Здравствуйте, stalcer, Вы писали:
S>Здравствуйте, GlebZ, Вы писали:
GZ>>К сожалению, я так как-раз и не считаю. <поскипано>
S>Дык, приведи пример лучшего режима.
Раздели транзакции по следующему принципу:
1. Транзакции read-only snapshot. Такие транзакции не открывают транзакции на БД, и можно их использовать по версионному принципу как у тебя описано. Она будет корректна на какой-то момент времени. Удобно для работы отчетов. (если тебе очень хочется ее сделать, на здоровье).
2. Транзакции read-only read-commited. Такие транзакции не открывают транзакций на БД, но через них можно передавать изменения в режиме реального времени.
3. Оптимистические транзакции. Фаулер их достаточно описал. В случае бухгалтерии — маловероятно наличие большого кол-ва изменений в одной транзакции. Поэтому механизма сброса на диск — не особо надо. Транзакция БД открывается только на момент сброса транзакции на БД.
4. Пессимистические. Здесь уже есть тот вариант который я описал про версионные (но достаточно тормозные), либо ты предоставишь пользователю просто возможность заблокировать данные которые он будет изменять. Если произошла попытка блокировки уже заблокированного объекта, пользователю предоставляется информация кто работает с данным объекта. Так, чтобы он мог это сообщить пользователю. Тогда ты перекладываешь все на прикладника. Ему значительно проще, поскольку он знает что пользователю в данный момент нужно, и может гибче управлять ими. Предусмотреть все варианты прикладник врядли сможет. Так что можно называть этот ее псевдопессимистической. Второй вариант не должен отменять Оптимистическую транзакцию. Это обеспечит согласованность данных.
Здравствуйте, Sinclair, Вы писали:
S>Кто делает? Какой язык?
1С, например. Язык — в смысле скрипт.
S>Не, тут поинт в том, чтобы специально разрабатывать интерфейс с учетом минимизации общения между клиентом и сервером.
Да, да. Ето и есть основная мысль.
S>Бинарность передачи данных сама по себе — не панацея.
Это я для примера привел.
S>Это все делается в рамках web-клиента без особых проблем.
Это как?
S>Многие особенности, присущие толстым клиентам, на практике малопригодны с точки зрения пользователя. Т.е. например воспроизвести всю MS VS 2005 как веб-клиента нереально. Все эти dockable tabbed interface и все такое... Но это интерфейс, ориентированный на очень специальную таргет группу. Нормальным людям, клиентам бизнес приложений, все это только вредит.
Это понятно.
S>Более того, пересмотр самой модели взаимодействия приложения с пользователем в пользу "вебнутого" интерфейса помогает повысить масштабируемость приложения и улучшить user experience. Первое — потому, что там ты вынужден избегать лишних зависимостей и непроизводительной нагрузки; второе — потому, что ты вынужден тщательнее заботиться о реализации use-cases вместо хаотического запихивания всех возможностей в правую кнопку и тулбары.
Хочу чтобы было так:
А не так:
S>Я больше склоняюсь к тому, что при проектировании клиента надо очень критически относиться к решениям, диктуемым определенной технологией разработки. Программисту очень легко забыть о том, что приложение — не упражнение по кодингу, а средство решения проблем его пользователей.
Здравствуйте, GlebZ, Вы писали:
GZ>Раздели транзакции по следующему принципу: GZ>1. Транзакции read-only snapshot. Такие транзакции не открывают транзакции на БД, и можно их использовать по версионному принципу как у тебя описано. Она будет корректна на какой-то момент времени. Удобно для работы отчетов. (если тебе очень хочется ее сделать, на здоровье).
Читать-то из базы все равно нужно. SQL запросы тоже идут в контексте SQL транзакции. И как ты сказал "snapshot" удобно не только для отчетов, но и практически для любого рассчета.
GZ>2. Транзакции read-only read-commited. Такие транзакции не открывают транзакций на БД, но через них можно передавать изменения в режиме реального времени.
Зачем они вообще нужны, read-commited в смысле?
Опять же, read-only или не read-only — разницы нет никакой.
GZ>3. Оптимистические транзакции. Фаулер их достаточно описал. В случае бухгалтерии — маловероятно наличие большого кол-ва изменений в одной транзакции. Поэтому механизма сброса на диск — не особо надо. Транзакция БД открывается только на момент сброса транзакции на БД.
Ага.
Во первых, "маловероятно", как выяснилось в юморе, — это только с точки зрения бухгалтера — "не бывает", а с точки зрения программиста — "бывает".
Во вторых, ты все запросы сам что ли выполнять будешь, в кэше индексы строить и т.д. Запросы ведь это как раз тот механизм, который позволяет сделать из огромного объема данных первичную выборку, т.е. снизить обрабатываемый на сервере приложения объем информации.
GZ>4. Пессимистические. Здесь уже есть тот вариант который я описал про версионные (но достаточно тормозные), либо ты предоставишь пользователю просто возможность заблокировать данные которые он будет изменять. Если произошла попытка блокировки уже заблокированного объекта, пользователю предоставляется информация кто работает с данным объекта. Так, чтобы он мог это сообщить пользователю. Тогда ты перекладываешь все на прикладника. Ему значительно проще, поскольку он знает что пользователю в данный момент нужно, и может гибче управлять ими. Предусмотреть все варианты прикладник врядли сможет. Так что можно называть этот ее псевдопессимистической. Второй вариант не должен отменять Оптимистическую транзакцию. Это обеспечит согласованность данных.
Это часть подсистемы GUI. Выразимся по другому: У нас нет пессимистических транзакций, но формочки вот так блокировать умеют. Этот механизм можно надстроить над уровнем, который я описываю. Тем более, раз здесь предполагается блокирование надолго, то использовать SQL блокировки, создавая тем самым длительные транзакции, — нельзя.
И потом, я же не запрещаю программисту в рассчетах вручную блокировать, если хочет — наздоровье.
Здравствуйте, stalcer, Вы писали: S>1С, например. Язык — в смысле скрипт.
Гм. Так это же совсем про другое. Скрипт — это же средство расширения функционала прикладными программистами. Он сам никак не связан с моделью взаимодействия. S>>Это все делается в рамках web-клиента без особых проблем. S>Это как?
В смысле как? Ты что, никогда сайтов с менюшками не видел? S>>Более того, пересмотр самой модели взаимодействия приложения с пользователем в пользу "вебнутого" интерфейса помогает повысить масштабируемость приложения и улучшить user experience. Первое — потому, что там ты вынужден избегать лишних зависимостей и непроизводительной нагрузки; второе — потому, что ты вынужден тщательнее заботиться о реализации use-cases вместо хаотического запихивания всех возможностей в правую кнопку и тулбары. S>Хочу чтобы было так: S> S>А не так: S>
Внимание, вопрос: почему ты хочешь так? Ты уверен, что так, как ты хочешь — удобнее пользователям? S>Наезд не понял .
Это не наезд. Это призыв разрабатывать интерфейсы, удобные пользователю. Вот, к примеру, Inductive User Interface гораздо легче реализовать в веб-модели, и при этом он считается более удобным, чем классический deductive interface. То, что ты приводишь в примере, больше похоже на deductive interface. Поэтому, прежде чем задаваться вопросом "как его реализовать", хочется задаться вопросом "зачем его реализовывать", и "его ли надо реализовывать".
... << RSDN@Home 1.1.4 beta 4 rev. 347>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Гм. Так это же совсем про другое. Скрипт — это же средство расширения функционала прикладными программистами. Он сам никак не связан с моделью взаимодействия.
Скрипт — это язык программирования, пусть и простенький. И вопрос в том, существуют ли в системе прикладные программы, выполняющиеся на клиенте. Потому что если существуют, то это очень неудобно и прикладной программист будет ныть по поводу "почему эту функцию на сервере можно вызвать, а на клиенте — нет". Поэтому я и хочу обойтись без программ на клиенте в принципе.
S>В смысле как? Ты что, никогда сайтов с менюшками не видел? S>Внимание, вопрос: почему ты хочешь так? Ты уверен, что так, как ты хочешь — удобнее пользователям?
Менюшки видел. Я не про то. Кроме менюшек есть более важные средства — средства работы с данными: сетки всякие, DB-Edit'ы, мастер-детальные сетки и т.д. Ну и как это в HTML страничке представлят. С учетом большого объекма информации в сетках (скроллинга).
WinForms интерфейс ИМХО богаче по выразительным средствам.
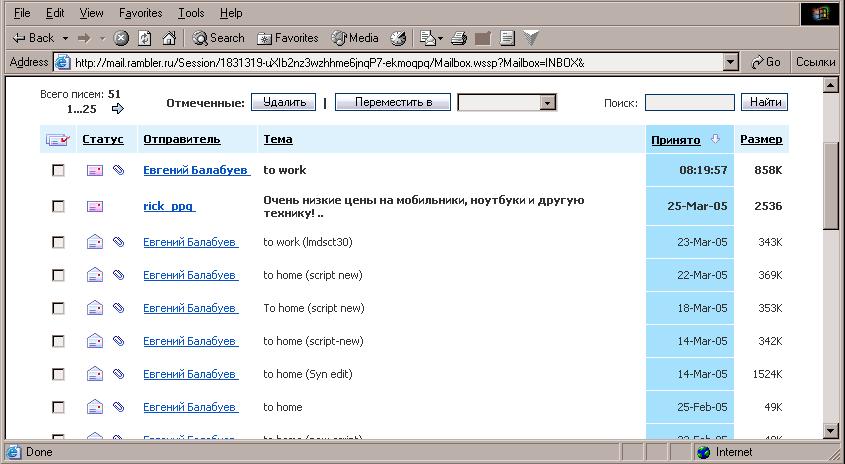
А пользователю ИМХО (даже не ИМХО, а по опыту работы знаю) удобнее такие сетки, чем интерфейс типа почты на рамблере, которую я показал, в котором при любом действии скроллинг в начало страницы убегает . Потому что тетка сидит, одним глазом в листок бумаги смотрит а другим в монитор и быстро-быстро-быстро вбивает данные.
S>Это не наезд. Это призыв разрабатывать интерфейсы, удобные пользователю.
Да я и не против подумать о пользователе.
S>Вот, к примеру, Inductive User Interface гораздо легче реализовать в веб-модели, и при этом он считается более удобным, чем классический deductive interface. То, что ты приводишь в примере, больше похоже на deductive interface. Поэтому, прежде чем задаваться вопросом "как его реализовать", хочется задаться вопросом "зачем его реализовывать", и "его ли надо реализовывать".
Это несколько ортогонально к сеткам и DB-Edit'ам. Очень интересно. Где почитать.
Здравствуйте, stalcer, Вы писали:
S>Менюшки видел. Я не про то. Кроме менюшек есть более важные средства — средства работы с данными: сетки всякие, DB-Edit'ы, мастер-детальные сетки и т.д. Ну и как это в HTML страничке представлят. С учетом большого объекма информации в сетках (скроллинга).
Гм. Ты сходил на maps.google.com? Там не то что сетка — картинка неограниченного размера скроллится! И ничего. Так что master/detail и сетки с load-on-demand — вовсе не предел технологии. Даже в MSDN была статья про то, как сделать грид с динамической подгрузкой. S>А пользователю ИМХО (даже не ИМХО, а по опыту работы знаю) удобнее такие сетки, чем интерфейс типа почты на рамблере, которую я показал, в котором при любом действии скроллинг в начало страницы убегает . Потому что тетка сидит, одним глазом в листок бумаги смотрит а другим в монитор и быстро-быстро-быстро вбивает данные.
Ничему не противоречит. То, что у рамблера неудачный интерфейс, не означает, что надо ему детально следовать. S>>Вот, к примеру, Inductive User Interface гораздо легче реализовать в веб-модели, и при этом он считается более удобным, чем классический deductive interface. То, что ты приводишь в примере, больше похоже на deductive interface. Поэтому, прежде чем задаваться вопросом "как его реализовать", хочется задаться вопросом "зачем его реализовывать", и "его ли надо реализовывать". S>Это несколько ортогонально к сеткам и DB-Edit'ам. Очень интересно. Где почитать.
Ну, оригинал живет в MSDN. Перевод
Мое личное мнение, что веб интерфейс уместно использовать для интернет проектов, типа интернет-магазинов, чтобы юзер ничего не устанавливал, а сразу работал. А для корпоративной системы, работающей в локальной сети, ИМХО лучше обыкновенные формочки. И компоненты для них разрабатывать удобней, чем вся эта муть с JavaScript и т.п. В конечном итоге все упирается в качество. И то и то можно хорошо сделать (будем надеяться).
Так что я буду делать формочки. А про Inductive User Interface посмотрю обязательно.
Здравствуйте, stalcer, Вы писали:
S>Здравствуйте, GlebZ, Вы писали:
GZ>>Раздели транзакции по следующему принципу: GZ>>1. Транзакции read-only snapshot. Такие транзакции не открывают транзакции на БД, и можно их использовать по версионному принципу как у тебя описано. Она будет корректна на какой-то момент времени. Удобно для работы отчетов. (если тебе очень хочется ее сделать, на здоровье).
S>Читать-то из базы все равно нужно. SQL запросы тоже идут в контексте SQL транзакции. И как ты сказал "snapshot" удобно не только для отчетов, но и практически для любого рассчета.
см. Ниже
GZ>>2. Транзакции read-only read-commited. Такие транзакции не открывают транзакций на БД, но через них можно передавать изменения в режиме реального времени.
S>Зачем они вообще нужны, read-commited в смысле?
Когда пользователь работает в snapshot транзакции — он работает в актуальных данных только на конкретный момент. То есть, он может работать в неактуальными данными и не сможет их даже обновить не закрывая транзакцию.
Например: первый продавец решил начать транзакцию продажи, открыл форму и посмотрел что товара достаточно после чего ушел обедать, второй продавец в это время взял и продал весь товар. Первый продавец уже сытый позвонил клиенту, сказал что дескать все ок — наличие товара проверено. И тут при проходе транзакции — получается что у него неактуальные данные. Он даже не может их обновить, так как — для этого нужно сбрасывать форму. В результате он получит ошибку транзакции, притом что вся логика проверки(которая работает в режиме устаревшей транзакции) говорит что все OK. И проверить в чем дело — никак нельзя. S>Опять же, read-only или не read-only — разницы нет никакой.
Cходу не скажу, но по моему разница есть даже в твоем случае.
GZ>>3. Оптимистические транзакции. Фаулер их достаточно описал. В случае бухгалтерии — маловероятно наличие большого кол-ва изменений в одной транзакции. Поэтому механизма сброса на диск — не особо надо. Транзакция БД открывается только на момент сброса транзакции на БД.
S>Ага. S>Во первых, "маловероятно", как выяснилось в юморе, — это только с точки зрения бухгалтера — "не бывает", а с точки зрения программиста — "бывает".
Ну сделаешь оптимизацию. Будешь сериализовать изменения. S>Во вторых, ты все запросы сам что ли выполнять будешь, в кэше индексы строить и т.д. Запросы ведь это как раз тот механизм, который позволяет сделать из огромного объема данных первичную выборку, т.е. снизить обрабатываемый на сервере приложения объем информации.
В данном случае мы говорим не о запросах, а об изменениях. И эти изменения должны быть согласованные. Предлагаю тебе все-таки вернуться к декларативному языку описания объекта. В него закладываются правила которые выполняются как на уровне сервера приложений, так и на уровне БД. Если нужно работать с большим объемом данных, к сожалению я альтернативы БД не вижу. Возможно часть бизнес правил проверять запросами БД. Это притормозит систему, зато гарантирует корректную ошибку.
GZ>>4. Пессимистические. Здесь уже есть тот вариант который я описал про версионные (но достаточно тормозные), либо ты предоставишь пользователю просто возможность заблокировать данные которые он будет изменять. Если произошла попытка блокировки уже заблокированного объекта, пользователю предоставляется информация кто работает с данным объекта. Так, чтобы он мог это сообщить пользователю. Тогда ты перекладываешь все на прикладника. Ему значительно проще, поскольку он знает что пользователю в данный момент нужно, и может гибче управлять ими. Предусмотреть все варианты прикладник врядли сможет. Так что можно называть этот ее псевдопессимистической. Второй вариант не должен отменять Оптимистическую транзакцию. Это обеспечит согласованность данных.
S>Это часть подсистемы GUI. Выразимся по другому: У нас нет пессимистических транзакций, но формочки вот так блокировать умеют. Этот механизм можно надстроить над уровнем, который я описываю. Тем более, раз здесь предполагается блокирование надолго, то использовать SQL блокировки, создавая тем самым длительные транзакции, — нельзя.
Насчет GUI — по моему, не есть гуд. С одним объектом могут работать множество GUI форм. Каждая форма может редактировать одновременно сразу несколько объектов. Поэтому тут связь весьма неоднозначная. Что касается SQL блокировок — то нужен альтернативный механизм. Иначе прикладник будет открывать именно SQL транзакцию(если для него это будет возможно). Это уже проходил. S>И потом, я же не запрещаю программисту в рассчетах вручную блокировать, если хочет — наздоровье.
Должен быть механизм единый для всех сессий и серверов.(snapshot — транзакции не подойдут для такого так как не могут предоставлять информацию для различных транзакций)
Здравствуйте, stalcer, Вы писали:
GZ>>Может ли объект хранить другие аттрибуты, которые зависят от транзакционных?
S>Ну, никто не запрещает. Наверное это плохо. Я сам пока в сомнениях .
Это дополнительный механизм.
GZ>>Здесь мне кажется, лучше пробежать. Ты занимаешь ресурсы — объектами которые уже никому никогда не понадобятся.
S>Хе. Доменный язык у меня — со сборшиком мусора (аля C#). И пока сборка мусора не пройдет — память фактически будет занята. Более того только сборщик мусора может сказать есть ли на объект ссылки или — нет. Поэтому, алгоритм удаления объектов из сессионного кэша тесно связан со сборкой мусора, и запускается как ее часть. S>Таким образом получается, что фактически ресурсы зависят от периодичности сборки мусора, а не от периодичности транзакций.
GZ>>И еще сразу вопрос: После отката транзакции — остаются или не остаются объекты DSL c ссылками.
S>В смысле, остаются ли ссылки на объекты, дык — это дело прикладного программиста. Хочет держать объект (хранить ссылку на него в глобальной переменной) — пусть держит. Может он его овигенно сложным расчетом выбрал (состояние полей — да могут поменяться, но объект выбирать будет уже не нужно). Вобщем — дело программиста.
GZ>>Если объект нельзя сбросить(перечитать) в случае отката (100% протухшие данные), то нужно что-то делать. Или я чего-то не усек.
S>В случае отката, так же как и в случае коммита, номер транзакции увеличивается. И все данные будут невалидными. И они при необходимости — перечитаются. А что значит "нельзя сбросить(перечитать)" — я не понял, всегда можно перечитать.
Если программер содержит значение (что часто бывает) которое было связано со старым значением объекта. То это уже ошибка, притом которая практически не может быть выявлена. Прикладнику придется выделять два поведения на нетранзакционный объект — при успешной транзакции, и при откате.
GZ>>правда по опыту знаю, что они постепенно приводятся к стандартизованному виду.
S>Хм. Читаю Фаулера — вижу одно. Смотрю 1С — другое. Смотрю "Эталон" — третье. ИМХО просто нет оптимального решения — вот и извращается кто как может .
Оптимальные решения бывают применительно к конкретной задаче. Поэтому лучше забирать только лучшее. А лучшее можно только получив знание о всех существующих. Здесь я не помошник. Единственное подобное решение в котором я участвовал и которое знаю я уже привел (Re[20]: Опять валидация данных
)
GZ>>Что касается непротиворечивости, то остался вопрос по пессимистическим транзакциям (будут или нет), масштабируемости БД и еще пожалуй, момент отката транзакций.
S>Про пессимистические транзакции: я же не весь фреймворк описал, это только один логический уровень. Так сказать базовый. Он больше для рассчетов (бизнес логики) подходит. Над ним уже нужно надстраивать всякие конструкторы формочек и т.д. И если для формочек нужны пессимистические транзакции — то там их и сделаем (как надстройку над этим уровнем).
Мне не очень нравится идея насчет механизма GUI. Почему я уже писал...
S>- Но, полностью кэш очищать принципиально нельзя, так как прикладная программа может держать на объекты ссылки, и такие объекты должны находиться в IdentityMap. Это нужно для чистоты концепции, так сказать.
После транзакции — IdentityMap уже никому не нужен. Все изменения уже сделаны либо откачены. Все объекты становятся стандартными. S>- Более того, освобождение ресурсов, как я сказал выше, происходит только во время сборки мусора, поэтому по завершению транзакции делать ничего не нужно. Хотя, можно подумать на счет более плотной интеграции сборщика мусора с механизмом транзакций в этом смысле.
Насчет интеграции согласен. Хотя и более важен размер занятых ресурсов. Осталось решить что такое ресурсы?(опер память, узкие места с большой загрузкой процессора при работе с версиями). Я думаю, полностью без профайлинга не решишь.
Здравствуйте, GlebZ, Вы писали:
GZ>Если программер содержит значение (что часто бывает) которое было связано со старым значением объекта. То это уже ошибка, притом которая практически не может быть выявлена. Прикладнику придется выделять два поведения на нетранзакционный объект — при успешной транзакции, и при откате.
Если не хочет — пусть так не делает.
S>>- Но, полностью кэш очищать принципиально нельзя, так как прикладная программа может держать на объекты ссылки, и такие объекты должны находиться в IdentityMap. Это нужно для чистоты концепции, так сказать.
GZ>После транзакции — IdentityMap уже никому не нужен. Все изменения уже сделаны либо откачены. Все объекты становятся стандартными.
И появляется дыра в системе в виде возможности существования двух реплик одного по сути хранимого объекта. Т.е. источник потенциальных ошибок.
S>>- Более того, освобождение ресурсов, как я сказал выше, происходит только во время сборки мусора, поэтому по завершению транзакции делать ничего не нужно. Хотя, можно подумать на счет более плотной интеграции сборщика мусора с механизмом транзакций в этом смысле. GZ>Насчет интеграции согласен. Хотя и более важен размер занятых ресурсов. Осталось решить что такое ресурсы?(опер память, узкие места с большой загрузкой процессора при работе с версиями). Я думаю, полностью без профайлинга не решишь.
Мы же говорим об убирании из кэша объектов после завершения транзакции. С этой точки зрения ресурсы — это место в кэше, т.е. память.
Здравствуйте, GlebZ, Вы писали:
S>>Зачем они вообще нужны, read-commited в смысле? GZ>Когда пользователь работает в snapshot транзакции — он работает в актуальных данных только на конкретный момент. То есть, он может работать в неактуальными данными и не сможет их даже обновить не закрывая транзакцию. GZ>Например: первый продавец решил начать транзакцию продажи, открыл форму и посмотрел что товара достаточно после чего ушел обедать, второй продавец в это время взял и продал весь товар. Первый продавец уже сытый позвонил клиенту, сказал что дескать все ок — наличие товара проверено. И тут при проходе транзакции — получается что у него неактуальные данные. Он даже не может их обновить, так как — для этого нужно сбрасывать форму. В результате он получит ошибку транзакции, притом что вся логика проверки(которая работает в режиме устаревшей транзакции) говорит что все OK. И проверить в чем дело — никак нельзя.
Я уже говорил, что для прикладника "framework-транзакции" — это системные транзакции, а не бизнес транзакции. Так что "транзакция продажи" должна быть реализована на основе нескольких системных транзакций (каждая из которых будет сериализованной). Т.е.:
— Открыл форму (читай, скачал данные) — это одна системная транзакция
— Запустил расчет продажи — вторая.
И смотри ниже про GUI-блокировки.
S>>Во вторых, ты все запросы сам что ли выполнять будешь, в кэше индексы строить и т.д. Запросы ведь это как раз тот механизм, который позволяет сделать из огромного объема данных первичную выборку, т.е. снизить обрабатываемый на сервере приложения объем информации. GZ>В данном случае мы говорим не о запросах, а об изменениях. И эти изменения должны быть согласованные. Предлагаю тебе все-таки вернуться к декларативному языку описания объекта. В него закладываются правила которые выполняются как на уровне сервера приложений, так и на уровне БД. Если нужно работать с большим объемом данных, к сожалению я альтернативы БД не вижу. Возможно часть бизнес правил проверять запросами БД. Это притормозит систему, зато гарантирует корректную ошибку.
Я не про бизнес правила здесь говорю. А про согласованность данных с точки зрения текущей транзакции, например:
// Пусть obj.Name изначально равно "aaa"
obj.Name = "bbb";
cursor = #oql select x from SomeObjects x where x.Name = "aaa";
Т.е. меняем obj.Name и делаем запрос. Вопрос: должен ли, собственно, obj попасть в результаты запроса? Ответ — нет. Потому что непосредственно перед запросом поле Name было изменено. Так вот, как добиться этого эффекта не сбрасывая накопившиеся изменения в базу непосредственно перед выполнением запроса?
S>>Это часть подсистемы GUI. Выразимся по другому: У нас нет пессимистических транзакций, но формочки вот так блокировать умеют. Этот механизм можно надстроить над уровнем, который я описываю. Тем более, раз здесь предполагается блокирование надолго, то использовать SQL блокировки, создавая тем самым длительные транзакции, — нельзя. GZ>Насчет GUI — по моему, не есть гуд. С одним объектом могут работать множество GUI форм. Каждая форма может редактировать одновременно сразу несколько объектов. Поэтому тут связь весьма неоднозначная.
Хорошо, уточню: У нас нет пессимистических транзакций, но формочки вот так блокировать объекты (не строчки грида) умеют.
GZ>Что касается SQL блокировок — то нужен альтернативный механизм. Иначе прикладник будет открывать именно SQL транзакцию(если для него это будет возможно). Это уже проходил.
Это понятно. И как раз специальный механизм позволяет разбить одну бизнес транзакцию, типа "транзакцию продажи" на несколько системных.
S>>И потом, я же не запрещаю программисту в рассчетах вручную блокировать, если хочет — наздоровье. GZ>Должен быть механизм единый для всех сессий и серверов.(snapshot — транзакции не подойдут для такого так как не могут предоставлять информацию для различных транзакций)
Получается два механизма блокировок:
— Обычные блокировки, которые используются при расчетах, например, заблокировал все табеля и гуляй по ним циклом, делай любые изменения. Я думаю, что для этого подойдут обыкновенные SQL блокировки (select for update).
— И GUI-блокировки объектов. Для которых, как ты сам сказал нужен "альтернативный механизм". Я бы добавил, что нужен механизм блокировок, которые умеют переживать границы системных транзакций.
Оба механизма — глобальные, т.е. для всех сессий и всех серверов.
И еще раз повторю: я большое внимание уделяю именно рассчетам (бизнес логике). И все что я описывал (кроме GUI) относится к одному лишь логическому уровню фреймворка, который я называю — вычислительная среда. Только над ним строится подсистема GUI со своим механизмом блокировок. А глобальный этот механизм или нет — это уже дело техники.
И с точки зрения уровня вычислительной среды наличие двух разных типов транзакций (оптимистических и пессимистических) — это прямое противоречие. Вот ответь на вопрос: Те данные, которые заблокировала пессимистическая транзакция (прочитав их), другая оптимистическая может прочитать? Или она должна повеситься и ждать?
Здравствуйте, stalcer, Вы писали:
S>>>- Но, полностью кэш очищать принципиально нельзя, так как прикладная программа может держать на объекты ссылки, и такие объекты должны находиться в IdentityMap. Это нужно для чистоты концепции, так сказать.
GZ>>После транзакции — IdentityMap уже никому не нужен. Все изменения уже сделаны либо откачены. Все объекты становятся стандартными.
S>И появляется дыра в системе в виде возможности существования двух реплик одного по сути хранимого объекта. Т.е. источник потенциальных ошибок.
Нет. Все остается в той-же степени как и было. Ты же сам писал — IdentityMap один на всю сессию. Так что это получается один из объектов сессионного кэша.
Здравствуйте, stalcer, Вы писали:
S>Я уже говорил, что для прикладника "framework-транзакции" — это системные транзакции, а не бизнес транзакции. Так что "транзакция продажи" должна быть реализована на основе нескольких системных транзакций (каждая из которых будет сериализованной). Т.е.: S>- Открыл форму (читай, скачал данные) — это одна системная транзакция S>- Запустил расчет продажи — вторая. S>И смотри ниже про GUI-блокировки.
Если говорить по твоим словам — объекты между системными транзакциями перегружаются Я начал тормозить.
S>Я не про бизнес правила здесь говорю. А про согласованность данных с точки зрения текущей транзакции, например:
S>
S> // Пусть obj.Name изначально равно "aaa"
S> obj.Name = "bbb";
S> cursor = #oql select x from SomeObjects x where x.Name = "aaa";
S>
S>Т.е. меняем obj.Name и делаем запрос. Вопрос: должен ли, собственно, obj попасть в результаты запроса? Ответ — нет. Потому что непосредственно перед запросом поле Name было изменено. Так вот, как добиться этого эффекта не сбрасывая накопившиеся изменения в базу непосредственно перед выполнением запроса?
Как и всегда, пропуская чтение объекта который уже загружен. Считываешь его гуид, и если он есть в hash, то пропускаешь.
S>>>Это часть подсистемы GUI. Выразимся по другому: У нас нет пессимистических транзакций, но формочки вот так блокировать умеют. Этот механизм можно надстроить над уровнем, который я описываю. Тем более, раз здесь предполагается блокирование надолго, то использовать SQL блокировки, создавая тем самым длительные транзакции, — нельзя. GZ>>Насчет GUI — по моему, не есть гуд. С одним объектом могут работать множество GUI форм. Каждая форма может редактировать одновременно сразу несколько объектов. Поэтому тут связь весьма неоднозначная.
S>Хорошо, уточню: У нас нет пессимистических транзакций, но формочки вот так блокировать объекты (не строчки грида) умеют.
На каком уровне. Если ты уровень GUI переместишь на клиента — то об этом никто не узнает. Блокировки должны быть на уровне бизнес-логики. Именно там они и используются.
GZ>>Что касается SQL блокировок — то нужен альтернативный механизм. Иначе прикладник будет открывать именно SQL транзакцию(если для него это будет возможно). Это уже проходил.
S>Это понятно. И как раз специальный механизм позволяет разбить одну бизнес транзакцию, типа "транзакцию продажи" на несколько системных.
Не все так просто. Не каждую транзакцию можно разбить на несколько системных. Зачастую просто идет накопление изменений, которые поодиночке сбрасывать нельзя. Чтобы не потерять атомарность изменений и согласованность базы.
S>>>И потом, я же не запрещаю программисту в рассчетах вручную блокировать, если хочет — наздоровье. GZ>>Должен быть механизм единый для всех сессий и серверов.(snapshot — транзакции не подойдут для такого так как не могут предоставлять информацию для различных транзакций)
S>Получается два механизма блокировок: S>- Обычные блокировки, которые используются при расчетах, например, заблокировал все табеля и гуляй по ним циклом, делай любые изменения. Я думаю, что для этого подойдут обыкновенные SQL блокировки (select for update). S>- И GUI-блокировки объектов. Для которых, как ты сам сказал нужен "альтернативный механизм". Я бы добавил, что нужен механизм блокировок, которые умеют переживать границы системных транзакций.
Они не должны переживать границы транзакции. Это жутко неудобно. Вместе с транзакцией, должны быстро освобождаться блокировки. Они после нее не нужны. А если прикладник забудет их забить, то вообще пурга.
S>Оба механизма — глобальные, т.е. для всех сессий и всех серверов.
S>И с точки зрения уровня вычислительной среды наличие двух разных типов транзакций (оптимистических и пессимистических) — это прямое противоречие. Вот ответь на вопрос: Те данные, которые заблокировала пессимистическая транзакция (прочитав их), другая оптимистическая может прочитать? Или она должна повеситься и ждать?
Прочитать, да. Не факт что большинство заблокированных объектов будут изменены. Пользователь может просматривать форму. Оптимистическая потому и называется оптимистическая, что у нее хватает оптимизма проверять согласованность только на этапе сохранения. Но если при сохранении стоит блокировка, то пессимистическая всегда главней. Либо ждать по таймауту (как это делает Oracle, чтобы после того как блокировка будет сброшена проверить были ли изменения), либо сразу отбивать.
С уважением, Gleb.
Здравствуйте, GlebZ, Вы писали:
S>>>>- Но, полностью кэш очищать принципиально нельзя, так как прикладная программа может держать на объекты ссылки, и такие объекты должны находиться в IdentityMap. Это нужно для чистоты концепции, так сказать.
GZ>>>После транзакции — IdentityMap уже никому не нужен. Все изменения уже сделаны либо откачены. Все объекты становятся стандартными. S>>И появляется дыра в системе в виде возможности существования двух реплик одного по сути хранимого объекта. Т.е. источник потенциальных ошибок. GZ>Нет. Все остается в той-же степени как и было. Ты же сам писал — IdentityMap один на всю сессию. Так что это получается один из объектов сессионного кэша.
Мдя. Странный у нас диалог получается. Сначала ты говоришь "После транзакции — IdentityMap уже никому не нужен", потом я объясняю зачем он все таки нужен, а ты на это отвечаешь "нет" и аргументируешь — "Ты же сам писал — IdentityMap один на всю сессию". Ты уж реши — нужен он после транзакции или нет.
Здравствуйте, GlebZ, Вы писали:
GZ>Здравствуйте, stalcer, Вы писали:
S>>Я уже говорил, что для прикладника "framework-транзакции" — это системные транзакции, а не бизнес транзакции. Так что "транзакция продажи" должна быть реализована на основе нескольких системных транзакций (каждая из которых будет сериализованной). Т.е.: S>>- Открыл форму (читай, скачал данные) — это одна системная транзакция S>>- Запустил расчет продажи — вторая. S>>И смотри ниже про GUI-блокировки. GZ>Если говорить по твоим словам — объекты между системными транзакциями перегружаются Я начал тормозить.
Да. Перегружаются. Вообщем может и нет, если они в кэше второго уровня были. Но это не важно. Это две разные системные транзакции. Все подчиняется уровню изоляций транзакций. Но в целом — да перегружаются, т.к. это две разные системные транзакции.
S>>
S>> // Пусть obj.Name изначально равно "aaa"
S>> obj.Name = "bbb";
S>> cursor = #oql select x from SomeObjects x where x.Name = "aaa";
S>>
S>><skipped> GZ>Как и всегда, пропуская чтение объекта который уже загружен. Считываешь его гуид, и если он есть в hash, то пропускаешь.
Во первых, не пропуская, а выполняя для него проверку x.Name = "aaa" вручную, на сервере приложений. Так как если бы я не присвоил "bbb" в поле Name, то объект должен бы был попасть в результаты запроса. И это не зависит от того, был ли он загружен в кэш или нет, и даже не должно зависеть от того, был ли он изменен (локально, на сервере приложений) или нет.
Во вторых, для примера я привел простой запрос. А могут быть и более сложные, где такие локальные проверки сделать будет практически невозможно. Поэтому, здесь получается дилемма: либо делать более менее функциональный (с подзапросами, группировками и т.п.) OQL, который выполняется в базе полностью, либо делать оооооочень ограниченный по функциональности, но зато он сможет корректировать свои результаты с учетом текущих изменений в кэше.
GZ>Они не должны переживать границы транзакции. Это жутко неудобно. Вместе с транзакцией, должны быстро освобождаться блокировки. Они после нее не нужны. А если прикладник забудет их забить, то вообще пурга.
Они должны переживать границы системной транзакции. Это если разделять системные транзакции и бизнес транзакции.
S>>И с точки зрения уровня вычислительной среды наличие двух разных типов транзакций (оптимистических и пессимистических) — это прямое противоречие. Вот ответь на вопрос: Те данные, которые заблокировала пессимистическая транзакция (прочитав их), другая оптимистическая может прочитать? Или она должна повеситься и ждать? GZ>Прочитать, да. Не факт что большинство заблокированных объектов будут изменены. Пользователь может просматривать форму. Оптимистическая потому и называется оптимистическая, что у нее хватает оптимизма проверять согласованность только на этапе сохранения. Но если при сохранении стоит блокировка, то пессимистическая всегда главней. Либо ждать по таймауту (как это делает Oracle, чтобы после того как блокировка будет сброшена проверить были ли изменения), либо сразу отбивать.
Ладно. Просто я вчера вечером стормознул. Я вот о чем хотел сказать: Пессимистические транзакции, как и блокировки, которые они ставят, должны быть более менее быстродействующими. Т.к. я по прежнему говорю о системных транзакциях, т.е. о рассчетах. Тогда, единственный приемлимый (по скорости) способ — использовать SQL блокировки.
А у Oracle нет shared блокировок, ну нет и все. А закладывать с систему заведомо тормознутые (причем сильно) транзакции, основанные на своем механизме блокировок — не хочу. Блоее того, тормознутыми транзакциями будут все, а не только пессимистические. Потому что shared-блокировка, наложенная одной пессимистической транзакцией на объект при его чтении, должна быть проверена (с соответствующими последствиями) в другой оптимистической транзакции при изменении объекта. Т.е. при изменении любого объекта в оптимистической транзакции необходимо хотябы проверить, есть или нет на него блокировки (shared, которые не являются SQL блокировками).
Пусть уж лучше прикладной программист сам обойдет эту ситуацию. Т.е. прикладному программисту можно предоставить сервис, например, именованных глобальных блокировок:
Типа один рассчет делает так:
NamedLocks.Lock("Табеля", LockKind.Shared);
// Здесь работаем с табелями...
Commit; // Блокировка снялась.
Другой, точно также, сначала блокирует, потом работает. Конечно, это на совести программиста — не забыть заблокировать, но зато будет нормальная производительность.
Предлагаю опять все поскипать и обсудить транзакции вот к каком ключе:
1: Мы не понимаем друг друга в мелочах, потому что о разном думаем.
Я говорю о системных транзакциях, ты — о бизнес транзакциях.
2: Следует четко разделить характеристики транзакций:
2.1: Есть уровень изоляции: мы рассматриваемт только два: snapshot транзакция (не будем больше называть ее сериализованной) и read-committed транзакция.
2.2: Есть оптимистичность (блокировки): опимистическая транзакция и пессимистическая транзакция.
2.3: 2.1 и 2.2 — это ортогональные характеристики. Возможны все четыре комбинации.
2.4: Если транзакция пессимистическая — это само по себе уровень изоляции snapshot не обеспечивает! Это не надо путать.
3: Следует принимать во внимание технологические ограничения:
3.1: В Oracle нет shared блокировок, необходимых для пессимистических транзакций и для правильного взаимодействия пессимистических транзакций с оптимистическими. Так что тормозить будут все.
3.2: Практически нереально сделать OQL, который бы правильно работал с учетом еще не сброшенных в базу изменений, находящихся в сессионном кэше.
3.3: Read committed транзакции сводят все попытки кэширования на нет. Потому что состояние базы меняется на каждом следующем запросе и для обеспечения согласованости кэшированных данных, в соответствии с read committed уровнем изоляции ранее прочитанные объекты, находящиеся в кэше, нужно инвалидировать: либо все либо иметь специальный механизм, который позволяет определить какие именно.
3.4: И даже если read committed транзакции сделать еще и пессимистичными, то все равно кэширование будет работать на много хуже, причину можно узреть в комбинации 2.4 и 3.3.
4: О том нужно или нет периодчески сбрасывать изменения:
Так как я делаю универсальный framework, то он должен обеспечивать возможность работы с большим объемом данных в одной транзакции. И простой сериализацией в файл здесь не обойтись.
Так как, например, я изменил какой-либо объект X, затем сделал много изменений, так, что памяти не хватило и этот объект (вместе с другими) сериализовался в файл. Для чего мы делаем сериализацию — для того, чтобы освободить оперативную память, т.е. место в кэше. То есть из сессионного кэша объект X надо убрать. А дальше в течении этой же транзакции я опять захотел поработать с объектом X. То есть мне его нужно перечитать. Но не из базы, а из файла.
А это уже называется не сериализация, а кэш, умеющий работать с файлом (в realtime).
4.1: Во первых, совсем другой уровень сложности реализации такого механизма.
4.2: Во вторых, что главное, см. пунк 3.2.
5: Несколько рассуждений о бизнес транзакциях:
5.1:
Например, есть транзакция подажи товаров. Примерный ее сценарий:
5.1.1: В GUI подготавливаем список того что хотим продать (долго, с перерывами на обед и т.п.).
5.1.2: Запускаем рассчет продажи.
Дык вот:
5.2: Уровень изоляции: В фазе 5.1.1 я вообще-то хочу чтобы транзакция имела уровень изоляции read committed, т.к. то окошко из которого я набираю товары должно отражать последние данные. А в фазе 5.1.2 я хочу работать с уровнем изоляции snapshot, причем snapshot не на момент начала бизнес транзакции, а на момент запуска фазы 5.1.2. Потому что, любому рассчету удобнее работать с уровнем изоляции snapshot. Это, заметь, никоим образом не про блокировки.
5.3: Блокировки: В фазе 5.1.1 применительно к форме, в которую я набираю товары, транзакция должна быть пессимистична. Т.е. если я отобрал товар для продажи, то до конца бизнес транзакции его менять никто не может. А применительно к форме из которой я набираю товары (ну типа списов всех имеющихся товаров) — транзакция должна быть оптимистична, т.е. не ставить блокировок на все показанные в этой форме товары.
5.4: Подробнее о форме в которую я набираю товары. Товары, набранные в эту форму должны быть заблокированы — сам товар (объект, представляющий товар: имя + характеристики) — shared блокировкой, а соответствующий ему объект, представляющий количество этого товара имеющееся в наличии — noshare блокировкой (или как она там правильно называется).
5.5: Пунктом 5.4 я хотел сказать, что объекты, которые следует блокировать во время бизнес транзакции должны выбираться из смысла этой транзакции. И формально (автоматически) их выбрать невозможно.
5.6: Важно: Будем называть блокировки из 5.4 — блокировки уровня бизнес транзакций (чтобы внести ясность — не будем их больше называть GUI-блокировками). Т.е. это специальный механизм блокировок, которые держатся на протяжении всей бизнес транзакции, которые могут быть shared и noshare, которые автоматически снимаются при коммите или откате бизнес транзакции. Ну и естественно, что эти блокировки видны между сессиями и серверами приложений. И естественно, что устанавливать эти блокировки можно и программно — т.е. из бизнес логики (рассчета). Но важно что они устанавливаются явно, т.е. прикладным программистом (потому что см. 5.5). И это не SQL блокировки, потому что смотри 3.1.
Это все были предпосылки.
6: А теперь решение которое предлагаю я:
Не приравнивать системную транзакцию к бизнес транзакции. Бизнес транзакция должна состоять из нескольких системных транзакций.
6.1: Например, транзакция продажи из 5.1 состоит из следующих системных транзакций:
— Из нескльких транзакций чтения данных для формы из которой я набираю товары (при открытии формы или при нажатии на Refresh).
— Из одной транзакции рассчета продажи.
6.2: И тогда получается, что эти несколько системных транзакций — короткие (какие и должны быть SQL транзакции) и без интерактива с пользователем. При таком подходе для точной реализации задачи из пункта 5 (важны 5.1, 5.2 и 5.3) нам нужно всего лишь два механизма:
6.2.1: Оптимистические snapshot системные транзакции.
6.2.2: Механизм "блокировок уровня бизнес транзакций". См. 5.6.
6.3: Благодаря 6.2.1 будет удобно делать кэширование (см. 3.3)
6.4: Так как системные транзакции короткие (см. 6.2), то все изыскания из пункта (4) уже не имеют принципиального значения и изменения можно спокойненько сбрасывать в процессе системной транзакции.
7: Проблемы моего подхода:
7.1: Как обеспечить (и в какой степени это необходимо) взаимодействие неявных (а также и явных) SQL блокировок возникающих вследствии update'ов с механизмом "блокировок уровня бизнес транзакций" (из 5.6). Дело в том, что это не должны быть полностью независимые механизмы. Например, если один объект заблокирован даже shared "блокировкой уровня бизнес транзакций", то какой-либо рассчет из другой сессии не должен иметь возможности этот объект изменить. Даже если он не использует "блокировки уровня бизнес транзакций". Так что в соответствии с (3.1) все равно тормозить будут все .
7.2: И как ты правильно сказал — проблема накопления измененных данных в течении всей бизнес транзакции, т.е. сквозь границы системных транзакций. И это тоже большой .
8: Вывод:
Для концептуального завершения моего подхода нужны:
8.1: Эффективный как по скорости так и по масштабируемости механизм "блокировок уровня бизнес транзакций" и механизм его взаимодействия с рассчетами не пользующимися "блокировками уровня бизнес транзакций". Пока не знаю как сделать .
Однако, возможно, что практически "блокировками уровня бизнес транзакций" будут блокироваться лишь небольшое количество объектов. Как этот факт использовать. Надо подумать .
8.2: И соответственно нужен механизм накопления изменений. А здесь самый хитрый вопрос вот в чем: изменения надо копить в тех же объектах или можно в отдельных. В смысле объектах другого класса. А то можно сделать специальные классы временно хранимых объектов. И хранить эти объекты во Oracle'овских временных таблицах. А по завершению бизнес транзакции — их чистить (это быстро, так как временные таблицы Oracle — не транзакционные и работают быстрее обычных). Это, конечно не идеальное решение, так как прикладная программа будет видеть исходный объект и временый — как абсолютно два разных объекта, и даже возможно разной структуры.
А с другой стороны некоторые объекты должны быть временными по своей сути. Например, в бизнес транзакции из (5), пользователь набирает товары для продажи, т.е. выбирает товар и ставит продаваемое количество. Список таких отобранных товаров и показывает одна из GUI форм. Так вот, что является строчкой в этом списке? ИМХО, некий служебный объект:
class SellingItem
{
public Ware SellingWare; // Ссылка на товар.public int Amount; // Продаваемое количество.
};
Именно его в данном случае и нужно сделать временно хранимым (если конечно не делать его полностью хранимым, для логирования продаж, например).
И последнее: с такими "временно" хранимыми объектами можно обращаться гораздо фривольнее, чем с нормальными хранимыми объектами, так как таблицы по завершению программ чистятся, и никакого геморроя с обновлением версий при изменении структуры таких объектов не будет. Так что таблицы для таких объектов вообще могут генериться фреймворком автоматически, а все что нужно программисту сделать — это объявить класс в исходнике программы. Хе. Мне это даже нравиться начинает .
Здравствуйте, stalcer, Вы писали:
S>Здравствуйте, GlebZ, Вы писали:
S>Предлагаю опять все поскипать и обсудить транзакции вот к каком ключе:
S>1: S>Мы не понимаем друг друга в мелочах, потому что о разном думаем. S>Я говорю о системных транзакциях, ты — о бизнес транзакциях.
Бизнес-транзакция есть конечный результат. И полусделанная бизнес-транзакция потерявшая свою атомарность или консинсентность — не очень приятная вещь ведущая к завалу базы.
S>2: S>Следует четко разделить характеристики транзакций:
S>2.1: Есть уровень изоляции: мы рассматриваемт только два: snapshot транзакция (не будем больше называть ее сериализованной) и read-committed транзакция. S>2.2: Есть оптимистичность (блокировки): опимистическая транзакция и пессимистическая транзакция. S>2.3: 2.1 и 2.2 — это ортогональные характеристики. Возможны все четыре комбинации. S>2.4: Если транзакция пессимистическая — это само по себе уровень изоляции snapshot не обеспечивает! Это не надо путать.
Уровень snapshot даже оптимистической проверки не обеспечивает. Так что оптимистическая проверка должна быть обязательна.
S>3: S>Следует принимать во внимание технологические ограничения:
S>3.1: В Oracle нет shared блокировок, необходимых для пессимистических транзакций и для правильного взаимодействия пессимистических транзакций с оптимистическими. Так что тормозить будут все.
У диспетчера блокировок 3 функции: наложить блокировку, убрать блокировку, проверить блокировку. То есть функции одного Hashtable, где быстрота доступа O(1)(если реализация на C#). Это значительно быстрее и эффективнее чем блокировки на уровне БД. Особенно в условиях кэша. S>3.2: Практически нереально сделать OQL, который бы правильно работал с учетом еще не сброшенных в базу изменений, находящихся в сессионном кэше.
А зачем он должен этим заниматься. Сама задача трансформации OQL запроса в эффективный SQL достаточно интересна и сложна. Уж поверь, я этим занимался. А решается данная проблема просто, при загрузке результатов сначало загружаешь OID объекта, если таковой в кэше присутсвует то делаешь MoveNext, а наверх выдаешь ссылку на кешируемый объект(если надо). S>3.3: Read committed транзакции сводят все попытки кэширования на нет. Потому что состояние базы меняется на каждом следующем запросе и для обеспечения согласованости кэшированных данных, в соответствии с read committed уровнем изоляции ранее прочитанные объекты, находящиеся в кэше, нужно инвалидировать: либо все либо иметь специальный механизм, который позволяет определить какие именно.
Механизм? Может быть. Подумай о том, что любое подтвержденное изменение объекта гарантирует что ни одна текущая транзакция (в особенности snapshot) не сможет его изменить.(Хотя бы оптимистическая проверка отобьет). И подумай о том, что используя устаревшие данные просто на чтение, ты можешь базу завалить. Что связано с пунктом 7.2. S>3.4: И даже если read committed транзакции сделать еще и пессимистичными, то все равно кэширование будет работать на много хуже, причину можно узреть в комбинации 2.4 и 3.3.
S>4: S>О том нужно или нет периодчески сбрасывать изменения:
S>Так как я делаю универсальный framework, то он должен обеспечивать возможность работы с большим объемом данных в одной транзакции. И простой сериализацией в файл здесь не обойтись. S>Так как, например, я изменил какой-либо объект X, затем сделал много изменений, так, что памяти не хватило и этот объект (вместе с другими) сериализовался в файл. Для чего мы делаем сериализацию — для того, чтобы освободить оперативную память, т.е. место в кэше. То есть из сессионного кэша объект X надо убрать. А дальше в течении этой же транзакции я опять захотел поработать с объектом X. То есть мне его нужно перечитать. Но не из базы, а из файла. S>А это уже называется не сериализация, а кэш, умеющий работать с файлом (в realtime). S>4.1: Во первых, совсем другой уровень сложности реализации такого механизма. S>4.2: Во вторых, что главное, см. пунк 3.2.
Про пункт 3.2 я уже сказал. А про сериализацию — это чушь. Ляпнул. В действительности, когда у тебя гиг оперативной памяти, то набрать данных на такую транзакцию (точнее нас волнуют изменения данных) — трудновато. А на сервер ставят и больше. Вероятней при такой нагрузке ты будешь окажется узким местом процессор или каналы связи.
S>5: S>Несколько рассуждений о бизнес транзакциях:
S>5.1: S>Например, есть транзакция подажи товаров. Примерный ее сценарий: S>5.1.1: В GUI подготавливаем список того что хотим продать (долго, с перерывами на обед и т.п.). S>5.1.2: Запускаем рассчет продажи.
S>Дык вот:
S>5.2: Уровень изоляции: В фазе 5.1.1 я вообще-то хочу чтобы транзакция имела уровень изоляции read committed, т.к. то окошко из которого я набираю товары должно отражать последние данные. А в фазе 5.1.2 я хочу работать с уровнем изоляции snapshot, причем snapshot не на момент начала бизнес транзакции, а на момент запуска фазы 5.1.2. Потому что, любому рассчету удобнее работать с уровнем изоляции snapshot. Это, заметь, никоим образом не про блокировки. S>5.3: Блокировки: В фазе 5.1.1 применительно к форме, в которую я набираю товары, транзакция должна быть пессимистична. Т.е. если я отобрал товар для продажи, то до конца бизнес транзакции его менять никто не может. А применительно к форме из которой я набираю товары (ну типа списов всех имеющихся товаров) — транзакция должна быть оптимистична, т.е. не ставить блокировок на все показанные в этой форме товары. S>5.4: Подробнее о форме в которую я набираю товары. Товары, набранные в эту форму должны быть заблокированы — сам товар (объект, представляющий товар: имя + характеристики) — shared блокировкой, а соответствующий ему объект, представляющий количество этого товара имеющееся в наличии — noshare блокировкой (или как она там правильно называется). S>5.5: Пунктом 5.4 я хотел сказать, что объекты, которые следует блокировать во время бизнес транзакции должны выбираться из смысла этой транзакции. И формально (автоматически) их выбрать невозможно. S>5.6: Важно: Будем называть блокировки из 5.4 — блокировки уровня бизнес транзакций (чтобы внести ясность — не будем их больше называть GUI-блокировками). Т.е. это специальный механизм блокировок, которые держатся на протяжении всей бизнес транзакции, которые могут быть shared и noshare, которые автоматически снимаются при коммите или откате бизнес транзакции. Ну и естественно, что эти блокировки видны между сессиями и серверами приложений. И естественно, что устанавливать эти блокировки можно и программно — т.е. из бизнес логики (рассчета). Но важно что они устанавливаются явно, т.е. прикладным программистом (потому что см. 5.5). И это не SQL блокировки, потому что смотри 3.1.
S> S>Это все были предпосылки.
S>6: S>А теперь решение которое предлагаю я:
S>Не приравнивать системную транзакцию к бизнес транзакции. Бизнес транзакция должна состоять из нескольких системных транзакций.
S>6.1: Например, транзакция продажи из 5.1 состоит из следующих системных транзакций: S>- Из нескльких транзакций чтения данных для формы из которой я набираю товары (при открытии формы или при нажатии на Refresh). S>- Из одной транзакции рассчета продажи.
S>6.2: И тогда получается, что эти несколько системных транзакций — короткие (какие и должны быть SQL транзакции) и без интерактива с пользователем. При таком подходе для точной реализации задачи из пункта 5 (важны 5.1, 5.2 и 5.3) нам нужно всего лишь два механизма: S>6.2.1: Оптимистические snapshot системные транзакции. S>6.2.2: Механизм "блокировок уровня бизнес транзакций". См. 5.6.
S>6.3: Благодаря 6.2.1 будет удобно делать кэширование (см. 3.3) S>6.4: Так как системные транзакции короткие (см. 6.2), то все изыскания из пункта (4) уже не имеют принципиального значения и изменения можно спокойненько сбрасывать в процессе системной транзакции.
Это мне нравится все больше и больше.
S>7: S>Проблемы моего подхода:
S>7.1: Как обеспечить (и в какой степени это необходимо) взаимодействие неявных (а также и явных) SQL блокировок возникающих вследствии update'ов с механизмом "блокировок уровня бизнес транзакций" (из 5.6). Дело в том, что это не должны быть полностью независимые механизмы. Например, если один объект заблокирован даже shared "блокировкой уровня бизнес транзакций", то какой-либо рассчет из другой сессии не должен иметь возможности этот объект изменить. Даже если он не использует "блокировки уровня бизнес транзакций". Так что в соответствии с (3.1) все равно тормозить будут все .
Не плоди системы. Забудь о SQL блокировках. Только проверка оптимизма(версии) данных тебе даст гарантию корректности (хотя бы на уровне системной транзакции). И до SQL блокировок дело не дойдет (которые также работают на уровне системной транзакции).
S>7.2: И как ты правильно сказал — проблема накопления измененных данных в течении всей бизнес транзакции, т.е. сквозь границы системных транзакций. И это тоже большой .
Блокировки на уровне бизнес-транзакций — уже спасают в некоторой степени.
S>8: S>Вывод:
S>Для концептуального завершения моего подхода нужны:
S>8.1: Эффективный как по скорости так и по масштабируемости механизм "блокировок уровня бизнес транзакций" и механизм его взаимодействия с рассчетами не пользующимися "блокировками уровня бизнес транзакций". Пока не знаю как сделать .
А в чем проблема? В синхронизации между сессиями? S>Однако, возможно, что практически "блокировками уровня бизнес транзакций" будут блокироваться лишь небольшое количество объектов. Как этот факт использовать. Надо подумать .
Вот это — по моему в точку. Точно так-же количество изменяемых объектов.
S>8.2: И соответственно нужен механизм накопления изменений. А здесь самый хитрый вопрос вот в чем: изменения надо копить в тех же объектах или можно в отдельных. В смысле объектах другого класса. А то можно сделать специальные классы временно хранимых объектов. И хранить эти объекты во Oracle'овских временных таблицах. А по завершению бизнес транзакции — их чистить (это быстро, так как временные таблицы Oracle — не транзакционные и работают быстрее обычных). Это, конечно не идеальное решение, так как прикладная программа будет видеть исходный объект и временый — как абсолютно два разных объекта, и даже возможно разной структуры.
Или просто их не сбрасывать. Наиболее проблемная часть в качестве объемов памяти — различного вида отчеты являются read-only. Вот такие объекты можно сбросить. А измененные — на фиг. Если перестанет хватать гига памяти на сервере(в возможности чего я сильно сомневаюсь) — пускай докупят второй. Гиг памяти изменяемых объектов нужен разве что "ГазПрому". И то при неверному деплоингу системы. Так что, думать надо больше о процессоре и каналах связи.
S>А с другой стороны некоторые объекты должны быть временными по своей сути. Например, в бизнес транзакции из (5), пользователь набирает товары для продажи, т.е. выбирает товар и ставит продаваемое количество. Список таких отобранных товаров и показывает одна из GUI форм. Так вот, что является строчкой в этом списке? ИМХО, некий служебный объект:
S>
S>class SellingItem
S>{
S> public Ware SellingWare; // Ссылка на товар.
S> public int Amount; // Продаваемое количество.
S>};
S>
S>Именно его в данном случае и нужно сделать временно хранимым (если конечно не делать его полностью хранимым, для логирования продаж, например).
S>И последнее: с такими "временно" хранимыми объектами можно обращаться гораздо фривольнее, чем с нормальными хранимыми объектами, так как таблицы по завершению программ чистятся, и никакого геморроя с обновлением версий при изменении структуры таких объектов не будет. Так что таблицы для таких объектов вообще могут генериться фреймворком автоматически, а все что нужно программисту сделать — это объявить класс в исходнике программы. Хе. Мне это даже нравиться начинает .
Не знаю насколько это нужно(зависит от самой задачи), но ничего криминального здесь я не вижу.
С уважением, Gleb.
PS: если я делаю несколько голословные утверждения и ляпы, прошу извинить. Поскольку попутно занимаюсь основной производственной деятельностью. Поэтому прошу не принимать это только как информацию к размышлению и то, во многом субъективную и даже неверную.
Ты неверно понимаешь для чего необходимо сбрасывать накопившиеся в сессионном кэше изменения перед выполнением запроса. Отсюда и все остальные разногласия.
Вот пример, который я приводил выше:
Пусть на начало транзакции есть объект с Id = 1 и полем Name = "ааа". Вот он есть в базе.
Затем читаю его в кэш и изменяю поле Name:
obj.Name = "bbb";
Т.е. в базе у объекта поле Name по прежнему равно "aaa". А в кэше имеется измененная версия, у которой Name = "bbb".
Затем, я делаю запрос:
cursor = #oql select x from SomeObjects x where x.Name = "aaa";
Так как запрос выполняется в базе, то объект с Id = 1 будет частью результата этого запроса. А он не должен быть. Так как с точки зрения прикладного программиста у объекта значение поля Name уже равно "bbb".
Далее ты пишешь:
А решается данная проблема просто, при загрузке результатов сначало загружаешь OID объекта, если таковой в кэше присутсвует то делаешь MoveNext, а наверх выдаешь ссылку на кешируемый объект(если надо).
Так вот в этом "если надо" и состоит главная проблема. Потому что, если состояние объекта, который в кэше (т.е. измененный!!!, т.е. то состояние о котором думает прикладной программист), удовлетворяет условию where, то надо, а если не удовлетворяет — то не надо. А как это проверить. Никак! Ну то есть для данного запроса еще как-то можно, но для более сложного — нет.
Здравствуйте, stalcer, Вы писали:
S>Далее ты пишешь:
S>
S>А решается данная проблема просто, при загрузке результатов сначало загружаешь OID объекта, если таковой в кэше присутсвует то делаешь MoveNext, а наверх выдаешь ссылку на кешируемый объект(если надо).
S>Так вот в этом "если надо" и состоит главная проблема. Потому что, если состояние объекта, который в кэше (т.е. измененный!!!, т.е. то состояние о котором думает прикладной программист), удовлетворяет условию where, то надо, а если не удовлетворяет — то не надо. А как это проверить. Никак! Ну то есть для данного запроса еще как-то можно, но для более сложного — нет.
Я говорил именно OID. В одном из начальных сообщений ты говорил о GUID в другом о другом идентификаторе, это не столь важно. Тебе нужен идентификатор который будет уникально идентифицировать объект во всей системе независимо от формы хранения и местоположения. Только на такой информации ты сможешь построить кэш и многие механизмы типа транзакций. Будет ли это GUID'ом или будет некоторым однозначно высчитываемым значением, это не важно.
Итого возьмем нагрузку на различные варианты(2 первых ты уже описал, 3 мой
1. За счет уменьшения функциональности OQL мы не перечитываем объекты БД. Но в данном случае, при уменьшении функциональности OQL мы значительно увеличиваем кол-во OQL запросов что выходит нам большим боком. К тому-же сразу встает вопрос оптимизации результирующих SQL запросов.
2. OQL — нормальный. В этом случае мы перечитываем все объекты — измененные и неизмененные в кэш. Измененные объекты лежат в БД.
3. Мой вариант. OQL — нормальный. Измененные объекты не могут быть выгружены из памяти. На БД они не отправляются. При выборке из БД, проверяется OID (уникальный идентификатор объекта в пределах всей системы). Если объект с таким OID уже находится в кэше(объект измененный), то смысла перегружать такой объект нет и мы его пропускаем. Это в отличие от 1 варианта никогда не спасет от самого факта запроса, и так-же не спасет от загрузки результирующей строки (хотя бы OID для данного объекта мы должны получить). Плюс состоит в том, что мы не обязаны сбрасывать объект в БД.
Выбирай сам что нравится.
Причем здесь OID? Я OID и делаю так, как ты говоришь, т.е. уникальными по всей системе и т.п. Но то, что ты сказал, к данному вопросу не имеет отношения.
Далее ты говоришь "За счет уменьшения функциональности OQL мы не перечитываем объекты БД". Это тоже совершенно другой вопрос. Да он может и важный, в чем я сомневаюсь, но к данной проблеме не имеет никакого отношения.
Последний раз , ооооочень подробно пишу пример!
1: Начальное состояние базы:
OID Name
---------------
1 "xxx"
2 "yyy"
3 "aaa"
4 "aaa"
5 "aaa"
2: Процесс с точки зрения прикладного программиста:
2.1:
obj = GetById(5);
obj.Name = "zzz";
cursor = #oql select x from SomeObjects x where x.Name = "aaa";
foreach (cursor)
{
System.WriteLn(cursor.OID + " " + cursor.Name);
};
2.2:
Внимание! Что хочет увидеть прикладной программист в качестве результата работы программы:
OID Name
---------------
3 "aaa"
4 "aaa"
2.3: Т.е. он не должен увидеть объекта с OID = 5 в результатах запроса, так как он сменил его поле x.Name на "zzz" перед выполнением запроса, а в запросе стоит where x.Name = "aaa".
3: Теперь, как этот процесс предлагаешь реализовать ты:
3.1:
В первых двух строчках программы, а именно:
obj = GetById(5);
obj.Name = "zzz";
В кэш выберется объект с OID = 5 и его поле Name изменится на "zzz". Это как раз понятно. А состояние базы после этого шага не измениться, т.е. останется как в (1), потому-что мы не сбрасываем изменения в базу, а держим их только в кэше (это опять же по твоему).
3.2:
Далее выполняем OQL запрос:
cursor = #oql select x from SomeObjects x where x.Name = "aaa";
Этот OQL запрос преобразуется в SQL запрос и уже SQL запрос выполняется в базе. И поскольку база находится в состоянии (1), то результатом этого SQL запроса будет:
OID Name
---------------
3 "aaa"
4 "aaa"
5 "aaa"
3.3: Т.е. результат из (3.2) не совпадает с желаемым (2.2)!!!. Следовательно этот результат (SQL запроса) необходимо скорректировать, чтобы получить правильный результат OQL запроса.
3.4:
И в качестве корректировки для (3.3) ты предлагаешь, просто заменять те записи из результата SQL запроса, которые есть в кэше, на собственно кэшированные, т.е. после замены получится следующее:
OID Name
---------------
3 "aaa"
4 "aaa"
5 "zzz" // Эта строчка была в кэше, ее и заменили.
3.5:
Результат в (3.4) опять не соответствует ожидаемому (в 2.2). Это же очевидно! Хотели с where x.Name = "aaa", а получили (5, "zzz").
В пункте (3) я описал, как ты предлагаешь сделать. Результат получается неверным. Если ты не согласен — найди ошибку.
PS: Читай, пожалуйста, сообщения внимательней. Мы же сложные вещи обсуждаем. И они еще более сложные, потому что одно зависит от другого.