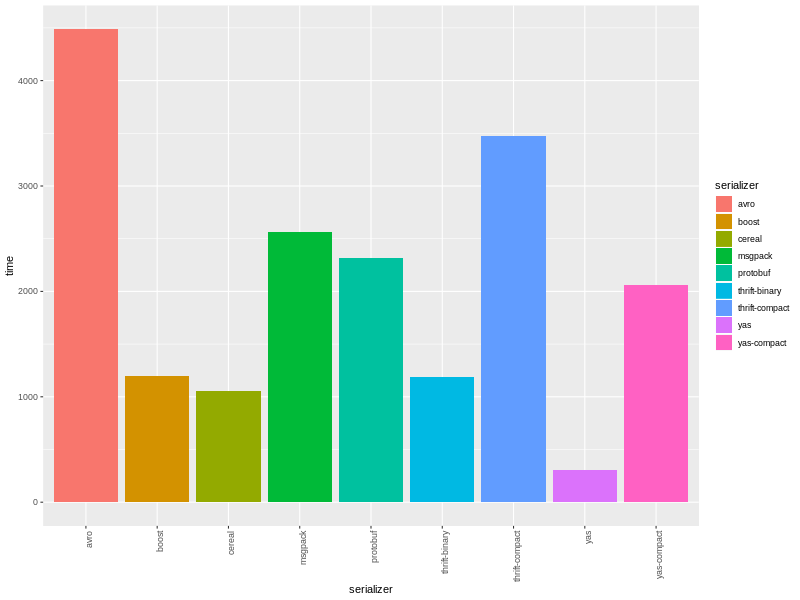
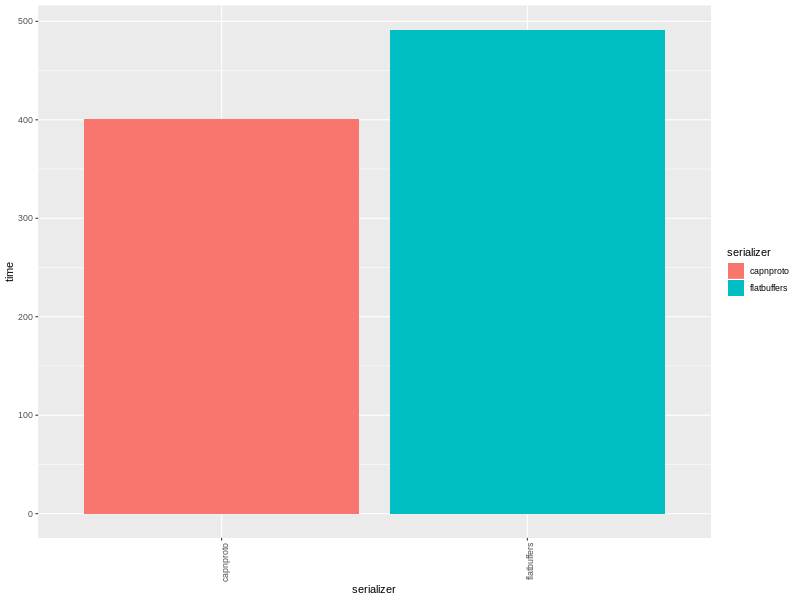
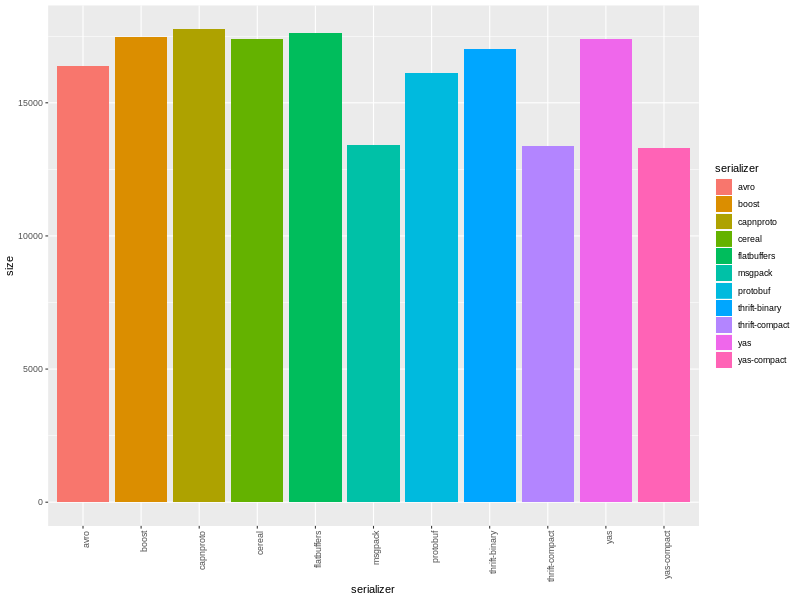
еще одна библиотека сериализации для С++. проживает тут.
YAS был создан как замена boost.serialization из-за непозволительно низкой скорости сериализации.
бинарная сериализация YAS в 3-8 раз быстрее.
текстовая сериализация YAS в 2-3 раза быстрее.
в планах — реализация JSON(сделано) и BSON.
YAS является 'header only' библиотекой. YAS не зависит от сторонних библиотек или от boost.
YAS предоставляет сериализацию как в/из буфер, так и в/из файл.
YAS может использоваться как на 32ух, так и на 64ех битной архитектурах. при этом, архивы сериализации полностью переносимы в обоих направлениях.
YAS требует от компилятора поддержки C++11.
задачи, планируемые к выполнению, располагаются в следующем порядке, в порядке убывания:
1. дореализовать тест переносимости архивов сериализации между 32 и 64-бит архивами.
2. реализовать тест совместимости YAS и boost.serialization.
3. добавление поддержки rvalue-refs & move-semantics.
4. переход на использование ADL вместо SFINAE.
5. реализовать возможность назначить используемый фильтр.
6. реализовать сжатие архивов "налету".
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
X>еще одна библиотека сериализации для С++. проживает тут.
X>YAS был создан как замена boost.serialization из-за непозволительно
1. IO был отделен от архивов.
теперь у пользователей есть возможность реализовать/использовать свои собственные istream/ostream классы.
для istream классов требованием является наличие метода 'std::size_t read(void *ptr, std::size_t size)'
для ostream классов — 'std::size_t write(const void *ptr, std::size_t size)'
эта возможность была реализована для того, чтоб пользователи могли реализовать максимально эффективные стратегии, такие как запись в сокет или в 'interprocess memory' без использования промежуточных буферов/копирования.
2. бинарные архивы по умолчанию 'endian independent'. это означает, что сериализовав данные в бинарный архив на x86-хосте, вы сможете десериализовать его на таких архитектурах как SPARC/PowerPC/ARM.
3. увеличена скорость сериализации/десериализации:
Binary serialization:
+-------------------+
| boost | YAS |
+------+---------+---------+---------+
| save | 142 ms | 24 ms | +500% |
+------+---------+---------+---------+
| load | 114 ms | 8 ms | +1300% |
+------------------------------------+
Text serialization:
+-------------------+
| boost | YAS |
+------+---------+---------+---------+
| save | 8090 ms | 277 ms | +28000% |
+------+---------+---------+---------+
| load | 8794 ms | 265 ms | +33000% |
+------------------------------------+
4. для текстовой сериализации были использованы сторонние конверторы integer->string/string->integer.
на данный момент, эти конверторы "прибиты гвоздями". это будет исправлено в течении нескольких дней, и после этого пользователи сами смогут указывать желаемые конверторы следующим образом:
Здравствуйте, niXman, Вы писали:
X>4. для текстовой сериализации были использованы сторонние конверторы integer->string/string->integer. X>на данный момент, эти конверторы "прибиты гвоздями". это будет исправлено в течении нескольких дней
done!
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
из серьезных изменений было сделано:
1. для текстовых архивов был переработан формат, что позволило наполовину уменьшить кол-во обращений к источнику/приемнику данных.
т.е. если в качестве источника/приемника данных используется файл, то кол-во операций чтения/записи(read()/write()) уменьшено вдвое.
2. YAS был добавлен в сравнителный тест сериализаторов/десериализаторов.
(первый коммит добавляющий YAS к этому тесту приняли, а второй, где я переработал отчеты — пока в ожидании. уикенды, мля)
зы
YAS все так же используется в игровых проектах, сериализуя/десериализуя пользовательский трафик, и трафик меж нод игровых серверов, так же для самопальной logfs, которую я закодил для хранения/сбора/обработки логов.
так же, возможно до конца года выкачу свою поделку, систему распределенного бэкапинга и синхронизации, с одной крайне необычной плюшкой. вам понравится
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
1) большие (а в наше время не особо большие) данные молча криво обрабатываются?
2) &string[0] — это реально стремно
3) надлежащие инклюды для std::uint32_t и других простых стандартных типов отсутствуют
4) С-style cast
ЗЫ не стоит прописывать в решениях полные пути типа D:\msys\home\niXman\
Говорить дальше не было нужды. Как и все космонавты, капитан Нортон не испытывал особого доверия к явлениям, внешне слишком заманчивым.
VTT>Студия 2015: 77 предупреждений VTT>mingw (g++ 5.1): 356 предупреждений VTT>clang 3.9: 345 предупреждений
приведите лог хоть какого-то из компиляторов. и команду сборки. спасибо.
VTT>1) большие (а в наше время не особо большие) данные молча криво обрабатываются?
не поняд...
VTT>2) &string[0] — это реально стремно
иначе придется константность снимать с c_str(). какие еще варианты?
VTT>3) надлежащие инклюды для std::uint32_t и других простых стандартных типов отсутствуют
исправлю.
VTT>4) С-style cast
да, некрасиво, согласен. исправлю.
VTT>ЗЫ не стоит прописывать в решениях полные пути типа D:\msys\home\niXman\
а где ты нашел это?
спасибо!
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
VTT>1) большие (а в наше время не особо большие) данные молча криво обрабатываются?
всегда использовать для этого uint64 — расточительно, как мне кажется...
возможно, перед size_type`ом записывать и необходимый размер удовлетворяющего size_type`а... т.е. sizeof(uint8)|sizeof(uint16)|sizeof(uint32)|sizeof(uint64)...
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
VTT>>1) большие (а в наше время не особо большие) данные молча криво обрабатываются? X>всегда использовать для этого uint64 — расточительно, как мне кажется... X>возможно, перед size_type`ом записывать и необходимый размер удовлетворяющего size_type`а... т.е. sizeof(uint8)|sizeof(uint16)|sizeof(uint32)|sizeof(uint64)...
Для сериализации длины чего-либо часто используется простейшее кодирование значения называемое varint.
Не мой комментарий, но я помню, что тоже обратил внимание на эти моменты, когда смотрел в код.
VTT>>1) большие (а в наше время не особо большие) данные молча криво обрабатываются? X>не поняд...
Значения типа `size_t` (который может быть `uint64_t`) обрезаются до `uint32_t`
Если 8 байт для хранения нулевой дины кажется расточительным, надо смотреть на кодирование значения переменной длиной. Но есть шанс переместиться со 2-го места в середину списка в замерах скорости, к тем библиотекам, которые это уже делают.
Вообще тема длины строк и количества элементов в сериализуемых контейнерах в YAS не раскрыта. Как реагировать на строку длиной, например, 2^63?
VTT>>2) &string[0] — это реально стремно X>иначе придется константность снимать с c_str(). какие еще варианты?
Для string::data() в С++17 есть неконстантная перегрузка. Хорошо бы добавить защиту от пустых строк:
Сейчас, конечно, всё работает и так, потому что устройство строки во всех 3-х стандартных библиотеках более-менее одинаково. Но кто знает, как оно будет в будущем.
Здравствуйте, PM, Вы писали:
PM>Для сериализации длины чего-либо часто используется простейшее кодирование значения называемое varint.
я когда-то раньше уже думал об этом, был повод...
Здравствуйте, PM, Вы писали:
PM>Значения типа `size_t` (который может быть `uint64_t`) обрезаются до `uint32_t`
я помню, что это было сделано осознано, так как у нас в проекте просто не может быть таких размеров строк/контейнеров.
и да, по-хорошему — нужно исправить.
PM>Если 8 байт для хранения нулевой дины кажется расточительным, надо смотреть на кодирование значения переменной длиной. Но есть шанс переместиться со 2-го места в середину списка в замерах скорости, к тем библиотекам, которые это уже делают.
сейчас сделаю и отпишусь о замерах...
PM>Вообще тема длины строк и количества элементов в сериализуемых контейнерах в YAS не раскрыта. Как реагировать на строку длиной, например, 2^63?
та понятно =)
PM>Сейчас, конечно, всё работает и так, потому что устройство строки во всех 3-х стандартных библиотеках более-менее одинаково. Но кто знает, как оно будет в будущем.
угу.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
VTT>>1) большие (а в наше время не особо большие) данные молча криво обрабатываются? X>не поняд...
ar.write((std::uint32_t)string.length());// допустим длина 4Гб 16 Б, верхние байты будут отброшены, длина будет записана 16 Б
ar.write(&string[0], string.length()); // а тут запишутся все 4Гб 16 Б, при чтении из них будет прочитано только 16 Б, а остальные интерпретированы как продолжение архива
VTT>>2) &string[0] — это реально стремно X>иначе придется константность снимать с c_str(). какие еще варианты?
когда строчка сохраняется — можно спокойно использовать data() const
ну а при использовании более старых — придется задействовать промежуточный буффер.
Конечно желание избежать такого бесполезного транжирства понятно, да и текущий код вроде как работает, но тем не менее...
Как минимум, не стоит дергать эти методы, когда строка пустая.
VTT>>ЗЫ не стоит прописывать в решениях полные пути типа D:\msys\home\niXman\ X>а где ты нашел это?
В студийных проектах инклюды.
Говорить дальше не было нужды. Как и все космонавты, капитан Нортон не испытывал особого доверия к явлениям, внешне слишком заманчивым.
Здравствуйте, PM, Вы писали:
PM>Для сериализации длины чего-либо часто используется простейшее кодирование значения называемое varint.
думаю, сделать выбор способа хранения целых путем условной компиляции. по умолчанию пусть используется uint64, а если нужна компактность — включаем.
варианты?
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
VTT>ну а при использовании более старых — придется задействовать промежуточный буффер. VTT>Конечно желание избежать такого бесполезного транжирства понятно, да и текущий код вроде как работает, но тем не менее... VTT>Как минимум, не стоит дергать эти методы, когда строка пустая.
тогда, наверное, лучше использовать 'data()' и при необходимости 'const_cast()' %)
VTT>В студийных проектах инклюды.
аа, возможно... я эти проекты уже наверное несколько лет не трогал %)
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, VTT, Вы писали: VTT>лог mingw
вот не понимаю, как мне победить этот ворнинг?:
../../include/yas/detail/io/information.hpp:69:13: warning: conversion to 'unsigned char:3' from 'uint8_t {aka unsigned char}' may alter its value [-Wconversion]
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
PM>>Для сериализации длины чего-либо часто используется простейшее кодирование значения называемое varint. X>думаю, сделать выбор способа хранения целых путем условной компиляции. по умолчанию пусть используется uint64, а если нужна компактность — включаем. X>варианты?
Они всегда есть
Вариант 2: добавить параметр LengthType = size_t в шаблон binary_[i|o]archive. Добавить в библиотеку тип varint, которые можно было бы использовать в качестве LengthType.
Вариант 3: перенести это в рантайм. Емнип, у тебя же в заголовке бинарного архива есть archive_header, там можно хранить флаг компактности. И можно использовать uint32 если установлен флаг 32-битности в этом заголовке.
Здравствуйте, niXman, Вы писали:
X>Здравствуйте, VTT, Вы писали: VTT>>лог mingw X>вот не понимаю, как мне победить этот ворнинг?: X>
X>../../include/yas/detail/io/information.hpp:69:13: warning: conversion to 'unsigned char:3' from 'uint8_t {aka unsigned char}' may alter its value [-Wconversion]
Здравствуйте, PM, Вы писали:
PM>Вариант 2: добавить параметр LengthType = size_t в шаблон binary_[i|o]archive. Добавить в библиотеку тип varint, которые можно было бы использовать в качестве LengthType.
тоже вариант.
PM>Вариант 3: перенести это в рантайм. Емнип, у тебя же в заголовке бинарного архива есть archive_header, там можно хранить флаг компактности. И можно использовать uint32 если установлен флаг 32-битности в этом заголовке.
этот вариант мне не нравится
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
PM>>Для сериализации длины чего-либо часто используется простейшее кодирование значения называемое varint. X>думаю, сделать выбор способа хранения целых путем условной компиляции. по умолчанию пусть используется uint64, а если нужна компактность — включаем. X>варианты?
Я бы всегда использовал кодирование переменной длины, во первых, это сделает архив компактнее, т.к. обычно стоки бывают короткими и длина строки поместится в первые два-три байта, во вторых, я бы в принципе не стал пользоваться сериализатором, который не умеет сжимать данные на лету. Логика тут такая, если ты пишешь систему массового обслуживания (игровой сервер например), то чтобы жать трафик на лету, например, через LZ4, нужно создать по отдельному контексту на каждое клиентское подключение. Контекст в LZ4 это 12КБ. Для многих серверных приложений это превышает объем данных, необходимых для обслуживания одного клиентского подключения в разы. В общем, в итоге, ты либо расточительно расходуешь сетевой трафик, либо память на сервере. Большинство сериализаторов (protobuf, thrift, cap'n proto) умеют немного сжимать данные именно по этой причине. В protobuf оно включено всегда, а в cap'n proto — выключается при желании, ну это так, в качетсве примера.
зы
Вообще, пользоваться библиотекой сериализации, автор которой впервые узнал про leb128 в этом топике, немного не ок. Этой кодировке 100 лет в обед, она в DWARF в линуксе используется, например. Я думал что все про нее знают.
Здравствуйте, VTT, Вы писали:
VTT>>>Студия 2015: 77 предупреждений
Вот эти вот 4456-4459 (declaration of 'X' hides previous declaration, class member, global declaration) ужасно неудобны, хотя я обычно за -Wall в проектах.
Есть ли где рациональное объяснение этих нововведений? Всю жизнь инициализация членов класса работала корректно, а теперь вдруг стало опасным:
class Type {
int member;
std::string string;
public:
Type(int member, std::string const& string)
: member(member) // declaration of 'X' hides class member declaration
, string(string)
{}
};
Здравствуйте, chaotic-kotik, Вы писали:
CK>... во вторых, я бы в принципе не стал пользоваться сериализатором, который не умеет сжимать данные на лету.
сериализатор этого делать не должен, для этого юзеру предоставлена возможность реализовать свой io-device, типа этого.
CK>Вообще, пользоваться библиотекой сериализации, автор которой впервые узнал про leb128 в этом топике, немного не ок. Этой кодировке 100 лет в обед, она в DWARF в линуксе используется, например. Я думал что все про нее знают.
я тоже думал, что все знают, что разможаться нынче нельзя потому что планета и так перенаселена, и что успешные женьщины не размножаются сразбегу не потому, что детей не хотят/не любят, а потому что они самореализовались, и их занятия доставляют им гораздо большее удовольствие, ежели роль матки с багажем(особено глядя на подруг, которые всю свою жизнь пустили "под откос" по зову природы и благодаря отсутствию родителей в формировании личности дитя)...
оказывается нет, одна часть ничего из этого не знает, а другая — брызжет слюной рассказывая, какие они матери героини, и какую они важную роль играют(ага, в выработке углекислого газа), и как все это сложно, и рожать, и мужа алкаша терпеть чтоб дите не осталось без "отца", и дите при таком "отце" воспитать, и деньги зарабатывать для того, что на это самое дите и потратить, и чтоб "муж" еще часть из этих денег пропил...
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
X>сериализатор этого делать не должен, для этого юзеру предоставлена возможность реализовать свой io-device, типа этого.
Туда можно только snappy или lz4 впилить. То о чем я говорю делается на уровне энкодера.
X>я тоже думал, что все знают, что разможаться нынче нельзя потому что планета и так перенаселена, и что успешные женьщины не размножаются сразбегу не потому, что детей не хотят/не любят, а потому что они самореализовались, и их занятия доставляют им гораздо большее удовольствие, ежели роль матки с багажем(особено глядя на подруг, которые всю свою жизнь пустили "под откос" по зову природы и благодаря отсутствию родителей в формировании личности дитя)... X>оказывается нет, одна часть ничего из этого не знает, а другая — брызжет слюной рассказывая, какие они матери героини, и какую они важную роль играют(ага, в выработке углекислого газа), и как все это сложно, и рожать, и мужа алкаша терпеть чтоб дите не осталось без "отца", и дите при таком "отце" воспитать, и деньги зарабатывать для того, что на это самое дите и потратить, и чтоб "муж" еще часть из этих денег пропил...
тут должна быть картинка с летчиком и подписью "я ничего не понял"
Здравствуйте, chaotic-kotik, Вы писали:
CK>тут должна быть картинка с летчиком и подписью "я ничего не понял"
если сильно упростить, — то я тоже думал, что все умеют читать.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
F>class Type {
F> int member;
F> std::string string;
F>public:
F> Type(int member, std::string const& string)
F> : member(member) // declaration of 'X' hides class member declaration
F> , string(string)
F> {}
F>};
F>
А вот меня приводит в недоумение, отчего в языке разрешается использовать одно и то же имя для всего подряд.
По возможности, я использую строго непересекающиеся наименования для пространств имен, макросов, типов, методов, полей, статических полей и переменных.
Чтоб потом не приходилось гадать, string — это поле, переменная, тип или еще что.
Говорить дальше не было нужды. Как и все космонавты, капитан Нортон не испытывал особого доверия к явлениям, внешне слишком заманчивым.
Здравствуйте, niXman, Вы писали:
X>2. YAS был добавлен в сравнителный тест сериализаторов/десериализаторов. X> (первый коммит добавляющий YAS к этому тесту приняли, а второй, где я переработал отчеты — пока в ожидании. уикенды, мля)
привет!
нужна ваша помощь.
как вы можете прочитать тут, коллега мне намекает, будто бы я исказил результаты тестов, и типа у него совсем другие результаты. я повторил тесты на двух машинах — мои результаты повторяются.
просьба заключается в том, чтоб выполнить тесты на своей машине, и отписаться в этот же PR, приложив скрин с результатами.
сейчас проделано следующее:
1. почищен код, пофикшены ворнинги, убраны олд-стайл-касты и всякая фигня вроде '&str[0]'.
2. выброшена изрядная часть кода.
3. добавлены лимиты.
4. повышена производительность.
5. добавлен компактный(без использования varint) тип бинарных архивов(зовется yas_compact). (гораздо более быстрый, чем при использовании varint, но экономия в размере ниже)
6. в процессе реализация компактных архивов с использованием varint. (гораздо более медленный чем yas_compact, но экономия в размере выше)
7. добавлен новый тип архивов — object. это почти как json, но намного производительнее, и с некоторыми отличиями от json.
пример создания сложного, вложенного объекта:
int v0=33;
bool v1=false;
double v2=3.14;
bool v3=true;
int v4=44;
int v5=55;
auto o0 = YAS_OBJECT("object-0", v0, v1, v2);
auto o1 = YAS_OBJECT("object-1", v3, v4, o0, v5);
auto o2 = YAS_OBJECT("object-2", 5, 6, o1, true);
auto o3 = YAS_OBJECT("object-3", 1, 2, o2, 3, 4, false);
yas::mem_ostream os;
yas::json_oarchive<yas::mem_ostream> oa(os);
oa & o3;
этот тип архива будет зваться yas_object.
от json отличается тем, что верхний уровень всегда объект, т.е. {}. верхний уровень не может быть массивом или значением.
скорость сериализации во много раз выше.
более подробно расскажу позже.
это подготовка к json архивам в составе YAS.
все это пока что у меня локально. недели через две вылью в паблик.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
YAS_OBJECT() — макрос. первый аргумент не используется для yas_object архивов, но будет использоваться для json архивов.
и да, YAS_OBJECT() можно использовать с бинарными и текстовыми архивами. архивы, при этом, абсолютно идентичны как и без использования YAS_OBJECT().
и вообще, предпочтительней использовать YAS_OBJECT() всегда потому, что можно запрсто сменить тип архива, не изменяя сериализаторы.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, greenpci, Вы писали:
VTT>>2) &string[0] — это реально стремно G>Я как-то тоже поставил коллеге ошибку в ревью из-за этого. Потом, когда читал Страуструпа, нашел примеры, где он это бессовестно делал.
А что в этом стремного, если у тебя C++11 и выше? Если 03, то все понятно – так делать не стоит, во избежание.
Здравствуйте, kaa.python, Вы писали:
KP>А что в этом стремного, если у тебя C++11 и выше? Если 03, то все понятно – так делать не стоит, во избежание.
та нет тут ничего стремного.
расстраивало лишь то, что AddressSanitizer ругался. но формально тут все безопасно, т.к. если string.size() == 0, то по факту мы не читаем данные из пустой строки.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
X>расстраивало лишь то, что AddressSanitizer ругался. но формально тут все безопасно, т.к. если string.size() == 0, то по факту мы не читаем данные из пустой строки.
мне тоже кажется, что стремного ничего нет. Не было у строки data(), как у вектора, вот и проходилось так делать. Альтернатива была одна, использовать vector<char>, но это тоже не идеально.
одно значительное изменение в том, что далее предпочтительно сериализовать не используя такую запись:
yas::binary_oarchive<> oa(...);
oa & var0
& var1
& var2
;
но такую:
yas::binary_oarchive<> oa(...);
oa & YAS_OBJECT("object", var0, var1, var2);
// либо так, если имена переменных не совпадают(не должны совпадать) с именами ключей в архиве
oa & YAS_OBJECT_NVP(
"object"
,("v0", var0)
,("v1", var1)
,("v2", var2)
);
ну и как "плюшка", добавил простой способ сериализации/десериализации. (т.е. функции yas::save() и yas::load())
примеры тут.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, so5team, Вы писали:
S>Да в любом, в каком вам удобнее.
какой тип архива вас интересует в первую очередь?
и, позвольте несколько почти офтопных вопроса:
1. вы собираетесь писать сериализатор/десериализатор для других ЯП?
2. и, если не секрет, в каких проектах вы используете YAS?
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
S>>Да в любом, в каком вам удобнее. X>какой тип архива вас интересует в первую очередь?
Я так понял, что у вас есть два бинарных формата: компактный и не очень. Вот эти и интересуют.
X>1. вы собираетесь писать сериализатор/десериализатор для других ЯП?
Нет. Но для того, чтобы брать чей-то готовый сериализатор, хочется понимать, что у него внутри. Может он by design пригоден только для каких-то ограниченных сфер применения и некоторые важные фичи (вроде точек расширения/версионирования, поддержки опциональности и пр.) там отсутствуют как класс.
X>2. и, если не секрет, в каких проектах вы используете YAS?
Пока ни в каких. Но результаты бенчмарков заинтересовали, да.
в локальной версии есть еще одна оптимизация размера для compacted архивов, которая снова сломает совместимость, посему будет выпущена еще и шестая версия YAS.
далее, думаю сменить имя проекта, на что-то более серьезное и выпуститься под версией 0.1.
есть предложения по названию?
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, so5team, Вы писали:
S>Я так понял, что у вас есть два бинарных формата: компактный и не очень. Вот эти и интересуют.
ок, займусь на выходных.
S>Нет. Но для того, чтобы брать чей-то готовый сериализатор, хочется понимать, что у него внутри. Может он by design пригоден только для каких-то ограниченных сфер применения и некоторые важные фичи (вроде точек расширения/версионирования, поддержки опциональности и пр.) там отсутствуют как класс.
версионность — в планах.
опциональность — при помощи std::optional/boost::optional
а что такое "точки расширения"?
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
X>версионность — в планах.
Есть подозрение, что поддержка версионности и расширяемости схемы данных негативно скажется на производительности.
X>опциональность — при помощи std::optional/boost::optional
Это не то. Опциональность полей в сериализуемом представлении -- это либо возможность не сохранять поле (если у него, скажем, дефолтное значение), либо возможность отсутствия поля в сериализованном представлении вообще (тогда при десериализации полю подставляется дефолтное значение).
X>а что такое "точки расширения"?
Погуглите ASN.1 Extension Markers. Это специальные пометки в описании схемы данных, которые говорят о том, что в следующих версиях в этих местах возможно расширение схемы. Тема эта непосредственно связана с версионностью.
Здравствуйте, so5team, Вы писали:
S>Есть подозрение, что поддержка версионности и расширяемости схемы данных негативно скажется на производительности.
скорее всего так и будет...
S>Это не то. Опциональность полей в сериализуемом представлении -- это либо возможность не сохранять поле (если у него, скажем, дефолтное значение), либо возможность отсутствия поля в сериализованном представлении вообще (тогда при десериализации полю подставляется дефолтное значение).
при несохранении поля вообще, каким образом противоположная сторона узнает, что это поле может/должно быть/отсутствовать?
и, если на одной стороне какое-то поле удалили/исключили, как другая сторона должна себя вести если она ожидает это поле?
и, подскажите, чем не подходит optional?
S>Погуглите ASN.1 Extension Markers. Это специальные пометки в описании схемы данных, которые говорят о том, что в следующих версиях в этих местах возможно расширение схемы. Тема эта непосредственно связана с версионностью.
как все сложно %)
по поводу версионности я пока не имею конечного решения...
готов выслушать ваши предложения.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
S>>Это не то. Опциональность полей в сериализуемом представлении -- это либо возможность не сохранять поле (если у него, скажем, дефолтное значение), либо возможность отсутствия поля в сериализованном представлении вообще (тогда при десериализации полю подставляется дефолтное значение). X>при несохранении поля вообще, каким образом противоположная сторона узнает, что это поле может/должно быть/отсутствовать? X>и, если на одной стороне какое-то поле удалили/исключили, как другая сторона должна себя вести если она ожидает это поле?
Это зависит...
Например, можно в схеме данных указать, что какое-то поле опциональное. Т.е. его может не быть во входном потоке вообще. В этом случае формат представления (т.е. формат архива) должен поддерживать какой-то способ разметки, который позволяет узнать, есть ли поле или его нет. В случае двоичных форматов это может достигаться разными способами:
если применяется механизм TLV (он же BER из ASN.1), то само отсутствие тега для поля говорит о том, что поля во входящем потоке нет. При записи архива так же все просто -- соответствующий TLV просто не пишется;
если нет TLV, а поля располагаются по порядку (как в PER из ASN.1), то могут использоваться какие-то битовые маски, которые пишутся либо в начале объекта, либо в определенных точках. Либо в самом простом случае каждому опциональному полю может предшествовать байт-маркер (если 0, значит поля нет).
Но это пока речь шла больше об опциональности при чтении из входного потока. Отдельный вопрос -- это поддержка опциональности при записи. Могут быть случаи, когда у объекта N полей, которые практически всегда содержат дефолтные значения. Если эти поля всегда серилизовать, то неэкономно расходуется место, чего хотелось бы избежать. Поэтому интересно иметь возможность задавать предикаты, которые бы подсказывали, нуждается поле в сохранении или нет.
X>и, подскажите, чем не подходит optional?
Потому что это вообще ортогонально наличию значения в двоичном представлении. Optional в программе явно говорит, есть ли значение поля в структуре или нет. Но когда оно есть у него может быть значение, которое не имеет смысла сохранять, т.к. оно дефолтное.
X>по поводу версионности я пока не имею конечного решения... X>готов выслушать ваши предложения.
Почитайте, как устроены двоичные форматы BER и PER из ASN.1. Эти, имхо, подошли к проблеме версионирования наиболее серьезно. В том же google protobuf, afaik, всего лишь вариация на тему BER-а. Еще можно глянуть в сторону MessagePack.
Здравствуйте, so5team, Вы писали:
S>Например, можно в схеме данных указать, что какое-то поле опциональное. Т.е. его может не быть во входном потоке вообще. В этом случае формат представления (т.е. формат архива) должен поддерживать какой-то способ разметки, который позволяет узнать, есть ли поле или его нет. В случае двоичных форматов это может достигаться разными способами: S>
S>если применяется механизм TLV (он же BER из ASN.1), то само отсутствие тега для поля говорит о том, что поля во входящем потоке нет. При записи архива так же все просто -- соответствующий TLV просто не пишется; S>если нет TLV, а поля располагаются по порядку (как в PER из ASN.1), то могут использоваться какие-то битовые маски, которые пишутся либо в начале объекта, либо в определенных точках. Либо в самом простом случае каждому опциональному полю может предшествовать байт-маркер (если 0, значит поля нет). S>
S>Но это пока речь шла больше об опциональности при чтении из входного потока. Отдельный вопрос -- это поддержка опциональности при записи. Могут быть случаи, когда у объекта N полей, которые практически всегда содержат дефолтные значения. Если эти поля всегда серилизовать, то неэкономно расходуется место, чего хотелось бы избежать. Поэтому интересно иметь возможность задавать предикаты, которые бы подсказывали, нуждается поле в сохранении или нет.
нужно подумать...
S>Почитайте, как устроены двоичные форматы BER и PER из ASN.1. Эти, имхо, подошли к проблеме версионирования наиболее серьезно. В том же google protobuf, afaik, всего лишь вариация на тему BER-а. Еще можно глянуть в сторону MessagePack.
ок, почитаю, посмотрю...
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
поддержка JSON таки была реализована. это было невероятно сложно %)
в отличии от большинства JSON парсеров(хотя, наверное, всех), YAS не парсит JSON в рантаймовскую структуру типа ключ-значение с последующим извлечением по имени ключей.
взгляните на этот пример кода:
int a=1;
double b=3.14;
string c="str";
auto obj = YAS_OBJECT(
nullptr
,a
,b
,c
);
тут YAS_OBJECT() — макрос. первый агрумент которого в данный момент не используется, но в будущем планируется использовать его в качестве имени(идентификатора) объекта.
остальные аргументы — переменные, ссылки на которые и хранит obj в тьюпле. так же obj хранит сгенеренную в компайл-тайм, отсортированную в компайл-тайм по ключу, static const мапу типа uint32(hash of key)->uint8(pos in tuple).
и вот, при десериализации JSON, при считывании ключа — считаем хеш ключа, — в мапе, за логарифмическое время находим пару, из пары извлекаем значение(позиция в тьюпле), и контекст десериализатора передаем для десериализации нужного элемента. из этого, как вы могли догадаться, вытекает следующее(что, оказывается, большинство кодеров повергает в ступор): невозможно десериализовать JSON, структура которого неизвестна! (некоторое отступление от темы: с++ — статически типизированный ЯП, для меня, как для с++ кодера, такое "ограничение" кажется закономерным. но за последний месяц при внедрении YAS в качестве JSON сериализатора-десериализатора мне пришлось множеству кодеров(и коллег, в том числе) объяснять, что то, как они привыкли работать с JSON в с++ — не соответствует не только идеологии самого с++, но и идеологии плюсовых кодеров. они же привыкли, при помощи любой из доступных библиотек для работы с JSON, сначала десериализовать весь JSON полностью, и только потом, использую геттеры — забрать только нужное, несмотря на то, что пришлось десериализовать весь JSON, в рантаймовскую структуру, со множеством аллокаций и зверским оверхедом)
если же при десериализации нам приходит ключ который мы не просили — YAS просто скипает все до тех пор, пока JSON-контекст не достигнет слеующего ключа этого же уровня. и да, obj может ссылаться на другие объекты, которые могут ссылаться на другие объекты, етц...
ввиду того, что YAS требует описания стуктуры JSON объектов — YAS не аллоцирует временные объекты или какие-либо рантаймовские структуры. как приятный бонус — сериализация и десериализация JSON формата в YAS, в десяток раз быстрее топовой(не буду называть проект) по производительности библиотеки для работы с JSON в с++.
далее.
при десериализации JSON-объектов созданных при помощи YAS — комбинируйте опции yas::json и yas::compact, это еще несколько повысит скорость разбора JSON из-за того, что при использовании опции yas::compact YAS расчитывает на то, что JSON-объект точно передает порядок следования ключей и что в JSON-объекте нет никаких лишних символов, типа отступов и переносов строк.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
за последнее время реализовал такие мелочи как:
1. yas::save()/yas::load(), пример можно глянуть тут
2. поддержку std::optional<>/std::variant<> и std::string_view для С++17
3. добавил макросы-кодогенераторы YAS_DEFINE_STRUCT_SERIALIZE()/YAS_DEFINE_STRUCT_SERIALIZE_NVP()/YAS_DEFINE_INTRUSIVE_SERIALIZE()/YAS_DEFINE_INTRUSIVE_SERIALIZE_NVP()
сейчас думаю на тем, чтоб выкатить новый формат текстовой структурированной сериализации, наподобие JSON, но более "быстрой" и менее человекочитаемой =)
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
в YAS есть некоторая ошибка, которую нужно фиксить на big-endian машине.
вопрос в том, может ли кто-нить предоставить доступ к такой машине, приблизительно на час-два?
спасибо.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)