Здравствуйте, AlexandreVN, Вы писали:
AVN>Здравствуйте, AlexandreVN, Вы писали:
AVN>>Собственно структура класов для манипуляции деревом разнотипных объектов
AVN>"Разнотипных" — не ключевое слово. наоборот все убрал что не имело отношения к расслоению объекта
А в чем проблема-то?
В коллекции вообще и в деревья в частности хорошо включать Visitor — так можно безнаказанно добавлять функционал в уже работающий код.
Тогда разные визиторы (и их комбинации) будут и в xml сериализовать, и обрабатывать узлы, и всякое такое...
На опушке за околицей мужики строили коровник.
Работали споро и весело. Получалось х**во.
Re[3]: перемудрил кажись...
От:
Аноним
Дата:
14.12.07 15:50
Оценка:
A>А в чем проблема-то? A>В коллекции вообще и в деревья в частности хорошо включать Visitor — так можно безнаказанно добавлять функционал в уже работающий код. A>Тогда разные визиторы (и их комбинации) будут и в xml сериализовать, и обрабатывать узлы, и всякое такое...
собственно проблема в том что решил учиться писать правильно ))
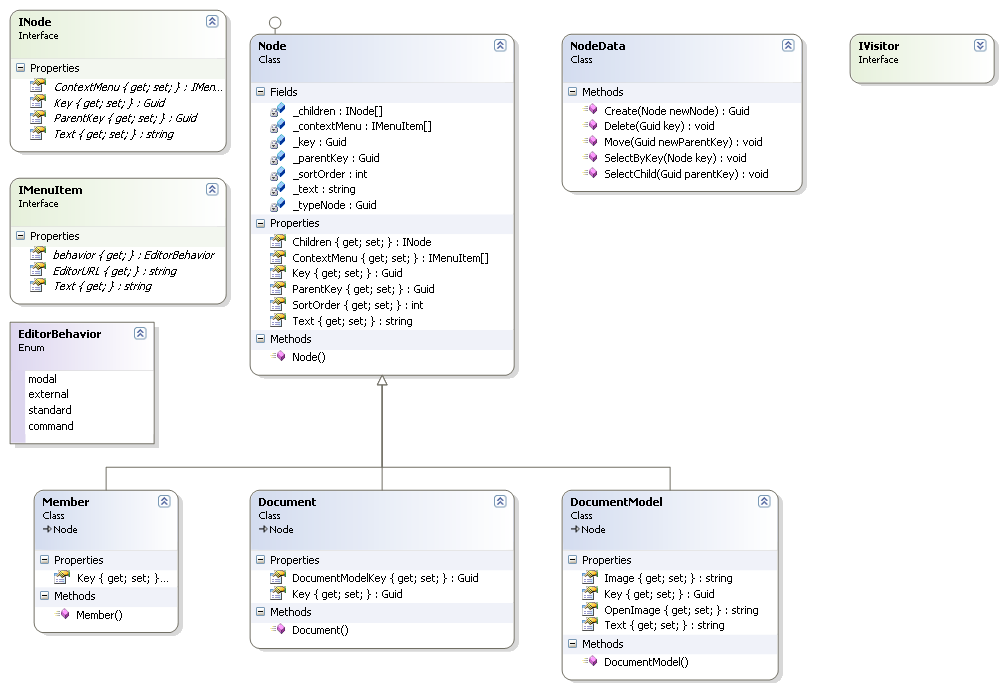
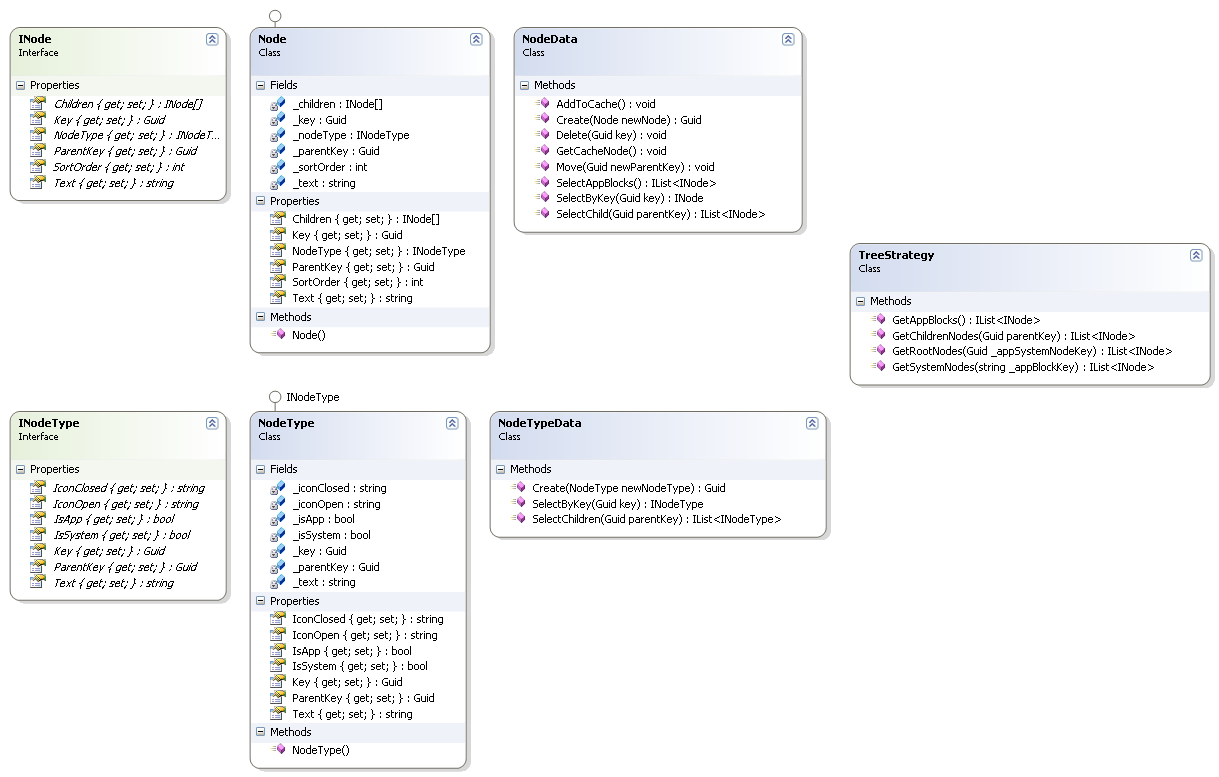
вопрос в разделении логики по класам. То что работу с базой данных надо вынести в отдельный клас у меня сомнений не вызывает (NodeData)
А вот надо ли всю логику объекта выносить в отдельный клас (NodeStrategy)??
Здравствуйте, Аноним, Вы писали:
A>>А в чем проблема-то? A>>В коллекции вообще и в деревья в частности хорошо включать Visitor — так можно безнаказанно добавлять функционал в уже работающий код. A>>Тогда разные визиторы (и их комбинации) будут и в xml сериализовать, и обрабатывать узлы, и всякое такое...
А>собственно проблема в том что решил учиться писать правильно )) А>вопрос в разделении логики по класам. То что работу с базой данных надо вынести в отдельный клас у меня сомнений не вызывает (NodeData) А>А вот надо ли всю логику объекта выносить в отдельный клас (NodeStrategy)??
Может имеет выносить туда только логику непосредственно не относящююся к модификации объекта
как то генерация в друго виде запрашиваемому, валидация, операции с кешем и т.п.?
Почему в базовом классе ноды какие-то Text и Image? и то, и другое — должно быть в потомках, разбираться, какая нода, можно RTTI (языковым или свой на коленке сляпать), или же сделать что-то типа virtual DataHolder GetData(enum eDataKind DataKind);
В базовом классе ноды должно быть именно что ее роль в дереве, и, возможно, какие-то pure virtual методы типа GetData. Уж точно не Text и не Image.
Обязательно надо или визитор, или что-то типа Node* enumerate(iterator* it), которая вернет первый элемент, если итератор свежесозданный, и следующий по итератору элемент в другом случае, или NULL, если дерево кончилось. Такая штука зачастую удобнее визитора, да и обход дерева визитором можно сделать уже на ней.
Возможно, еще интерфейс TreeStrategy, в который будет вынесен ребалансинг, с двумя имплементациями (можно и больше двух) для AVL и red-black.
Здравствуйте, AlexandreVN, Вы писали:
AVN>Собственно структура класов для манипуляции деревом разнотипных объектов
А что за объекты-то? Каких типов? За что они отвечают?
Мне кажется, что Вы действительно немного перемудрили. В некоторых классах смешаны совершенно разные обязанности, которые неплохо бы разделить. Например, класс NodeStrategy у Вас отвечает и за помещение узлов в хранилище (только не ясно, что это за хранилище — дерево узлов или кэш), и за преобразование узлов в XML, и за валидацию этих узлов или хранилища.
Я бы предложил выделить классы на основе обязанностей. Отчасти это у Вас уже сделано. Класс NodeData отвечает за доступ к базе данных и извлечение узлов из нее. Класс NodeStrategy работает с хранилищем узлов (деревом или кэшем). Единственное, я бы предложил вынести валидацию и конвертацию в XML в отдельные классы, например, Валидатор и Конвертер. Основания тут просты: валидация — в перспективе — может происходить по разным правилам для разных целей, да и конвертация одним XML может не ограничиться.
Отдельный интерфейс INode я бы тоже не стал заводить. Все те же свойства присутствуют и в базовом классе Node, так что наличие INode ничего не дает.
Задача
есть некая группа разнородных объектов (Document, Member, Context, Domain, Script e.t.c.)
их надо представить в виде дерева.
при выборе объекта в рабочей области (IFrame) отображается форма его свойств и действий
объекты в дереве в зависимости от типа должны иметь разный визуальный вид (значки)
и разное контекстное меню.
Объекты хранятся в базе данных.
при загрузке объекта помещаем его в кеш.
при изменении кеш обновляем.
для построения дерева объектов достаточно информации класа Node
вопрос№1 как будет более правильно?
1.создать выделенный клас NodeStrategy и через него будем работать с объектом Node
(Создание, получение, изменение, удаление, добавление в кэш и удаление из кеша)
2.создать выделенный клас NodeStrategy и через проперти объекта Node будем с ним работать
при (Создание, получение, изменение, удаление) вызавать тот или иной метод класса
попутно осуществляя операции с кешем
3. весь функционал реализуем в классе Node
вопрос№2
Как реализовать реализовать хранение типов объекта (enum? таблица на сервере?) и разные картинки для разных типов объектов??
есть вобщем то фиксированный редко изменяемый набор типов объектов (у них есть значки по умолчанию)
однако есть некоторые объектов, которые имеют свои вложенные типы со своими значками (Document например)
Собственно это все уже есть и работает,
но написано мягко говоря не совсем понятно как (несмотря на то что писал сам )) )
Хочеть ся что бы все было понятно и красиво )
Читаю паралельно Фаулера, но я тугодум — долго доходит.
Здравствуйте, AlexandreVN, Вы писали:
AVN>их надо представить в виде дерева.
Зачем? Только для того, чтобы представить их в виде дерева в UI?
На мой взгляд, Вы смешиваете два разных понятия: дерево, как элемент UI, и дерево, как абстрактный тип данных.
AVN>для построения дерева объектов достаточно информации класа Node
Если Ваша задача — представить объекты в виде дерева в UI, то Вам необязательно выводить классы Document, Member и DocumentModel из класса Node. Организуйте эти классы так, как будто никакого дерева и не существует. А для узла дерева заведите специальный класс Node, который будет иметь свойства: картинка, текст, контекстное меню и т.д. Но его совершенно необязательно делать полиморфным, т.к. набор его свойств определяется не документами, мемберами документов или моделью, а деревом. Т.е. все узлы дерева будут иметь одни и те же свойства. Только значения у этих свойств могут быть разные. Например, разные картинки, текст, меню и т.д.
А для связи между узлом из дерева и объектом, который он визуализирует (например, документом), используйте ID.
AVN>1.создать выделенный клас NodeStrategy и через него будем работать с объектом Node
Node должен только возвращать или устанавливать свои свойства: картинку, текст, меню и т.д. Методы работы с деревом поместите в класс Tree.
AVN>(Создание, получение, изменение, удаление, добавление в кэш и удаление из кеша)
Создайте специальный класс для работы с хранилищем данных, например, с базой данных. Этот класс может использовать кэш. В любом случае, остальной код не должно заботить, использует он кэш или нет.
AVN>2.создать выделенный клас NodeStrategy и через проперти объекта Node будем с ним работать AVN>при (Создание, получение, изменение, удаление) вызавать тот или иной метод класса AVN>попутно осуществляя операции с кешем
Думаю, так поступать не стоит. С БД и кэшем лучше справиться класс Хранитель Данных (или Источник Данных), а со свойствами Node лучше работать напрямую.
AVN>3. весь функционал реализуем в классе Node
Думаю, так поступать тоже не стоит. Т.к. для некоторых операций Node придется хранить ссылку на на Хранитель Данных.
ээ...
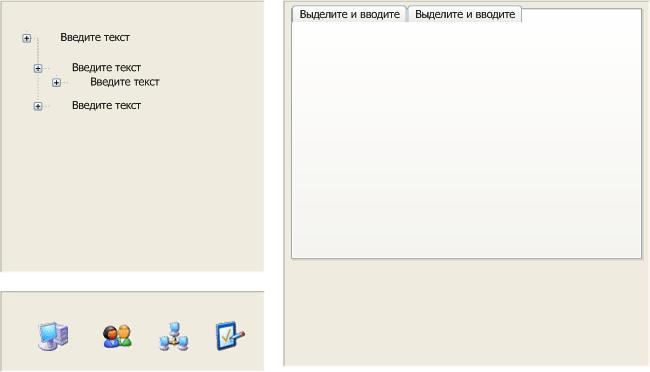
Вот тут примерный интерфейсик (все естесно веб) всего этого
т.е. нижняя панель содержит модули программы
левая панель дерево объектов такого типа которые нужны для данного модуля
ну и правая панель — рабочая область с объектами
а вот схема которая пока вырисовалась
я так понимаю — то что я привязался под конкретный интерфейс уже ошибка?
Забыл сказать — данный интерфейс — это вобщемто конфигурация и настройка системы и справочников.
по поводу реализации конкретно самих объектов — согласен Node в качестве родителя им особо и не нужен.
однако при дальнейшей работе с ними (не в настройке а в реальной работе, при генерации конечного документа и многих других действиях) очень нужен параметр SortOrder и NodeType
Здравствуйте, akarinsky, Вы писали:
A>Здравствуйте, AlexandreVN, Вы писали:
AVN>>Здравствуйте, AlexandreVN, Вы писали:
AVN>>>Собственно структура класов для манипуляции деревом разнотипных объектов
AVN>>"Разнотипных" — не ключевое слово. наоборот все убрал что не имело отношения к расслоению объекта
A>А в чем проблема-то? A>В коллекции вообще и в деревья в частности хорошо включать Visitor — так можно безнаказанно добавлять функционал в уже работающий код. A>Тогда разные визиторы (и их комбинации) будут и в xml сериализовать, и обрабатывать узлы, и всякое такое...
Здравствуйте, AlexandreVN, Вы писали:
AVN>Задача AVN>есть некая группа разнородных объектов (Document, Member, Context, Domain, Script e.t.c.) AVN>их надо представить в виде дерева.
Точно такая ситуация описана в GoF.
AVN>вопрос№1 как будет более правильно? AVN>1.создать выделенный клас NodeStrategy и через него будем работать с объектом Node AVN>(Создание, получение, изменение, удаление, добавление в кэш и удаление из кеша) AVN>2.создать выделенный клас NodeStrategy и через проперти объекта Node будем с ним работать AVN>при (Создание, получение, изменение, удаление) вызавать тот или иной метод класса AVN>попутно осуществляя операции с кешем AVN>3. весь функционал реализуем в классе Node
Кеширование по-началу прикручивать не обязательно.
У вас функционал, отвечающий за сохранение и удаление данных, будет в классе NodeData. Методы из NodeData будут вызываться методами класса Node
Что-то типа:
class Node
{
public void Save()
{
NodeData.Save(this);
}
}
Причем метод Node.Save можно сделать абстрактным, а в потомках определить также, как указано выше. При этом в классе NodeData сделать несолько перегруженных вариантов Save чтобы сохраняли объекты разных типов.
Но это вызовет некоторое дублирование кода.
Загрузку узла можно проводить в конструкторе с параметром id узла, снова используя класс NodeData.
Для списка потомков узла можно написать коллекцию, которая будет поддерживать загрузку по первому требованию (Lazy Load).
AVN>вопрос№2 AVN>Как реализовать реализовать хранение типов объекта (enum? таблица на сервере?) и разные картинки для разных типов объектов?? AVN>есть вобщем то фиксированный редко изменяемый набор типов объектов (у них есть значки по умолчанию) AVN>однако есть некоторые объектов, которые имеют свои вложенные типы со своими значками (Document например)
Хранение где?
Если в БД, то наиболее логичен вариант с таблицей для каждого класса (см Фаулера).
В памяти тип объекта хранить не надо. Лучше пользоваться полиморфизмом. (см GoF паттерн Composite, там как раз про картинки)
Беру небольшой таймаут. Надо разбиратьться со всем что написали )
позже выложу то что у меня получилось и как с чем разобрался — надесь на ваши коментарии
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, AlexandreVN, Вы писали:
AVN>>ээ... AVN>>Вот тут примерный интерфейсик (все естесно веб) всего этого
G>А я подумал что нужно что-то типа визуального редактора....
Так и есть. визуальный редактор справочников, шаблонов, модели документа и т.п.
Здравствуйте, AlexandreVN, Вы писали:
G>>А я подумал что нужно что-то типа визуального редактора.... AVN>Так и есть. визуальный редактор справочников, шаблонов, модели документа и т.п.
Ну если это должен быть WYSIWYG редактор (типа MS Word). Тогда описанная мной выше схема подойдет. Хотя я не представляю как такое возможно в вебе.
Если это редактор свойств объектов, собранных в какую-то иерархию (как на рисунке), то вам понадобится отделить дерево (с картинками и надписями) от объектов. Всю работу с визуальным деревом можно возложить на стандартные котролы.
Здравствуйте, AlexandreVN, Вы писали:
AVN>я так понимаю — то что я привязался под конкретный интерфейс уже ошибка?
Конечно. Сегодня Вы хотите, чтобы объекты были доступны пользователю в виде дерева, завтра — в виде "табочек" и списка, послезавтра — в виде грида и т.д. Не стоит же каждый раз, как только у Вас поменяется GUI, изменять архитектуру!
Да и вообще всяких разных представлений может быть много. А вот внутреняя архитектура у Вас должна быть одна.
Здравствуйте, Кирилл Лебедев, Вы писали:
КЛ>Здравствуйте, AlexandreVN, Вы писали:
AVN>>я так понимаю — то что я привязался под конкретный интерфейс уже ошибка? КЛ>Конечно. Сегодня Вы хотите, чтобы объекты были доступны пользователю в виде дерева, завтра — в виде "табочек" и списка, послезавтра — в виде грида и т.д. Не стоит же каждый раз, как только у Вас поменяется GUI, изменять архитектуру!
КЛ>Да и вообще всяких разных представлений может быть много. А вот внутреняя архитектура у Вас должна быть одна.
а в случае если объект сам по себе логически подразумевает иерархическую структуру?
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, AlexandreVN, Вы писали:
AVN>>а в случае если объект сам по себе логически подразумевает иерархическую структуру?
G>Например?
Здравствуйте, AlexandreVN, Вы писали:
AVN>а в случае если объект сам по себе логически подразумевает иерархическую структуру?
Структура (в том числе — иерархическая) создается под решение конкретной задачи. Например, для быстрого поиска используются деревья, хэш-таблицы, ячейки и т.д. Бывает, что модулю или программе нужно решать много всяких задач. Соответственно и структур (иерархических) может использоваться тоже много.
В общем, основная мысль такова: структура (ее еще можно называть классификацией) — далеко не абсолют. Поэтому ее лучше отделять от содержимого. Так для ускорения работы БД создаются всякие индексы, которые, на самом деле, тоже можно назвать в некотором роде иерархической структурой — ведь индексы задают другой способ упорядочения информации, которая хранится в БД.
Здравствуйте, AlexandreVN, Вы писали:
AVN>каталог товаров, дерево, тел. справочник и т.п.
Я надеюсь вы не собираетесь обрабатывать каталог товаров как дерево, где каждый узел может быть товаром или категорией (или другим классифицирующий признаком)?
Обычно товары и категории — разные объекты, хранятся и обрабатываются по-разному. При этом каждая категория содержит ссылки на товары, находящиеся в этой категории (а в БД наоборот — товар ссылается на категорию).
Дерево — абстрактный тип данных. А какая иерархия в телефонном справочнике вообще придумать не могу.
G>Я надеюсь вы не собираетесь обрабатывать каталог товаров как дерево, где каждый узел может быть товаром или категорией (или другим классифицирующий признаком)? G>Обычно товары и категории — разные объекты, хранятся и обрабатываются по-разному. При этом каждая категория содержит ссылки на товары, находящиеся в этой категории (а в БД наоборот — товар ссылается на категорию).
а почему нет? с помощью того же visitor
G>Дерево — абстрактный тип данных. А какая иерархия в телефонном справочнике вообще придумать не могу.
города — > первые буквы имени или округ-> вид организации (услуги) — > номера
да вообщем то неважно. может неудачный пример
Здравствуйте, Кирилл Лебедев, Вы писали:
КЛ>Здравствуйте, AlexandreVN, Вы писали:
AVN>>а в случае если объект сам по себе логически подразумевает иерархическую структуру? КЛ>Структура (в том числе — иерархическая) создается под решение конкретной задачи. Например, для быстрого поиска используются деревья, хэш-таблицы, ячейки и т.д. Бывает, что модулю или программе нужно решать много всяких задач. Соответственно и структур (иерархических) может использоваться тоже много.
КЛ>В общем, основная мысль такова: структура (ее еще можно называть классификацией) — далеко не абсолют. Поэтому ее лучше отделять от содержимого. Так для ускорения работы БД создаются всякие индексы, которые, на самом деле, тоже можно назвать в некотором роде иерархической структурой — ведь индексы задают другой способ упорядочения информации, которая хранится в БД.
а что если под таким углом — есть объект для хранения объектов в дереве и неважно каких (есть только условие что все они должны обладать рядом свойств необходимых для построения дерева)?
Здравствуйте, AlexandreVN, Вы писали:
AVN>а что если под таким углом — есть объект для хранения объектов в дереве и неважно каких (есть только условие что все они должны обладать рядом свойств необходимых для построения дерева)?
Поисковый индекс.
Здравствуйте, AlexandreVN, Вы писали:
AVN>а что если под таким углом — есть объект для хранения объектов в дереве и неважно каких (есть только условие что все они должны обладать рядом свойств необходимых для построения дерева)?
Сферический конь в вакууме?
Вы слишком сильно зацикливаетесь на структурах данных.
Здравствуйте, AlexandreVN, Вы писали:
AVN>города — > первые буквы имени или округ-> вид организации (услуги) — > номера AVN>да вообщем то неважно. может неудачный пример
А позже Вам потребуются другие классификации:
по виду деятельности (не важно в каком городе);
по названию (опять-таки, не важно где);
по по номеру телефона;
по рейтингу, набранному среди Клиентов;
и т.д. — классификаций можно придумать множество.
Следует добавить, что одна и та же организация:
может предоставлять разные услуги;
находиться (иметь представительства) в разных регионах.
Что же теперь выходит — переделывать архитектуру программы каждый раз, когда появится новый критерий для классификации?
Разумнее, поступить по-другому — для каждого критерия создать свой индекс и хранить его отдельно. А архитектуру не завязывать на индексы.
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, AlexandreVN, Вы писали:
AVN>>а что если под таким углом — есть объект для хранения объектов в дереве и неважно каких (есть только условие что все они должны обладать рядом свойств необходимых для построения дерева)?
G>Сферический конь в вакууме?
G>Вы слишком сильно зацикливаетесь на структурах данных.
Здравствуйте, Кирилл Лебедев, Вы писали:
КЛ>Здравствуйте, AlexandreVN, Вы писали:
AVN>>а что если под таким углом — есть объект для хранения объектов в дереве и неважно каких (есть только условие что все они должны обладать рядом свойств необходимых для построения дерева)? КЛ>Поисковый индекс.
Здравствуйте, AlexandreVN, Вы писали:
AVN>я запутался. что вы подразумеваете под индексами?
Любая классификация, фактически, и есть поисковый индекс. Если Вы пойдете в какую-нибудь крупную библиотеку, то увидите, что там есть, как минимум, два вида каталогов:
алфавитный — позволяет найти книгу по фамилиям авторов;
тематический — позволяет найти книгу по заданной теме.
Каталоги располагаются отдельно и не привязаны к объектам (книгам), т.е. в каталогах находятся не книги, а карточки (ссылки на книги). Сами же книги находятся в хранилище и заказываются по ссылкам из каталога.
Ваше дерево — это такой же каталог. Он должен содержать ссылки на объекты (например, их IDs), но не сами объекты, т.к. каталогов (индексов) можно наделать, сколько будет душе угодно.