Здравствуйте, gandjustas, Вы писали:
G>>>·>А откуда возникла такая задача "транзакционно обновить состояние корзины с резервов на складе"? По-моему, ты путаешь цель и средство. G>>>Конкретно это из озона. G>·>Это ты описываешь конкретное решение некой задачи. Сама задача-то в чём? G>Не в курсе чем озон занимается?
Судя по твоим заявлениям: транзакционно обновляют состояние корзины с резервов на складе.
G>В основном товары со склада продает. Вот и надо продать не больше чем есть.
Для этого нет необходимости транзакционно обновлять состояние корзины с резервов на складе.
G>·>Для решения этой задачи нет необходимости обновлять корзину и склад в одной транзакции. Достаточно их обновить последовательно — вначале склад, потом корзину, в разных транзакциях. G>Тогда у нас нет никакого выигрыша от того, что это разные транзакции в разных базах. В сумме это будет работать медленнее чем в одной.
Зато будет работать хотя бы.
G>Более того, возможен сценарий когда первая выполнилась, а вторая отвалилась, просто по таймауту. Тогда товар на складе забронирован, а статус корзины не поменялся. Нужно писать код для отката.
Это эквивалентно ситуации: клиент наполнил корзину и ушел плюнув, потому что левая пятка зачесалась. Код отката брони на складе ты будешь писать в любом случае.
G>Идемпотентной такую операцию уже не сделаешь и автоповтор со стороны клиента тоже.
Почему? Присваиваешь заявке на бронирование uuid и долбишь склад до посинения.
G>Короче сплошные недостатки и ноль преимуществ
Угу-угу.
G>·>Да не важно. Подставь любую другую очень "нужную" фичу, которая есть в svn но нет в git. G>Так в том и дело, что у СВНа не было преимуществ перед Гит. У Гита был один недостаток — сложность использования, до сих пор два из трех программистов не умеют в гит.
Многие носились с номерами ревизий. Коммит 23414 выглядит на порядок лучше, чем 21f0c36f3cef976789d9c65c16198a7c14f7b272. А ещё отдельные чекауты подветок, локи, явные переименования, и т.п. Многие заявляют "нам нужно".
G>·>Суть моей аналогии, что твоё "нам нужно [xxx]" ты исходишь не из постановки бизнес-задачи, а из конкретного решения в виде монолитной архитектуры и гигантской всемогущей субд в виде одного процесса. G>СУБД умеет ровно то, что у умеет — Атомарные изолированные транзакции, сохраняющие согласованность данных и гарантирующие надежность. G>Любые реализации таких гарантий вручную дают менее надежный и менее производительный код, который не имеет преимуществ. Никакая теория и философия еще ни разу никому помогли сделать лучше транзакций в БД там, где транзакции решают проблему.
Теория простая: CAP-теорема.
G>>>·>Да не важно. СУБД это просто такой готовый процесс. G>>>Угу, процесс который умеет это делать, в отличие от твоего процесса, который по умолчанию не умеет и надо прям поприседать чтобы умел. G>·>Речь о другом — процесс не один. Можно иметь две субд, в каждой свои локальные транзакции. G>И что это даст? Неатомарное, несогласованное, неизолированное изменение данных? В чем смысл?
Чтоб работало.
G>>>>>Как это связано? Если они все приходят в итоге на одни сервер? бд например, то задача решаема. G>Один кластер — один мастер для записи и 15 реплик для чтения. Все транзакции меняющие данные ходят на один сервер.
Ок, почитал. Цитатки:
"continue to migrate, shardable, write-heavy workloads to sharded systems as Azure Cosmos DB".
"no longer allow adding new tables to the current PostgreSQL deployment".
"we're not ruling out sharding PostreSQL in the future"
"move complex join logic to the application layer"
"caching layer"
Хорошо подытожено: "It's Scaling PostgresNoSQL, not Scaling PostgreSQL, as this is full of NoSQL solutions: eventually consistent, cascading read replicas, sharding for write-heavy workloads, offload to purpose-built CosmosDB, lazy writes, cache limiting, no new create/alter table, schemaless, avoid complex multi-table joins..."
Но в главном-то ты прав: "все приходят в итоге на одни сервер".
G>·>Он может просто лечь, и без нагрузки. G>Сам? Просто так? Реплик нет? Админов нет? Какой смысл это рассматривать как реалистичный сценарий? G>Ну даже допустим что у вас сервер может лечь, вы его надежность оцениваете как число X в интервале (0;1) — оба конца не включены. G>Если рассмотреть сценарий выше с покупкой товаров в ОЗОН и разнесением транзакций на два сервера, то общая надежность будет равна X^2, что строго меньше Х. То есть надежность двух серверов ниже.
Ты, видимо, сервер и сервис путаешь. Один сервис может работать как несколько инстансов, нет требования монолитности. И внезапно надёжность сервиса выше, если он работает на нескольких серверах.
G>>>Этой проблемы просто не будет, мы никогда не продадим больше чем есть на складе если резервирование сделаем транзакционно. G>·>Я не понимаю как "пользователь плюёт" соотносится с "не продадим больше". G>Это относится к недостаткам решения. Так как "пользователь плюет" это потеря денег. Потому что дальше пользователь идет на другой маркетплейс и к тебе возможно уже не возвращается никогда
"резервирование сделаем транзакционно" не решает проблему "пользователь плюет".
G>>>Ту самую, которую ты непонятно как хочешь решить. G>·>Это какую? G>Чтобы пользователь придя за своим товаром получил его.
Для этого не требуется обновлять корзину и склад в одной транзакции.
G>·>Почему? Напомню контекст: МСА. G>Выше все описал. Без МСА получается лучше.
Не получается. Проще — да, но по многим другим параметрам — хуже.
G>>>Ага, и в этом случае статус может стать "зарезервирован", а остаток на складе не уменьшится, и ты будешь разговаривать с недовольными покупателями. G>·>Пока сервис склада не вернёт ответ "резервация прошла успешно" мы не обновляем статус заказа в сервисе заказов. G>Тогда в этом нет никакого смысла, потому что недостатки есть, а преимуществ нет.
Можно продолжать работать с корзиной, например, позволять добавлять товары ещё, обновлять адрес доставки, применять скидки и купоны и т.п.
G>Напомню что ОпенАИ не использует распределенные транзакции и живет на одном кластере, то есть все записи приходят в один мастер.
Угу-угу.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Здравствуйте, gandjustas, Вы писали:
G>>>>·>А откуда возникла такая задача "транзакционно обновить состояние корзины с резервов на складе"? По-моему, ты путаешь цель и средство. G>>>>Конкретно это из озона. G>>·>Это ты описываешь конкретное решение некой задачи. Сама задача-то в чём? G>>Не в курсе чем озон занимается? ·>Судя по твоим заявлениям: транзакционно обновляют состояние корзины с резервов на складе.
Это часть того, что они делают.
G>>В основном товары со склада продает. Вот и надо продать не больше чем есть. ·>Для этого нет необходимости транзакционно обновлять состояние корзины с резервов на складе.
Ты не понимаешь суть задачи
две сущности Order (id, status, lines(product_id, q)) и Stock (product_id, reserverd, limit). При смене статуса в Order мы меняем состояние резервов в Stock.
При подтверждении заказа — увеличиваем reserved в stock для каждого line в order. А при отмене уменьшаем.
Если мы это не делаем в одной транзакции, то как ты потом уменьшишь, если статус не удалось сменить?
Сохранишь копию order в то же базе в той же тразакции, да?
Ты наверное начнешь разговор что так делать не надо. Но озону надо. Потому что разница limit-reserverd отображается в интерфейсе приложения как "сколько осталось" и это отображается прямо в результатах поиска, то есть надо быстро получать это число для любого количества товаров.
G>>·>Для решения этой задачи нет необходимости обновлять корзину и склад в одной транзакции. Достаточно их обновить последовательно — вначале склад, потом корзину, в разных транзакциях. G>>Тогда у нас нет никакого выигрыша от того, что это разные транзакции в разных базах. В сумме это будет работать медленнее чем в одной. ·>Зато будет работать хотя бы.
Не лучше, чем в одной базе. Прям строго математически не лучше.
G>>Более того, возможен сценарий когда первая выполнилась, а вторая отвалилась, просто по таймауту. Тогда товар на складе забронирован, а статус корзины не поменялся. Нужно писать код для отката. ·>Это эквивалентно ситуации: клиент наполнил корзину и ушел плюнув, потому что левая пятка зачесалась. Код отката брони на складе ты будешь писать в любом случае.
Не эквивалентно и не придется такое писать. Это твои фантазии
G>>Идемпотентной такую операцию уже не сделаешь и автоповтор со стороны клиента тоже. ·>Почему? Присваиваешь заявке на бронирование uuid и долбишь склад до посинения.
То ест мало того, что для обработки отмены ты вынужден будешь сохранить почти весь order в в той же транзакции, что и обновление остатков, так еще и дополнишь его полем ключа идемпотентности
G>>·>Да не важно. Подставь любую другую очень "нужную" фичу, которая есть в svn но нет в git. G>>Так в том и дело, что у СВНа не было преимуществ перед Гит. У Гита был один недостаток — сложность использования, до сих пор два из трех программистов не умеют в гит. ·>Многие носились с номерами ревизий. Коммит 23414 выглядит на порядок лучше, чем 21f0c36f3cef976789d9c65c16198a7c14f7b272. А ещё отдельные чекауты подветок, локи, явные переименования, и т.п. Многие заявляют "нам нужно".
Я уверен что и сейчас svn найдет сторонников, потому что он все еще в разы проще git. Аргументы будут самые неразумные.
G>>·>Суть моей аналогии, что твоё "нам нужно [xxx]" ты исходишь не из постановки бизнес-задачи, а из конкретного решения в виде монолитной архитектуры и гигантской всемогущей субд в виде одного процесса. G>>СУБД умеет ровно то, что у умеет — Атомарные изолированные транзакции, сохраняющие согласованность данных и гарантирующие надежность. G>>Любые реализации таких гарантий вручную дают менее надежный и менее производительный код, который не имеет преимуществ. Никакая теория и философия еще ни разу никому помогли сделать лучше транзакций в БД там, где транзакции решают проблему. ·>Теория простая: CAP-теорема.
Пока ты пишешь на один сервер тебя cap вообще не интересует.
G>>>>·>Да не важно. СУБД это просто такой готовый процесс. G>>>>Угу, процесс который умеет это делать, в отличие от твоего процесса, который по умолчанию не умеет и надо прям поприседать чтобы умел. G>>·>Речь о другом — процесс не один. Можно иметь две субд, в каждой свои локальные транзакции. G>>И что это даст? Неатомарное, несогласованное, неизолированное изменение данных? В чем смысл? ·>Чтоб работало.
Только оно не рабоает.
G>>>>>>Как это связано? Если они все приходят в итоге на одни сервер? бд например, то задача решаема. G>>Один кластер — один мастер для записи и 15 реплик для чтения. Все транзакции меняющие данные ходят на один сервер. ·>Ок, почитал. Цитатки: ·>"continue to migrate, shardable, write-heavy workloads to sharded systems as Azure Cosmos DB". ·>"no longer allow adding new tables to the current PostgreSQL deployment". ·>"we're not ruling out sharding PostreSQL in the future" ·>"move complex join logic to the application layer" ·>"caching layer"
И? они все еще на Postgres с одним мастером, и все работает
Как-то работает, и CAP не мешает.
А все что они рассматривают никак не противоречит сказанному выше.
·>Хорошо подытожено: "It's Scaling PostgresNoSQL, not Scaling PostgreSQL, as this is full of NoSQL solutions: eventually consistent, cascading read replicas, sharding for write-heavy workloads, offload to purpose-built CosmosDB, lazy writes, cache limiting, no new create/alter table, schemaless, avoid complex multi-table joins..." ·>Но в главном-то ты прав: "все приходят в итоге на одни сервер".
Там где не нужна целостность всегда можно вынести. Но мы же рассматриваем задачу где она нужна.
G>>·>Он может просто лечь, и без нагрузки. G>>Сам? Просто так? Реплик нет? Админов нет? Какой смысл это рассматривать как реалистичный сценарий? G>>Ну даже допустим что у вас сервер может лечь, вы его надежность оцениваете как число X в интервале (0;1) — оба конца не включены. G>>Если рассмотреть сценарий выше с покупкой товаров в ОЗОН и разнесением транзакций на два сервера, то общая надежность будет равна X^2, что строго меньше Х. То есть надежность двух серверов ниже. ·>Ты, видимо, сервер и сервис путаешь. Один сервис может работать как несколько инстансов, нет требования монолитности. И внезапно надёжность сервиса выше, если он работает на нескольких серверах.
Это ты путаешь stateless и stateful. В stateless сервисе ты можешь поднять несколько инстансов на разных серверах и если один перестанет отвечать другие смогут ответить.
Но когда мы рассматриваем stateful (а база данных это statful сервис), то при нескольких экземплярах мы наталкиваемся на CAP ограничения — мы можем или терять консистентность (что запрещено по условиям задачи) или доступность. Причем потерю доступности можно посчитать. Доступность системы из двух stateful узлов равна произведению доступности серверов, которая меньше доступности одного сервера. Априори считаем все серверы имеют одинаковую доступность.
Поэтому чтобы не заниматься сложной схемой отказоустойчивости и распределенными транзакциями выбирают обычную master-slave репликацию, когда все записи приходят в одну ноду.
G>>>>Этой проблемы просто не будет, мы никогда не продадим больше чем есть на складе если резервирование сделаем транзакционно. G>>·>Я не понимаю как "пользователь плюёт" соотносится с "не продадим больше". G>>Это относится к недостаткам решения. Так как "пользователь плюет" это потеря денег. Потому что дальше пользователь идет на другой маркетплейс и к тебе возможно уже не возвращается никогда ·>"резервирование сделаем транзакционно" не решает проблему "пользователь плюет".
Конечно решает, потому что пользователь после резервации на складе точно получит свой заказ.
G>>>>Ту самую, которую ты непонятно как хочешь решить. G>>·>Это какую? G>>Чтобы пользователь придя за своим товаром получил его. ·>Для этого не требуется обновлять корзину и склад в одной транзакции.
Я уже выше описал почему требуется. Не повторяй эту глупость уже
G>>·>Почему? Напомню контекст: МСА. G>>Выше все описал. Без МСА получается лучше. ·>Не получается. Проще — да, но по многим другим параметрам — хуже.
Ты делаешь утвреждения, но даже не пытаешься из доказывать. Думаю просто потому что у тебя нет объективных аргументов.
G>>>>Ага, и в этом случае статус может стать "зарезервирован", а остаток на складе не уменьшится, и ты будешь разговаривать с недовольными покупателями. G>>·>Пока сервис склада не вернёт ответ "резервация прошла успешно" мы не обновляем статус заказа в сервисе заказов. G>>Тогда в этом нет никакого смысла, потому что недостатки есть, а преимуществ нет. ·>Можно продолжать работать с корзиной, например, позволять добавлять товары ещё, обновлять адрес доставки, применять скидки и купоны и т.п.
Лол, а зачем?
Re[26]: Помогите правильно спроектировать микросервисное при
G>·>Судя по твоим заявлениям: транзакционно обновляют состояние корзины с резервов на складе. G>Это часть того, что они делают.
Ещё раз. Это не задача, а конкретное решение. С таким же смыслом можно заявлять, что они, например, логи пишут и байты по проводам передают.
G>>>В основном товары со склада продает. Вот и надо продать не больше чем есть. G>·>Для этого нет необходимости транзакционно обновлять состояние корзины с резервов на складе. G>Ты не понимаешь суть задачи G>две сущности Order (id, status, lines(product_id, q)) и Stock (product_id, reserverd, limit). При смене статуса в Order мы меняем состояние резервов в Stock. G>При подтверждении заказа — увеличиваем reserved в stock для каждого line в order. А при отмене уменьшаем. G>Если мы это не делаем в одной транзакции, то как ты потом уменьшишь, если статус не удалось сменить?
Так же, как если клиент набрал кучу товаров, они зарезервировались, но не смог оплатить. Резерв нужно откатывать.
G>Сохранишь копию order в то же базе в той же тразакции, да? G>Ты наверное начнешь разговор что так делать не надо. Но озону надо. Потому что разница limit-reserverd отображается в интерфейсе приложения как "сколько осталось" и это отображается прямо в результатах поиска, то есть надо быстро получать это число для любого количества товаров.
Сохранять копии? Конечно, не надо.
G>·>Зато будет работать хотя бы. G>Не лучше, чем в одной базе. Прям строго математически не лучше.
В крупных магазинах такое вообще работать не будет.
G>·>Это эквивалентно ситуации: клиент наполнил корзину и ушел плюнув, потому что левая пятка зачесалась. Код отката брони на складе ты будешь писать в любом случае. G>Не эквивалентно и не придется такое писать. Это твои фантазии
Как не придётся? Что делать, когда корзина создана, товары зарезервированы, а пользователь закрыл браузер и ушел с концами?
G>>>Идемпотентной такую операцию уже не сделаешь и автоповтор со стороны клиента тоже. G>·>Почему? Присваиваешь заявке на бронирование uuid и долбишь склад до посинения. G>То ест мало того, что для обработки отмены ты вынужден будешь сохранить почти весь order в в той же транзакции, что и обновление остатков, так еще и дополнишь его полем ключа идемпотентности
Зачем его сохранять? Заявка — это сообщение. Ты вообще что-ли не понимаешь как делают идемпотентность?
G>>>Так в том и дело, что у СВНа не было преимуществ перед Гит. У Гита был один недостаток — сложность использования, до сих пор два из трех программистов не умеют в гит. G>·>Многие носились с номерами ревизий. Коммит 23414 выглядит на порядок лучше, чем 21f0c36f3cef976789d9c65c16198a7c14f7b272. А ещё отдельные чекауты подветок, локи, явные переименования, и т.п. Многие заявляют "нам нужно". G>Я уверен что и сейчас svn найдет сторонников, потому что он все еще в разы проще git. Аргументы будут самые неразумные.
А совсем проще всего — вообще не использовать системы контроля версий. И что? Как и всегда в жизни: у любой, даже самой сложной задачи есть очевидное, простое, понятное, неправильное решение.
G>>>СУБД умеет ровно то, что у умеет — Атомарные изолированные транзакции, сохраняющие согласованность данных и гарантирующие надежность. G>>>Любые реализации таких гарантий вручную дают менее надежный и менее производительный код, который не имеет преимуществ. Никакая теория и философия еще ни разу никому помогли сделать лучше транзакций в БД там, где транзакции решают проблему. G>·>Теория простая: CAP-теорема. G>Пока ты пишешь на один сервер тебя cap вообще не интересует.
Это плохого архитектора вообще cap не интересует. Вот правда теореме пофиг, интересует она кого-то или нет, она работает всегда.
G>>>·>Речь о другом — процесс не один. Можно иметь две субд, в каждой свои локальные транзакции. G>>>И что это даст? Неатомарное, несогласованное, неизолированное изменение данных? В чем смысл? G>·>Чтоб работало. G>Только оно не рабоает.
Ну ты хочешь чтобы я тут описывал как строятся МСА системы? Мне очень лень, но можешь почитать, например, тут: https://medium.com/@CodeWithTech/the-saga-design-pattern-coordinating-long-running-transactions-in-distributed-systems-edbc9b9a9116
G>И? они все еще на Postgres с одним мастером, и все работает
В смысле? У них postgres в режиме deprecated. Т.к. дорого всё распилить, т.к. надо переделывать всё. Сказано же: "no longer allow adding new tables". Кто-то гениальный запилил им монолит, вот теперь страдают.
G>·>Но в главном-то ты прав: "все приходят в итоге на одни сервер". G>Там где не нужна целостность всегда можно вынести. Но мы же рассматриваем задачу где она нужна.
Ну у них не получилось. Все эти многослойные кеши и реплики — это уже отказ от целостности.
G>·>Ты, видимо, сервер и сервис путаешь. Один сервис может работать как несколько инстансов, нет требования монолитности. И внезапно надёжность сервиса выше, если он работает на нескольких серверах. G>Это ты путаешь stateless и stateful. В stateless сервисе ты можешь поднять несколько инстансов на разных серверах и если один перестанет отвечать другие смогут ответить. G>Но когда мы рассматриваем stateful (а база данных это statful сервис), то при нескольких экземплярах мы наталкиваемся на CAP ограничения — мы можем или терять консистентность (что запрещено по условиям задачи) или доступность.
В задаче корзина-склад — достаточно eventual consistency.
G>Причем потерю доступности можно посчитать. Доступность системы из двух stateful узлов равна произведению доступности серверов, которая меньше доступности одного сервера. Априори считаем все серверы имеют одинаковую доступность. G>Поэтому чтобы не заниматься сложной схемой отказоустойчивости и распределенными транзакциями выбирают обычную master-slave репликацию, когда все записи приходят в одну ноду.
Такое требуется в очень редких задачах. И там обычно используют какой-нибудь event sourcing, а не acid субд.
G>>>Это относится к недостаткам решения. Так как "пользователь плюет" это потеря денег. Потому что дальше пользователь идет на другой маркетплейс и к тебе возможно уже не возвращается никогда G>·>"резервирование сделаем транзакционно" не решает проблему "пользователь плюет". G>Конечно решает, потому что пользователь после резервации на складе точно получит свой заказ. "пользователь плюёт" — это означает что он не ничего хочет оплачивать и уж тем более получать свой заказ. Но зарезервированные товары хочет получить совершенно другой пользователь.
G>>>Чтобы пользователь придя за своим товаром получил его. G>·>Для этого не требуется обновлять корзину и склад в одной транзакции. G>Я уже выше описал почему требуется. Не повторяй эту глупость уже
Ещё раз. Если выполнять вначале транзакцию резервации, потом другую транзакцию для смены статуса заказа — то мы гарантируем, что товар будет в наличии после оплаты заказа.
Существует только проблема того, что товар зарезервирован, но не оплачен. Нужен ещё процесс отмены резерва. И твоя транзакция ничем не помогает, никакую проблему она не решает.
G>·>Можно продолжать работать с корзиной, например, позволять добавлять товары ещё, обновлять адрес доставки, применять скидки и купоны и т.п. G>Лол, а зачем?
Ага. Раз такого в Озоне нет, то это никому не нужно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
G>>>>В основном товары со склада продает. Вот и надо продать не больше чем есть. G>>·>Для этого нет необходимости транзакционно обновлять состояние корзины с резервов на складе. G>>Ты не понимаешь суть задачи G>>две сущности Order (id, status, lines(product_id, q)) и Stock (product_id, reserverd, limit). При смене статуса в Order мы меняем состояние резервов в Stock. G>>При подтверждении заказа — увеличиваем reserved в stock для каждого line в order. А при отмене уменьшаем. G>>Если мы это не делаем в одной транзакции, то как ты потом уменьшишь, если статус не удалось сменить? ·>Так же, как если клиент набрал кучу товаров, они зарезервировались, но не смог оплатить. Резерв нужно откатывать.
Нужно, это другой сценарий. Далеко не то же самое, что откат незавершенной резервации.
G>>Сохранишь копию order в то же базе в той же тразакции, да? G>>Ты наверное начнешь разговор что так делать не надо. Но озону надо. Потому что разница limit-reserverd отображается в интерфейсе приложения как "сколько осталось" и это отображается прямо в результатах поиска, то есть надо быстро получать это число для любого количества товаров. ·>Сохранять копии? Конечно, не надо.
А что тогда делать для отката незавершенной резервации?
G>>·>Зато будет работать хотя бы. G>>Не лучше, чем в одной базе. Прям строго математически не лучше. ·>В крупных магазинах такое вообще работать не будет.
Ты можешь как-то обосновать свои слова?
G>>·>Это эквивалентно ситуации: клиент наполнил корзину и ушел плюнув, потому что левая пятка зачесалась. Код отката брони на складе ты будешь писать в любом случае. G>>Не эквивалентно и не придется такое писать. Это твои фантазии ·>Как не придётся? Что делать, когда корзина создана, товары зарезервированы, а пользователь закрыл браузер и ушел с концами?
Это другой сценарий, мы его сейчас не рассматриваем.
Не надо придумывать новые кейсы, придумай как сделать хорошо один. Потом будем другие рассматривать.
Пока у тебя ничего внятного не получилось.
G>>>>Идемпотентной такую операцию уже не сделаешь и автоповтор со стороны клиента тоже. G>>·>Почему? Присваиваешь заявке на бронирование uuid и долбишь склад до посинения. G>>То ест мало того, что для обработки отмены ты вынужден будешь сохранить почти весь order в в той же транзакции, что и обновление остатков, так еще и дополнишь его полем ключа идемпотентности ·>Зачем его сохранять? Заявка — это сообщение. Ты вообще что-ли не понимаешь как делают идемпотентность?
Я понимаю как делают идемпотентность. Я не понимаю как ты её хочешь сделать.
Можешь привести пример кода?
G>>>>Так в том и дело, что у СВНа не было преимуществ перед Гит. У Гита был один недостаток — сложность использования, до сих пор два из трех программистов не умеют в гит. G>>·>Многие носились с номерами ревизий. Коммит 23414 выглядит на порядок лучше, чем 21f0c36f3cef976789d9c65c16198a7c14f7b272. А ещё отдельные чекауты подветок, локи, явные переименования, и т.п. Многие заявляют "нам нужно". G>>Я уверен что и сейчас svn найдет сторонников, потому что он все еще в разы проще git. Аргументы будут самые неразумные. ·>А совсем проще всего — вообще не использовать системы контроля версий.
Альтернатива какая? передавать архивами и мерить вручную?
G>>>>·>Речь о другом — процесс не один. Можно иметь две субд, в каждой свои локальные транзакции. G>>>>И что это даст? Неатомарное, несогласованное, неизолированное изменение данных? В чем смысл? G>>·>Чтоб работало. G>>Только оно не рабоает. ·>Ну ты хочешь чтобы я тут описывал как строятся МСА системы? Мне очень лень, но можешь почитать, например, тут: https://medium.com/@CodeWithTech/the-saga-design-pattern-coordinating-long-running-transactions-in-distributed-systems-edbc9b9a9116
Не надо ссылок, просто приведи пример кода как бы ты сделал резервацию заказа.
G>>И? они все еще на Postgres с одним мастером, и все работает ·>В смысле? У них postgres в режиме deprecated. Т.к. дорого всё распилить, т.к. надо переделывать всё. Сказано же: "no longer allow adding new tables". Кто-то гениальный запилил им монолит, вот теперь страдают.
Да уж, страдают....
G>>·>Но в главном-то ты прав: "все приходят в итоге на одни сервер". G>>Там где не нужна целостность всегда можно вынести. Но мы же рассматриваем задачу где она нужна. ·>Ну у них не получилось. Все эти многослойные кеши и реплики — это уже отказ от целостности.
Если ты не пишешь данные, на основе результатов чтения из отстающей реплики, то нарушения целостности нет.
G>>·>Ты, видимо, сервер и сервис путаешь. Один сервис может работать как несколько инстансов, нет требования монолитности. И внезапно надёжность сервиса выше, если он работает на нескольких серверах. G>>Это ты путаешь stateless и stateful. В stateless сервисе ты можешь поднять несколько инстансов на разных серверах и если один перестанет отвечать другие смогут ответить. G>>Но когда мы рассматриваем stateful (а база данных это statful сервис), то при нескольких экземплярах мы наталкиваемся на CAP ограничения — мы можем или терять консистентность (что запрещено по условиям задачи) или доступность. ·>В задаче корзина-склад — достаточно eventual consistency.
Покажи пример кода
G>>Причем потерю доступности можно посчитать. Доступность системы из двух stateful узлов равна произведению доступности серверов, которая меньше доступности одного сервера. Априори считаем все серверы имеют одинаковую доступность. G>>Поэтому чтобы не заниматься сложной схемой отказоустойчивости и распределенными транзакциями выбирают обычную master-slave репликацию, когда все записи приходят в одну ноду. ·>Такое требуется в очень редких задачах. И там обычно используют какой-нибудь event sourcing, а не acid субд.
Именно, а в более простых случаях вполне достаточно одного мастера. Вот у OpenAI простой случай. Я правда не представляю у кого он не простой.
G>>>>Чтобы пользователь придя за своим товаром получил его. G>>·>Для этого не требуется обновлять корзину и склад в одной транзакции. G>>Я уже выше описал почему требуется. Не повторяй эту глупость уже ·>Ещё раз. Если выполнять вначале транзакцию резервации, потом другую транзакцию для смены статуса заказа — то мы гарантируем, что товар будет в наличии после оплаты заказа. ·>Существует только проблема того, что товар зарезервирован, но не оплачен. Нужен ещё процесс отмены резерва. И твоя транзакция ничем не помогает, никакую проблему она не решает.
Да ты сначала сделай процесс резервирования надежным, потом про оплату поговорим.
G>>·>Можно продолжать работать с корзиной, например, позволять добавлять товары ещё, обновлять адрес доставки, применять скидки и купоны и т.п. G>>Лол, а зачем? ·>Ага. Раз такого в Озоне нет, то это никому не нужно.
Так мы сейчас про конкретную задачу говорим, как в озоне.
Re[26]: Помогите правильно спроектировать микросервисное при
Здравствуйте, gandjustas, Вы писали:
G>Сохранишь копию order в то же базе в той же тразакции, да?
Техническое решение этой задачи для микросервисов уже обсуждалось. Да, оно в каком-то смысле "хуже", чем единая ACID-транзакция — у заказа появляется некое промежуточное состояние, которого не было в исходной реализации.
Но давайте прекратим делать вид, что этого решения нет, т.к. это состояние — эфемерное, и фактически время его жизни равно времени даунтайма сервиса склада с точки зрения сервиса корзинки.
G>Ты наверное начнешь разговор что так делать не надо. Но озону надо. Потому что разница limit-reserverd отображается в интерфейсе приложения как "сколько осталось" и это отображается прямо в результатах поиска, то есть надо быстро получать это число для любого количества товаров.
Микросервисы никак не мешают быстрому показу remaining — скорее наоборот, т.к. RDBMS склада вообще не обрабатывает никакой нагрузки, кроме вот этого вот get remaining и reserve stock / unreserve stock / top-up stock.
Кроме того, её можно шардить — т.к. сами товары друг на друга никак не завязаны, можно держать первые 10000 позиций в одном сервере, вторые 10000 — в другом, и так далее.
Не, я в курсе, что как только мы начнём джойнить эту информацию с какими-нибудь запросами по другой части домена (типа "робот-пылесос в пределах 20000 рублей с доставкой до послезавтра и средним баллом по отзывам не ниже 4.9"), то МСА со страшной силой сольёт монолиту. Вот только если мы всё же уперлись в потолок монолита, то возможность получить 2х перформанс ценой распиливания его на 8х частей может оказаться единственным выбором.
G>Не лучше, чем в одной базе. Прям строго математически не лучше.
Да, но с учётом нюансов, указанных выше. Пока мы не упёрлись в пределы монолита и при отсутствии административных причин, монолит будет строго математически лучше.
G>>>Более того, возможен сценарий когда первая выполнилась, а вторая отвалилась, просто по таймауту. Тогда товар на складе забронирован, а статус корзины не поменялся. Нужно писать код для отката. G>·>Это эквивалентно ситуации: клиент наполнил корзину и ушел плюнув, потому что левая пятка зачесалась. Код отката брони на складе ты будешь писать в любом случае. G>Не эквивалентно и не придется такое писать. Это твои фантазии
Нет, откат писать не надо. Надо писать "накат". И это можно сделать один раз в инфраструктуре worflow-engine. Типа вот мы поднялись после сбоя и видим, что корзинка №42342342 была отправлена на резервирование, а результата резервирования нет. Значит, либо мы в прошлый раз не достучались до сервера (получили сonnection timeout), либо достучались да он упал до начала резервирования (отдал нам 5хх), либо упал после окончания резервирования (и отдал нам 5хх или connection reset by peer), либо всё нам отдал, да мы расплескали по пути и упали до коммита в локальную БД.
Во всех случаях мы тупо идём и повторяем резерв. При необходимости — сколько угодно раз, пока нам таки не удастся записать к себе "успех" либо "фейл". На практике, длинные даунтаймы тут бывают не чаще, чем даунтаймы у монолита. Только у монолита лежит вообще всё, а у МСА можно хотя бы в корзинку что-то складывать да отзывы читать.
G>То ест мало того, что для обработки отмены ты вынужден будешь сохранить почти весь order в в той же транзакции, что и обновление остатков, так еще и дополнишь его полем ключа идемпотентности
Да, объекты, пересекающие границы сервисов, в МСА должны храниться на обеих сторонах. Это не обязательно одни и те же объекты, но у них должна быть общая проекция. В данном случае сторону склада не интересуют никакие подробности про способы доставки товара, розничные цены, или там демографию покупателя, но вот список артикулов и количеств, снабжённый уникальным ID, ей необходим. Ровно для того, чтобы когда к нему в следующий раз стукнутся с просьбой зарезервировать корзинку №42342342 он мог не делать повторный резерв, а сразу отдать 200 ok.
G>·>Теория простая: CAP-теорема. G>Пока ты пишешь на один сервер тебя cap вообще не интересует.
Совершенно верно.
G>Только оно не рабоает.
Это слишком сильное утверждение в рамках данной дискуссии
G>Но когда мы рассматриваем stateful (а база данных это statful сервис), то при нескольких экземплярах мы наталкиваемся на CAP ограничения — мы можем или терять консистентность (что запрещено по условиям задачи) или доступность. Причем потерю доступности можно посчитать. Доступность системы из двух stateful узлов равна произведению доступности серверов, которая меньше доступности одного сервера. Априори считаем все серверы имеют одинаковую доступность.
Зато доступность строго согласованной системы из трёх stateful узлов уже выше, одного узла — при условии, что надёжность связей между ними выше определённого предела
CAP-теорема как раз и намекает на то, что если каналы не 100% надёжны (P), то получить 100% доступность невозможно даже для 100% надёжных узлов. Но этот тривиальный факт никак не помогает инженерному дизайну — потому что как вы будете поднимать доступность вашего единственного узла за пределы его нормативных способностей?
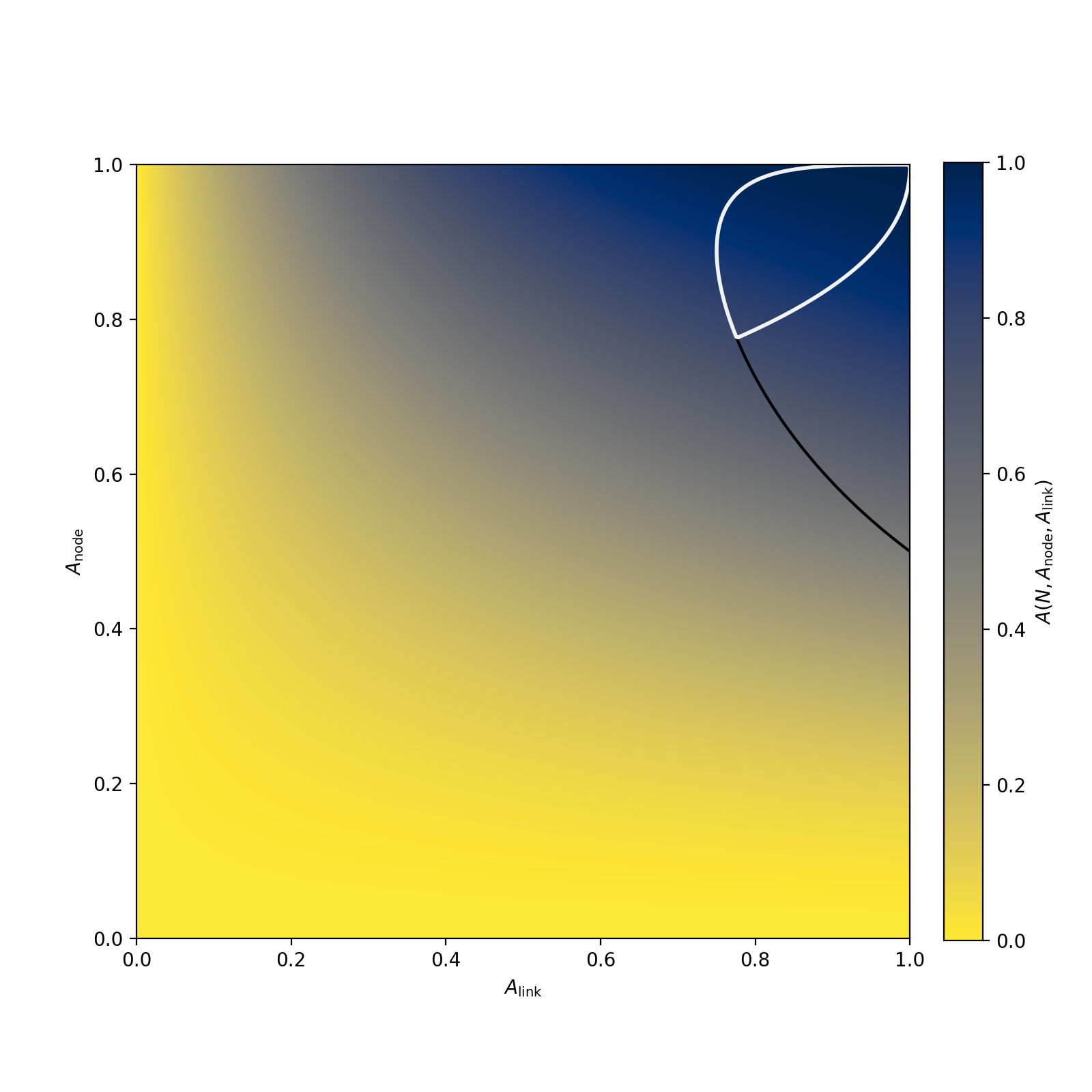
Вот картинка для доступности строго согласованного кластера из трёх узлов с доступностью Anode, связанных каналами с доступностью Alink:
Белый контур — это зона, где эта доступность выше доступности каждого из компонентов.
G>·>"резервирование сделаем транзакционно" не решает проблему "пользователь плюет". G>Конечно решает, потому что пользователь после резервации на складе точно получит свой заказ.
В нашем случае пользователь после резервации на складе тоже точно получит свой заказ. Вся разница — в том, что если будет сбой системы во время заказа, то пользователь монолита до окончания сбоя будет получать 502, а пользователь МСА имеет шанс в это время увидеть спиннер "заказ резервируется....".
В любом случае результат резервирования станет известен только по окончанию сбоя — и точно так же, как в монолитном случае можно получить как подтверждение успеха, так и "извините, но другой покупатель успел зарезервировать товар до вас".
G>·>Для этого не требуется обновлять корзину и склад в одной транзакции. G>Я уже выше описал почему требуется. Не повторяй эту глупость уже
При всём уважении — это не глупость, а вполне себе математическая реальность. Я выше написал, как именно это работает. G>Лол, а зачем?
Затем, что в реальном приложении — сотни бизнес-сценариев. Остановка на техобслуживание одного из сервисов задержит только те сценарии, которые проходят через него. И если этот сервис достаточно простой и маленький, то его рестарт не будет занимать десятки минут. Таким образом, perceived availability может оказаться значительно выше, чем у монолита. Ну вот, абстрактно, мы на пять минут отключили банковское ядро, которое собственно проводит платежи. Если всё сделано по уму, то пользователи это увидят только как "странно, я вроде по СБП деньги отправил, а у получателя телефон что-то не вибрирует". Если чуть хуже — то как "переводы пока недоступны, приходите позже". Если ещё хуже — то как "Непредвиденная ошибка. Перезапустите приложение или зайдите позже". И в любом из этих случаев люди, которые смотрят какую-нибудь там аналитику расходов, или остатки по вкладам, или условия кредитов/страховок/етк не заметят вообще ничего. С их точки зрения никакого сбоя не было. А если нам нужно сделать то же самое в монолите, то опускать нужно примерно всё, и всё будет лежать сразу у всех пользователей.
Не факт, что это прямо плохо. Не факт, что это прямо настолько плохо, что стоит многократного роста вычислительной и когнитивной нагрузки, сопровождающего переход от монолита к (микро)-сервисам. Но для полноты картины имеет смысл рассматривать и такие сценарии, не пытаясь искусственно обесценить такие требования или там сочинять недостатки модели, которых в реальности нет.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[27]: Помогите правильно спроектировать микросервисное при
G>>Не лучше, чем в одной базе. Прям строго математически не лучше. S>Да, но с учётом нюансов, указанных выше. Пока мы не упёрлись в пределы монолита и при отсутствии административных причин, монолит будет строго математически лучше.
Стоит ещё уточнить, что "математически лучше" — это плохой критерий для выбора решения. Нужно ещё не забывать о физике. Было бы математически лучше, если б я взмахнул руками и полетел, но физику с гравитацией это не устраивает, разрешает только строго вниз летать.
Так и тут, математически лучше чтобы всё работало в одной центральной точке. Но пользователи, склад, корзина, товары, платежи, курьеры — это всё разные физически разделённые сущности.
ЗЫЖ Спасибо за хороший ответ. А то я уже устал ему отвечать
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, gandjustas, Вы писали:
G>>>Если мы это не делаем в одной транзакции, то как ты потом уменьшишь, если статус не удалось сменить? G>·>Так же, как если клиент набрал кучу товаров, они зарезервировались, но не смог оплатить. Резерв нужно откатывать. G>Нужно, это другой сценарий. Далеко не то же самое,
В каком месте это не то же самое? Опять же. Ты рассматривай не одно конкретное решение одного конкретного сценария "транзакционно обновлять состояние", а изначальную бизнес-задачу: "продавать товары со склада клиентам". И выясняется что сценариев несколько, и они должны работать все.
G>что откат незавершенной резервации.
Резервация — это локальная атомарная транзакция Склада. Она либо завершена (все позиции доступны на складе и всё сработало), либо нет (чего-то не хватает, чего-то упало, етс).
Неатомарным является согласование _статуса_ Корзины со _статусом_ Резервации. И таковым оно является не потому что мы не затолкали всё на один центральный сервер, а потому что это разные физически независимые бизнес-сущности.
G>·>Сохранять копии? Конечно, не надо. G>А что тогда делать для отката незавершенной резервации?
Для отката незавершенной резервации — ровно то же, что и для "если клиент набрал кучу товаров, они зарезервировались, но не смог оплатить."
G>·>В крупных магазинах такое вообще работать не будет. G>Ты можешь как-то обосновать свои слова?
Могу, но лень. Можешь поискать как устроены всякие Амазоны с Ебеями. Или вообще погляди как какими-нибудь акциями какие-нибудь биржи торгуют.
G>·>Как не придётся? Что делать, когда корзина создана, товары зарезервированы, а пользователь закрыл браузер и ушел с концами? G>Это другой сценарий, мы его сейчас не рассматриваем.
Этот сценарий является ответом на твой вопрос: "А что тогда делать для отката незавершенной резервации?".
G>Не надо придумывать новые кейсы, придумай как сделать хорошо один. Потом будем другие рассматривать. G>Пока у тебя ничего внятного не получилось.
Мде. См. ответ от Sinclair.
G>·>Зачем его сохранять? Заявка — это сообщение. Ты вообще что-ли не понимаешь как делают идемпотентность? G>Я понимаю как делают идемпотентность. Я не понимаю как ты её хочешь сделать. G>Можешь привести пример кода?
Пример кода чего?
G>>>·>Многие носились с номерами ревизий. Коммит 23414 выглядит на порядок лучше, чем 21f0c36f3cef976789d9c65c16198a7c14f7b272. А ещё отдельные чекауты подветок, локи, явные переименования, и т.п. Многие заявляют "нам нужно". G>>>Я уверен что и сейчас svn найдет сторонников, потому что он все еще в разы проще git. Аргументы будут самые неразумные. G>·>А совсем проще всего — вообще не использовать системы контроля версий. G>Альтернатива какая? передавать архивами и мерить вручную?
Типа того. Ведь это — самое простое. А мержить — совсем слишком сложно, ведь в разы проще договориться, кто какой файл когда меняет.
G>>>·>Чтоб работало. G>>>Только оно не рабоает. G>·>Ну ты хочешь чтобы я тут описывал как строятся МСА системы? Мне очень лень, но можешь почитать, например, тут: https://medium.com/@CodeWithTech/the-saga-design-pattern-coordinating-long-running-transactions-in-distributed-systems-edbc9b9a9116 G>Не надо ссылок, просто приведи пример кода как бы ты сделал резервацию заказа.
Ну вот там по ссылке как раз примеры кода.
G>>>И? они все еще на Postgres с одним мастером, и все работает G>·>В смысле? У них postgres в режиме deprecated. Т.к. дорого всё распилить, т.к. надо переделывать всё. Сказано же: "no longer allow adding new tables". Кто-то гениальный запилил им монолит, вот теперь страдают. G>Да уж, страдают....
Ну да, ну да. На самом деле они наслаждаются SEV-ами и outages. Ты статью-то читал? https://openai.com/index/scaling-postgresql/
G>>>Там где не нужна целостность всегда можно вынести. Но мы же рассматриваем задачу где она нужна. G>·>Ну у них не получилось. Все эти многослойные кеши и реплики — это уже отказ от целостности. G>Если ты не пишешь данные, на основе результатов чтения из отстающей реплики, то нарушения целостности нет.
Я, честно говоря, не знаю как у них что там устроено. Не буду сочинять.
G>·>В задаче корзина-склад — достаточно eventual consistency. G>Покажи пример кода
Какого именно кода? Там по ссылке выше есть какие-то примеры.
G>·>Такое требуется в очень редких задачах. И там обычно используют какой-нибудь event sourcing, а не acid субд. G>Именно, а в более простых случаях вполне достаточно одного мастера. Вот у OpenAI простой случай. Я правда не представляю у кого он не простой.
Если бы им было достаточно, они бы не начали переезжать на Cosmos DB.
G>Да ты сначала сделай процесс резервирования надежным, потом про оплату поговорим.
См. ответ от Sinclair.
G>>>·>Можно продолжать работать с корзиной, например, позволять добавлять товары ещё, обновлять адрес доставки, применять скидки и купоны и т.п. G>>>Лол, а зачем? G>·>Ага. Раз такого в Озоне нет, то это никому не нужно. G>Так мы сейчас про конкретную задачу говорим, как в озоне.
Ты заявил "Тогда в этом нет никакого смысла". Конечно, если весь озон состоял из ровно одного сценария и решал ровно одну задачу, то смысла нет. Но, по-моему, "ранзакционно обновлять состояние корзины с резервов на складе" — это не единственное, чем занимается озон.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, gandjustas, Вы писали:
G>>Сохранишь копию order в то же базе в той же тразакции, да? S>Техническое решение этой задачи для микросервисов уже обсуждалось. Да, оно в каком-то смысле "хуже", чем единая ACID-транзакция — у заказа появляется некое промежуточное состояние, которого не было в исходной реализации. S>Но давайте прекратим делать вид, что этого решения нет, т.к. это состояние — эфемерное, и фактически время его жизни равно времени даунтайма сервиса склада с точки зрения сервиса корзинки.
ИМХО ACID-транзакция, изобретенная на другом уровне абстракции — все равно транзакция. Если говорить то том, какие транзакции стоит использовать — самопальные или предоставляемые БД, то любой вменяемый разработчик выберет второй вариант.
Единственная причина применять самопал — когда нет возможности применить транзакции в БД.
Чтобы говорить об одном и том же давай зафиксируем детали о которых шла речь:
— Я предлагаю состояние заказа менять в одной транзакции с обновлением остатков. Заказы и остатки естественно должны быть в одной базе
— МСА предлагает сделать две базы, где заказы лежат в одной, а заказы в другой.
Написать код вида:
1. обнови остатки в базе А
2. обнови статус заказа в базе Б
3. если появилась ошибка, то откати обновление в базе А
Если код падает по между шагами 2 и 3, то в базе остается несогласованное состояние.
Значит вместе самим кодом резервирования заказа надо написать еще фоновую задачу, которая откатывает незавершенные резервы.
Я проделал аналогичное в рамках статьи на хабре, результаты неутешительные — https://habr.com/ru/articles/963120/ см раздел "рукопашные транзакции".
Но у нас транзакции не изолированные, то есть межу 1 и 2 может вклиниться изменение, которое обновит заказ.
Это значит что для корректного кода отказа как в фоне, так и в п3 надо сохранять "слепок" заказа на шаге 1.
Этот слепок — это в чистом виде wal log.
G>>Ты наверное начнешь разговор что так делать не надо. Но озону надо. Потому что разница limit-reserverd отображается в интерфейсе приложения как "сколько осталось" и это отображается прямо в результатах поиска, то есть надо быстро получать это число для любого количества товаров. S>Микросервисы никак не мешают быстрому показу remaining — скорее наоборот, т.к. RDBMS склада вообще не обрабатывает никакой нагрузки, кроме вот этого вот get remaining и reserve stock / unreserve stock / top-up stock.
Получение остатков это запрос к одной таблице. Ему никакая МСА не помешает.
S>Кроме того, её можно шардить — т.к. сами товары друг на друга никак не завязаны, можно держать первые 10000 позиций в одном сервере, вторые 10000 — в другом, и так далее.
Шардить можно и без МСА. Это вообще ортогональные вещи.
S>Не, я в курсе, что как только мы начнём джойнить эту информацию с какими-нибудь запросами по другой части домена (типа "робот-пылесос в пределах 20000 рублей с доставкой до послезавтра и средним баллом по отзывам не ниже 4.9"), то МСА со страшной силой сольёт монолиту. Вот только если мы всё же уперлись в потолок монолита, то возможность получить 2х перформанс ценой распиливания его на 8х частей может оказаться единственным выбором.
Мы же упираемся не в монолит, а в производительность одного сервера БД. Тут есть несколько решений:
1) Кэши для чтения, чтобы нагрузка на БД не прилетала вообще.
2) Чтение из реплик, чтобы нагрузка на мастер не прилетала там где допустимо отдавать слегка устаревшие данные.
3) Партицирование таблиц — это как шардирование, только в пределах одного сервера БД, чтобы нагрузку на запись распределять по разным дискам.
И только когда все возможности исчерпаны — делать шардирование.
ИМХО в ни у одного веб-сайта или приложения нет такой нагрузки чтобы шардирование было оправдано.
Правда это пока мы живем в рамках монолитной базы. Как только мы начинаем её разделять на сервисы (подбазы), то у нас появляются дополнительные данные и процессы, необходимые для поддержания целостности. Выше как раз пример такого. И все это жрет ресурсы.
При достаточном количестве микросервисов система упирается в "потолок" одного сервера очень быстро.
G>>Не лучше, чем в одной базе. Прям строго математически не лучше. S>Да, но с учётом нюансов, указанных выше. Пока мы не упёрлись в пределы монолита и при отсутствии административных причин, монолит будет строго математически лучше.
Этот потолок сильно выше, чем кажется. При правильном подходе к проектированию до него доберутся единицы, а остальные от сложности проиграют только.
По моему опыту "потолок монолита" не в нагрузке, а тупо в размере команды. Когда у тебя 25 человек еще худо-бедно можно пилить монолит с общей кодовой базой. А если команда становится больше, то начинается деление, которое проходит ровно по границам подразделений. А если подразделения между собой не дружат и не имеют хорошего техлида над ними, то микросервисы помогают избежать бардака.
G>>>>Более того, возможен сценарий когда первая выполнилась, а вторая отвалилась, просто по таймауту. Тогда товар на складе забронирован, а статус корзины не поменялся. Нужно писать код для отката. G>>·>Это эквивалентно ситуации: клиент наполнил корзину и ушел плюнув, потому что левая пятка зачесалась. Код отката брони на складе ты будешь писать в любом случае. G>>Не эквивалентно и не придется такое писать. Это твои фантазии S>Нет, откат писать не надо. Надо писать "накат". И это можно сделать один раз в инфраструктуре worflow-engine.
Допустим
S>Типа вот мы поднялись после сбоя и видим, что корзинка №42342342 была отправлена на резервирование, а результата резервирования нет.
А как мы узнаем что его нет?
S>Значит, либо мы в прошлый раз не достучались до сервера (получили сonnection timeout), либо достучались да он упал до начала резервирования (отдал нам 5хх), либо упал после окончания резервирования (и отдал нам 5хх или connection reset by peer), либо всё нам отдал, да мы расплескали по пути и упали до коммита в локальную БД. S>Во всех случаях мы тупо идём и повторяем резерв. При необходимости — сколько угодно раз, пока нам таки не удастся записать к себе "успех" либо "фейл". На практике, длинные даунтаймы тут бывают не чаще, чем даунтаймы у монолита. Только у монолита лежит вообще всё, а у МСА можно хотя бы в корзинку что-то складывать да отзывы читать.
А пользователь все это время ждет?
А если он не дождался и ушел?
А если связь между пользователем и приложением пропала?
А если пользователь ушлый и пока в одной вкладе крутится ожидание открыл сайт в другой вкладке и пошел что-то менять?
G>>То ест мало того, что для обработки отмены ты вынужден будешь сохранить почти весь order в в той же транзакции, что и обновление остатков, так еще и дополнишь его полем ключа идемпотентности S>Да, объекты, пересекающие границы сервисов, в МСА должны храниться на обеих сторонах. Это не обязательно одни и те же объекты, но у них должна быть общая проекция. В данном случае сторону склада не интересуют никакие подробности про способы доставки товара, розничные цены, или там демографию покупателя, но вот список артикулов и количеств, снабжённый уникальным ID, ей необходим. Ровно для того, чтобы когда к нему в следующий раз стукнутся с просьбой зарезервировать корзинку №42342342 он мог не делать повторный резерв, а сразу отдать 200 ok.
Я понимаю, что при высокоуровневом взгляде кажется что это все просто, написать три-четыре строки в воркфлоу и будет хорошо. А на практике для обеспечения целостности нужны десятки строк кода и дополнительные данные хранить (что увеличивает нагрузку какбы).
И самое главное — ради чего это все? Чтобы не упереться в мифический "потолок монолита". С МСА этот потолок окажется очень низко.
S>Вот картинка для доступности строго согласованного кластера из трёх узлов с доступностью Anode, связанных каналами с доступностью Alink: S>Белый контур — это зона, где эта доступность выше доступности каждого из компонентов.
Это в каком контексте?
Насколько понимаю картинка эта для случая когда:
1) Есть несколько экземпляров ОДНОЙ И ТОЙ ЖЕ базы
2) Клиент подключается к ЛЮБОМУ экземпляру и может менять ЛЮБЫЕ данные
То есть мультиматер-кластер.
В нашем случае вообще никаких кластеров нет. Мы просто в рамках одного процесса обращаемся к двум сервисам на двух разных серверах. Операция может завершиться успешно если обе операции завершатся успешно.
Каждая из этих баз может представлять из себя мкльтимастер-кластер, а может одни сервер, а может шардированную базу, это не имеет значения.
G>>·>"резервирование сделаем транзакционно" не решает проблему "пользователь плюет". G>>Конечно решает, потому что пользователь после резервации на складе точно получит свой заказ. S>В нашем случае пользователь после резервации на складе тоже точно получит свой заказ. Вся разница — в том, что если будет сбой системы во время заказа, то пользователь монолита до окончания сбоя будет получать 502, а пользователь МСА имеет шанс в это время увидеть спиннер "заказ резервируется....".
Это вопрос реализации фронта. Мы при любой архитектуре можем вынести повтор именно на фронт.
S>В любом случае результат резервирования станет известен только по окончанию сбоя — и точно так же, как в монолитном случае можно получить как подтверждение успеха, так и "извините, но другой покупатель успел зарезервировать товар до вас".
Тогда вопрос — если не видно разницы, то зачем платить больше?
Я скинул ссылку на статью выше, там рукопашные транзакции почти в два раза уронили производительность.
G>>·>Для этого не требуется обновлять корзину и склад в одной транзакции. G>>Я уже выше описал почему требуется. Не повторяй эту глупость уже S>При всём уважении — это не глупость, а вполне себе математическая реальность. Я выше написал, как именно это работает.
Дьявол как всегда в деталях.
G>>Лол, а зачем? S>Затем, что в реальном приложении — сотни бизнес-сценариев.
Я предлагаю на одном сконцентрироваться. Это же реальный сценарий.
Когда с ним закончим сможем посмотреть как эти подходы масштабировать.
S>Остановка на техобслуживание одного из сервисов задержит только те сценарии, которые проходят через него.
Мы же рассматриваем сценарий когда у нас сценарий зависит от доступности двух серверов. На одно из них, а сразу двух. Их доступность равна произведению доступности обоих. А она будет меньше, чем доступность одного.
S>И если этот сервис достаточно простой и маленький, то его рестарт не будет занимать десятки минут. Таким образом, perceived availability может оказаться значительно выше, чем у монолита. Ну вот, абстрактно, мы на пять минут отключили банковское ядро, которое собственно проводит платежи. Если всё сделано по уму, то пользователи это увидят только как "странно, я вроде по СБП деньги отправил, а у получателя телефон что-то не вибрирует". Если чуть хуже — то как "переводы пока недоступны, приходите позже". Если ещё хуже — то как "Непредвиденная ошибка. Перезапустите приложение или зайдите позже". И в любом из этих случаев люди, которые смотрят какую-нибудь там аналитику расходов, или остатки по вкладам, или условия кредитов/страховок/етк не заметят вообще ничего. С их точки зрения никакого сбоя не было. А если нам нужно сделать то же самое в монолите, то опускать нужно примерно всё, и всё будет лежать сразу у всех пользователей.
Мы о чем говорим? О серверах приложений или о субд? СУБД в продах стоят в HA кластерах и спокойно выдерживают остановку одного из серверов. От силы 15-20 сек ожидания переезда мастера если сервак упал неожиданно.
Приложения можно нарезать на десятки отдельных модулей и запускать отдельно: в отдельных процессах, в модулях одного процесса — как удобно. Все что написано выше для них верно.
Re[28]: Помогите правильно спроектировать микросервисное при
Здравствуйте, gandjustas, Вы писали:
G>Чтобы говорить об одном и том же давай зафиксируем детали о которых шла речь: G>- Я предлагаю состояние заказа менять в одной транзакции с обновлением остатков. Заказы и остатки естественно должны быть в одной базе G>- МСА предлагает сделать две базы, где заказы лежат в одной, а заказы в другой. G>Написать код вида: G> 1. обнови остатки в базе А G> 2. обнови статус заказа в базе Б G> 3. если появилась ошибка, то откати обновление в базе А
G>Если код падает по между шагами 2 и 3, то в базе остается несогласованное состояние. G>Значит вместе самим кодом резервирования заказа надо написать еще фоновую задачу, которая откатывает незавершенные резервы.
Ты упускаешь мою мысль, что этот код — не особенность МСА-реализации, а реальность бизнес-задачи. Просто в твоём монолитном решении ты игнорируешь эту проблему. С точки зрения бизнеса _изначальная_ задача выглядит так:
1. Пользователь создаёт заказ
2. Склад резервирует заказ
3. Пользователь завершает заказ
И вот когда ты опишешь задачу так, то совершенно ВНЕЗАПНО получается, что "надо написать еще фоновую задачу, которая откатывает незавершенные резервы" в любом случае, неважно — МСА у тебя или монолит.
МСА просто это сделал явным.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай