не только для десктопов, но и для смартфонов на андроид. Смартфоны это не зло, смартфоны это благо. В смартфонах просто отвратительное программное обеспечение, но это могут исправить программисты.
Я исхожу из идеи, что у людей нет правильной методики обучения, вот почему они не могут ничего толком выучить. Поскольку создавать полноценный граф слишком муторно, я решил создать древовидный граф, который сразу весь читается в оперативную память. Учитывая, что мегабайт это примерно миллион байт, оказалось, что даже граф с миллионом элементов потребляет не так много оперативной памяти. То есть нет смысла переходить на базы данных, пока не достигнут предел.
Смысл в том, что я могу зарядить даже на днищенском компьютере и 10 миллионов элементов, а на не совсем уж днищенском 100 миллионов элементов включая современные смартфоны. А вот чтобы человеку сознательно выучить иерархию хотя бы из 100 тысяч элементов, то я даже затрудняюсь сколько это займёт времени. А ведь даже 1 тысяча элементов делает людей специалистами в малой области знаний.
Я пошёл по пути учёных оставивших свой след в истории. То есть учёл, что в кратковременную память человека
не влезает болье 5 односложных слов. Кстати, по данным википедии это технология от
Bell Labs, привет C, C++ и Unix, для которых она по сути и была обкатана. Просто лично меня волнуют только односложные слова.
Джордж Миллер во время своей работы в компании Bell Laboratories провёл ряд экспериментов, целью которых было изучение параметров памяти операторов. В результате опытов он обнаружил, что кратковременная память человека способна запоминать в среднем девять двоичных цифр, восемь десятичных цифр, семь букв алфавита и пять односложных слов — то есть человек способен одновременно помнить 7 ± 2 элементов.
На этом собственно и построен "мой" новый принцип обучения запихивать в элемент древовидного списка не более пяти подэлементов. То есть прототип ноль смог успешно проверить лишь
кривую забывания Германа Эббингауза. А вот дальше нужно проверять следующие принципы.
На данном этапе моих исследований я так же считаю, что
гипотезы Крашена об усвоении языка являются очень перспективными и некоторые методики обучения будут строиться вокруг них.
То есть в чём разница к примеру между обычным учителем и мной? Разница в том, что я в данном случае методист. И я хочу чтобы люди обучались со смартфонов в том числе автономно без интернета. Для этого я даже придумал игровую форму программы включая экшн который в том числе в особенности очень любят домохозяйки (три в ряд, зума и прочие), но не только, то есть учиться будет в кайф. Но как говорится идеи без реализации ничего не стоят.
Потому хотя я сейчас не слишком озабочен другими людьми, но потихоньку набираю свой граф. Пока что я провожу опыты над простыми текстовыми форматами, без бинарников, xml, json и баз данных.
Кстати, стоит отметить, что множество других способов обучения обсуждавшихся в том числе на RSDN ранее провалились. А чего там только не было, и личные базы знаний и всякие хитрые методики. Но там нельзя было использовать в автоматизированном режиме методы мышления из науки логики, вроде разбора (анализа), сбора (синтеза), сравнения и других, тогда как в древовидном списке это уже возможно, пусть и не так хорошо как в полноценном графе.
Но боятся нужно не того, что у меня не получится, а того, что у меня получится. Я уже много раз писал и напишу ещё раз. Предположим моя методика прокатила. Появилось куча людей, которые по знаниям превосходят даже старых специалистов. Оно вам надо? Это же считай обесценить целый пласт профессий. Какой-нибудь дебильный школьник проходит мой курс и ... он становится лучше вас в этой области. Здесь не стоит забывать, что молодость мозга тоже влияет на обучаемость, а вся классификация уже будет произведена за людей, что позволит сэкономить им кучу времени, которое например я или вы вынуждены сейчас тратить напрягая мозги.
Взять тот же СССР, выучили кучу инженеров, а потом после развала их пнули с заводов и они стали чуть ли не самой низкооплачиваемой профессией. И только сейчас, когда многие уже умирают и даже на пенсии не могут работать потихоньку будет наступать дефицит специалистов. Тоже самое с курсами для программистов, которые вбрасывают кучу неумех на рынок. А что если бы все курсы были эффективны? А что если бы все курсы были в смартфоне и не нужен был учитель? Куча джунов на рынке не так фатальна как куча синьоров. Это как грамотность, которая важна была в древние времена и могла приносить прибыль, но не сейчас, когда в развитых странах все поголовно грамотны.
Но посмотрим, не от хорошей жизни я этим занимаюсь. Для меня как и для любого нормального человека проще купить программу, подписку или ещё какую хрень чтобы сэкономить время, а не изобретать технологии и методики самостоятельно. Но раз ничего нет, то приходится заниматься. Кто если не я? Пусть даже и куча вариантов уже отпала как не работающие. На проверку новой методики всё равно уйдёт кучу времени, потому что по Миллеру все данные надо переделывать в односложные слова и размещать так, чтобы их можно было сразу извлечь в кратковременную память. А у Крашена ещё и генерить input + 1 и использовать другие принципы.
В общем я хочу сказать, что обсуждение опять идёт не в стиле как решить проблему, а в стиле, что она есть. Ну да, она есть.





