Здравствуйте, gandjustas, Вы писали:
G>Сохранишь копию order в то же базе в той же тразакции, да?
Техническое решение этой задачи для микросервисов уже обсуждалось. Да, оно в каком-то смысле "хуже", чем единая ACID-транзакция — у заказа появляется некое промежуточное состояние, которого не было в исходной реализации.
Но давайте прекратим делать вид, что этого решения нет, т.к. это состояние — эфемерное, и фактически время его жизни равно времени даунтайма сервиса склада с точки зрения сервиса корзинки.
G>Ты наверное начнешь разговор что так делать не надо. Но озону надо. Потому что разница limit-reserverd отображается в интерфейсе приложения как "сколько осталось" и это отображается прямо в результатах поиска, то есть надо быстро получать это число для любого количества товаров.
Микросервисы никак не мешают быстрому показу remaining — скорее наоборот, т.к. RDBMS склада вообще не обрабатывает никакой нагрузки, кроме вот этого вот get remaining и reserve stock / unreserve stock / top-up stock.
Кроме того, её можно шардить — т.к. сами товары друг на друга никак не завязаны, можно держать первые 10000 позиций в одном сервере, вторые 10000 — в другом, и так далее.
Не, я в курсе, что как только мы начнём джойнить эту информацию с какими-нибудь запросами по другой части домена (типа "робот-пылесос в пределах 20000 рублей с доставкой до послезавтра и средним баллом по отзывам не ниже 4.9"), то МСА со страшной силой сольёт монолиту. Вот только если мы
всё же уперлись в потолок монолита, то возможность получить 2х перформанс ценой распиливания его на 8х частей может оказаться единственным выбором.
G>Не лучше, чем в одной базе. Прям строго математически не лучше.
Да, но с учётом нюансов, указанных выше. Пока мы не упёрлись в пределы монолита и при отсутствии административных причин, монолит будет строго математически лучше.
G>>>Более того, возможен сценарий когда первая выполнилась, а вторая отвалилась, просто по таймауту. Тогда товар на складе забронирован, а статус корзины не поменялся. Нужно писать код для отката.
G>·>Это эквивалентно ситуации: клиент наполнил корзину и ушел плюнув, потому что левая пятка зачесалась. Код отката брони на складе ты будешь писать в любом случае.
G>Не эквивалентно и не придется такое писать. Это твои фантазии
Нет, откат писать не надо. Надо писать "накат". И это можно сделать один раз в инфраструктуре worflow-engine. Типа вот мы поднялись после сбоя и видим, что корзинка №42342342 была отправлена на резервирование, а результата резервирования нет. Значит, либо мы в прошлый раз не достучались до сервера (получили сonnection timeout), либо достучались да он упал до начала резервирования (отдал нам 5хх), либо упал после окончания резервирования (и отдал нам 5хх или connection reset by peer), либо всё нам отдал, да мы расплескали по пути и упали до коммита в локальную БД.
Во всех случаях мы тупо идём и повторяем резерв. При необходимости — сколько угодно раз, пока нам таки не удастся записать к себе "успех" либо "фейл". На практике, длинные даунтаймы тут бывают не чаще, чем даунтаймы у монолита. Только у монолита лежит вообще всё, а у МСА можно хотя бы в корзинку что-то складывать да отзывы читать.
G>То ест мало того, что для обработки отмены ты вынужден будешь сохранить почти весь order в в той же транзакции, что и обновление остатков, так еще и дополнишь его полем ключа идемпотентности 
Да, объекты, пересекающие границы сервисов, в МСА должны храниться на обеих сторонах. Это не обязательно одни и те же объекты, но у них должна быть общая проекция. В данном случае сторону склада не интересуют никакие подробности про способы доставки товара, розничные цены, или там демографию покупателя, но вот список артикулов и количеств, снабжённый уникальным ID, ей необходим. Ровно для того, чтобы когда к нему в следующий раз стукнутся с просьбой зарезервировать корзинку №42342342 он мог не делать повторный резерв, а сразу отдать 200 ok.
G>·>Теория простая: CAP-теорема.
G>Пока ты пишешь на один сервер тебя cap вообще не интересует.
Совершенно верно.
G>Только оно не рабоает.
Это слишком сильное утверждение в рамках данной дискуссии

G>Но когда мы рассматриваем stateful (а база данных это statful сервис), то при нескольких экземплярах мы наталкиваемся на CAP ограничения — мы можем или терять консистентность (что запрещено по условиям задачи) или доступность. Причем потерю доступности можно посчитать. Доступность системы из двух stateful узлов равна произведению доступности серверов, которая меньше доступности одного сервера. Априори считаем все серверы имеют одинаковую доступность.
Зато доступность строго согласованной системы из трёх stateful узлов уже выше, одного узла — при условии, что надёжность связей между ними выше определённого предела

CAP-теорема как раз и намекает на то, что если каналы не 100% надёжны (P), то получить 100% доступность невозможно даже для 100% надёжных узлов. Но этот тривиальный факт никак не помогает инженерному дизайну — потому что как вы будете поднимать доступность вашего единственного узла за пределы его нормативных способностей?
Вот картинка для доступности строго согласованного кластера из трёх узлов с доступностью A
node, связанных каналами с доступностью A
link:
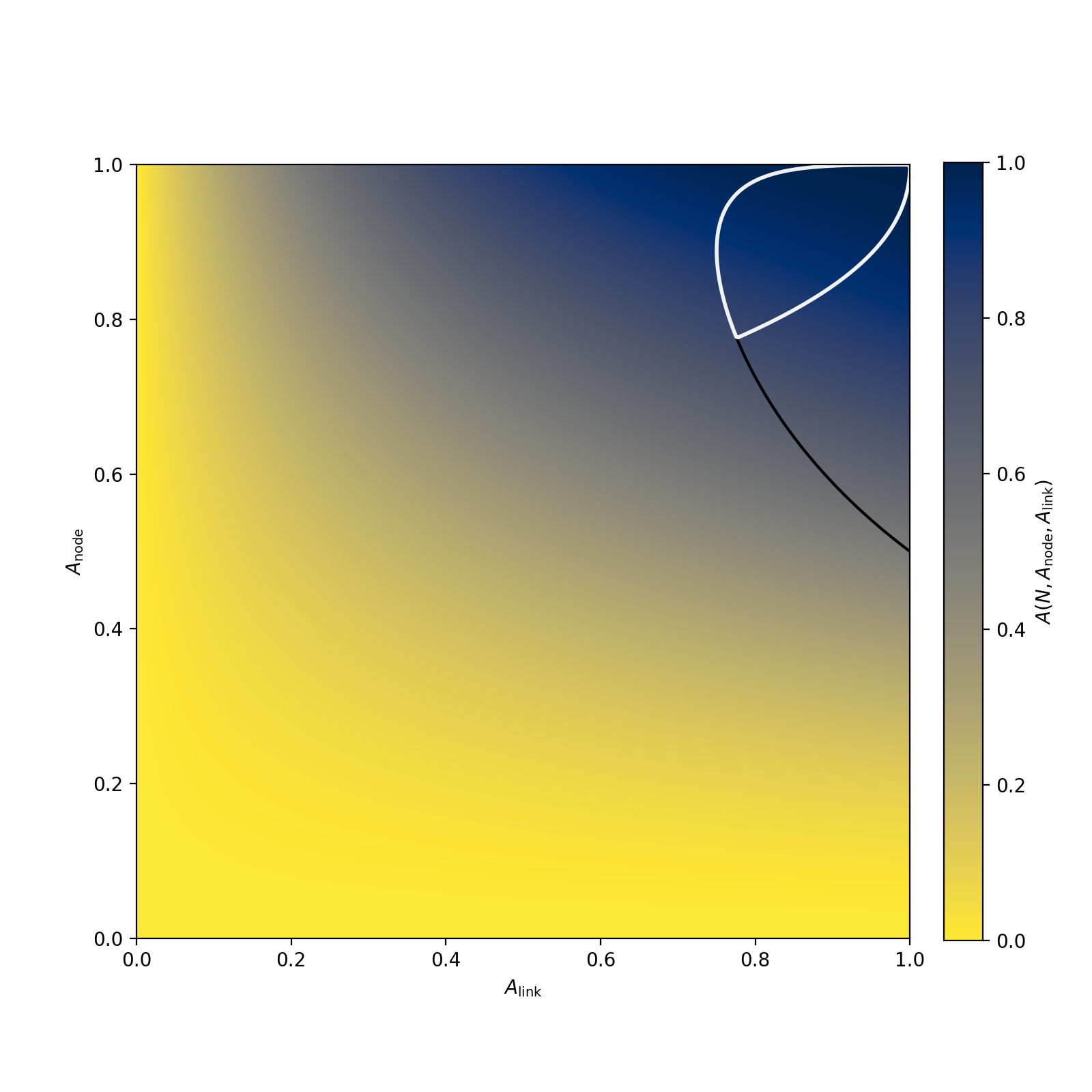
Белый контур — это зона, где эта доступность выше доступности каждого из компонентов.
G>·>"резервирование сделаем транзакционно" не решает проблему "пользователь плюет".
G>Конечно решает, потому что пользователь после резервации на складе точно получит свой заказ.
В нашем случае пользователь после резервации на складе тоже точно получит свой заказ. Вся разница — в том, что если будет сбой системы во время заказа, то пользователь монолита до окончания сбоя будет получать 502, а пользователь МСА имеет шанс в это время увидеть спиннер "заказ резервируется....".
В любом случае результат резервирования станет известен только по окончанию сбоя — и точно так же, как в монолитном случае можно получить как подтверждение успеха, так и "извините, но другой покупатель успел зарезервировать товар до вас".
G>·>Для этого не требуется обновлять корзину и склад в одной транзакции.
G>Я уже выше описал почему требуется. Не повторяй эту глупость уже
При всём уважении — это не глупость, а вполне себе математическая реальность. Я выше написал, как именно это работает.
G>Лол, а зачем?
Затем, что в реальном приложении — сотни бизнес-сценариев. Остановка на техобслуживание одного из сервисов
задержит только те сценарии, которые проходят через него. И если этот сервис достаточно простой и маленький, то его рестарт не будет занимать десятки минут. Таким образом, perceived availability может оказаться значительно выше, чем у монолита. Ну вот, абстрактно, мы на пять минут отключили банковское ядро, которое собственно проводит платежи. Если всё сделано по уму, то пользователи это увидят только как "странно, я вроде по СБП деньги отправил, а у получателя телефон что-то не вибрирует". Если чуть хуже — то как "переводы пока недоступны, приходите позже". Если ещё хуже — то как "Непредвиденная ошибка. Перезапустите приложение или зайдите позже". И в любом из этих случаев люди, которые смотрят какую-нибудь там аналитику расходов, или остатки по вкладам, или условия кредитов/страховок/етк не заметят вообще ничего. С их точки зрения никакого сбоя не было. А если нам нужно сделать то же самое в монолите, то опускать нужно примерно всё, и всё будет лежать сразу у всех пользователей.
Не факт, что это прямо плохо. Не факт, что это прямо настолько плохо, что стоит многократного роста вычислительной и когнитивной нагрузки, сопровождающего переход от монолита к (микро)-сервисам. Но для полноты картины имеет смысл рассматривать и такие сценарии, не пытаясь искусственно обесценить такие требования или там сочинять недостатки модели, которых в реальности нет.


