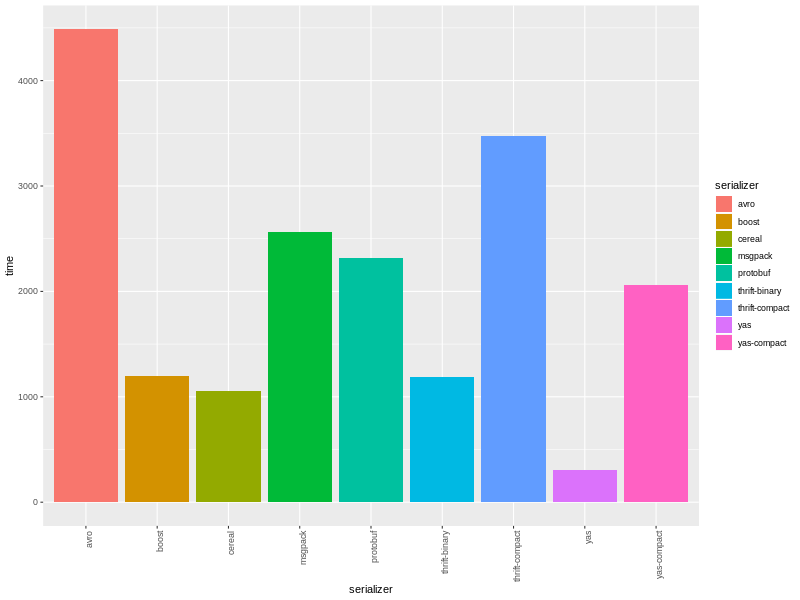
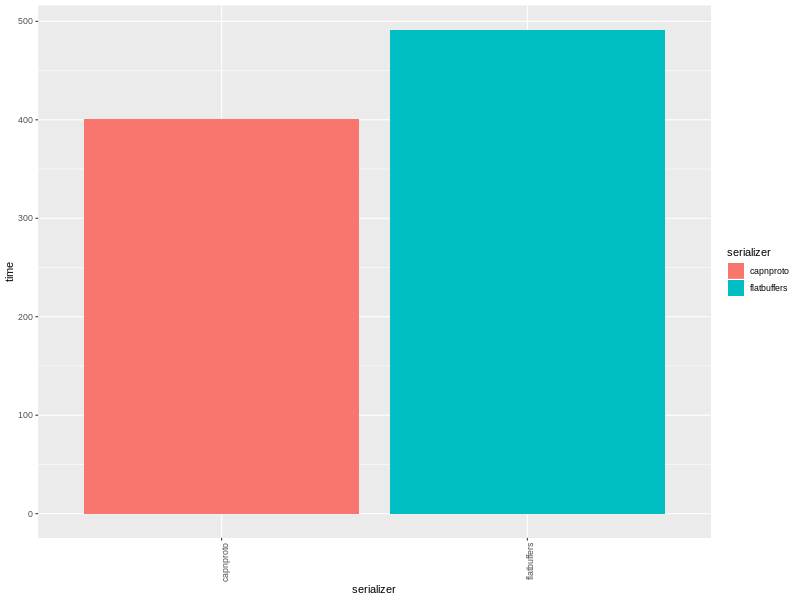
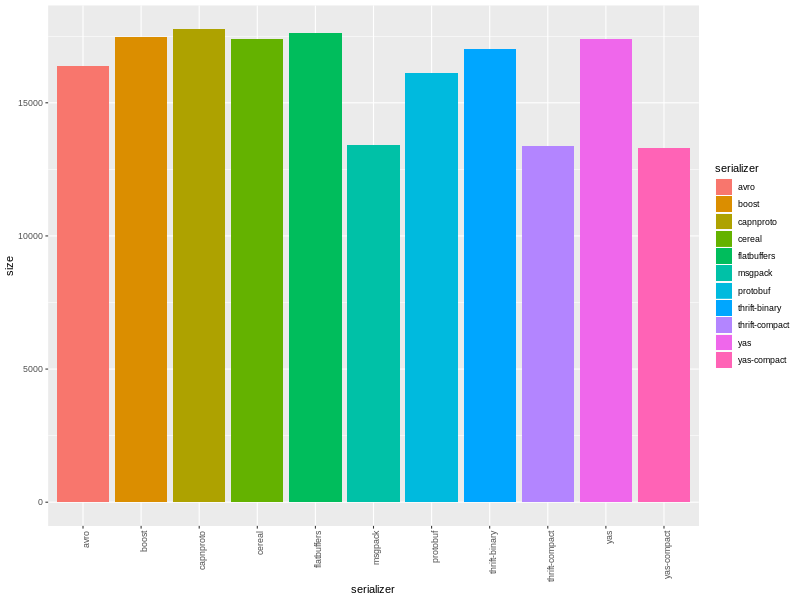
Здравствуйте, greenpci, Вы писали:
VTT>>2) &string[0] — это реально стремно G>Я как-то тоже поставил коллеге ошибку в ревью из-за этого. Потом, когда читал Страуструпа, нашел примеры, где он это бессовестно делал.
А что в этом стремного, если у тебя C++11 и выше? Если 03, то все понятно – так делать не стоит, во избежание.
Здравствуйте, kaa.python, Вы писали:
KP>А что в этом стремного, если у тебя C++11 и выше? Если 03, то все понятно – так делать не стоит, во избежание.
та нет тут ничего стремного.
расстраивало лишь то, что AddressSanitizer ругался. но формально тут все безопасно, т.к. если string.size() == 0, то по факту мы не читаем данные из пустой строки.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
X>расстраивало лишь то, что AddressSanitizer ругался. но формально тут все безопасно, т.к. если string.size() == 0, то по факту мы не читаем данные из пустой строки.
мне тоже кажется, что стремного ничего нет. Не было у строки data(), как у вектора, вот и проходилось так делать. Альтернатива была одна, использовать vector<char>, но это тоже не идеально.
одно значительное изменение в том, что далее предпочтительно сериализовать не используя такую запись:
yas::binary_oarchive<> oa(...);
oa & var0
& var1
& var2
;
но такую:
yas::binary_oarchive<> oa(...);
oa & YAS_OBJECT("object", var0, var1, var2);
// либо так, если имена переменных не совпадают(не должны совпадать) с именами ключей в архиве
oa & YAS_OBJECT_NVP(
"object"
,("v0", var0)
,("v1", var1)
,("v2", var2)
);
ну и как "плюшка", добавил простой способ сериализации/десериализации. (т.е. функции yas::save() и yas::load())
примеры тут.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, so5team, Вы писали:
S>Да в любом, в каком вам удобнее.
какой тип архива вас интересует в первую очередь?
и, позвольте несколько почти офтопных вопроса:
1. вы собираетесь писать сериализатор/десериализатор для других ЯП?
2. и, если не секрет, в каких проектах вы используете YAS?
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
S>>Да в любом, в каком вам удобнее. X>какой тип архива вас интересует в первую очередь?
Я так понял, что у вас есть два бинарных формата: компактный и не очень. Вот эти и интересуют.
X>1. вы собираетесь писать сериализатор/десериализатор для других ЯП?
Нет. Но для того, чтобы брать чей-то готовый сериализатор, хочется понимать, что у него внутри. Может он by design пригоден только для каких-то ограниченных сфер применения и некоторые важные фичи (вроде точек расширения/версионирования, поддержки опциональности и пр.) там отсутствуют как класс.
X>2. и, если не секрет, в каких проектах вы используете YAS?
Пока ни в каких. Но результаты бенчмарков заинтересовали, да.
в локальной версии есть еще одна оптимизация размера для compacted архивов, которая снова сломает совместимость, посему будет выпущена еще и шестая версия YAS.
далее, думаю сменить имя проекта, на что-то более серьезное и выпуститься под версией 0.1.
есть предложения по названию?
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, so5team, Вы писали:
S>Я так понял, что у вас есть два бинарных формата: компактный и не очень. Вот эти и интересуют.
ок, займусь на выходных.
S>Нет. Но для того, чтобы брать чей-то готовый сериализатор, хочется понимать, что у него внутри. Может он by design пригоден только для каких-то ограниченных сфер применения и некоторые важные фичи (вроде точек расширения/версионирования, поддержки опциональности и пр.) там отсутствуют как класс.
версионность — в планах.
опциональность — при помощи std::optional/boost::optional
а что такое "точки расширения"?
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
X>версионность — в планах.
Есть подозрение, что поддержка версионности и расширяемости схемы данных негативно скажется на производительности.
X>опциональность — при помощи std::optional/boost::optional
Это не то. Опциональность полей в сериализуемом представлении -- это либо возможность не сохранять поле (если у него, скажем, дефолтное значение), либо возможность отсутствия поля в сериализованном представлении вообще (тогда при десериализации полю подставляется дефолтное значение).
X>а что такое "точки расширения"?
Погуглите ASN.1 Extension Markers. Это специальные пометки в описании схемы данных, которые говорят о том, что в следующих версиях в этих местах возможно расширение схемы. Тема эта непосредственно связана с версионностью.
Здравствуйте, so5team, Вы писали:
S>Есть подозрение, что поддержка версионности и расширяемости схемы данных негативно скажется на производительности.
скорее всего так и будет...
S>Это не то. Опциональность полей в сериализуемом представлении -- это либо возможность не сохранять поле (если у него, скажем, дефолтное значение), либо возможность отсутствия поля в сериализованном представлении вообще (тогда при десериализации полю подставляется дефолтное значение).
при несохранении поля вообще, каким образом противоположная сторона узнает, что это поле может/должно быть/отсутствовать?
и, если на одной стороне какое-то поле удалили/исключили, как другая сторона должна себя вести если она ожидает это поле?
и, подскажите, чем не подходит optional?
S>Погуглите ASN.1 Extension Markers. Это специальные пометки в описании схемы данных, которые говорят о том, что в следующих версиях в этих местах возможно расширение схемы. Тема эта непосредственно связана с версионностью.
как все сложно %)
по поводу версионности я пока не имею конечного решения...
готов выслушать ваши предложения.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
Здравствуйте, niXman, Вы писали:
S>>Это не то. Опциональность полей в сериализуемом представлении -- это либо возможность не сохранять поле (если у него, скажем, дефолтное значение), либо возможность отсутствия поля в сериализованном представлении вообще (тогда при десериализации полю подставляется дефолтное значение). X>при несохранении поля вообще, каким образом противоположная сторона узнает, что это поле может/должно быть/отсутствовать? X>и, если на одной стороне какое-то поле удалили/исключили, как другая сторона должна себя вести если она ожидает это поле?
Это зависит...
Например, можно в схеме данных указать, что какое-то поле опциональное. Т.е. его может не быть во входном потоке вообще. В этом случае формат представления (т.е. формат архива) должен поддерживать какой-то способ разметки, который позволяет узнать, есть ли поле или его нет. В случае двоичных форматов это может достигаться разными способами:
если применяется механизм TLV (он же BER из ASN.1), то само отсутствие тега для поля говорит о том, что поля во входящем потоке нет. При записи архива так же все просто -- соответствующий TLV просто не пишется;
если нет TLV, а поля располагаются по порядку (как в PER из ASN.1), то могут использоваться какие-то битовые маски, которые пишутся либо в начале объекта, либо в определенных точках. Либо в самом простом случае каждому опциональному полю может предшествовать байт-маркер (если 0, значит поля нет).
Но это пока речь шла больше об опциональности при чтении из входного потока. Отдельный вопрос -- это поддержка опциональности при записи. Могут быть случаи, когда у объекта N полей, которые практически всегда содержат дефолтные значения. Если эти поля всегда серилизовать, то неэкономно расходуется место, чего хотелось бы избежать. Поэтому интересно иметь возможность задавать предикаты, которые бы подсказывали, нуждается поле в сохранении или нет.
X>и, подскажите, чем не подходит optional?
Потому что это вообще ортогонально наличию значения в двоичном представлении. Optional в программе явно говорит, есть ли значение поля в структуре или нет. Но когда оно есть у него может быть значение, которое не имеет смысла сохранять, т.к. оно дефолтное.
X>по поводу версионности я пока не имею конечного решения... X>готов выслушать ваши предложения.
Почитайте, как устроены двоичные форматы BER и PER из ASN.1. Эти, имхо, подошли к проблеме версионирования наиболее серьезно. В том же google protobuf, afaik, всего лишь вариация на тему BER-а. Еще можно глянуть в сторону MessagePack.
Здравствуйте, so5team, Вы писали:
S>Например, можно в схеме данных указать, что какое-то поле опциональное. Т.е. его может не быть во входном потоке вообще. В этом случае формат представления (т.е. формат архива) должен поддерживать какой-то способ разметки, который позволяет узнать, есть ли поле или его нет. В случае двоичных форматов это может достигаться разными способами: S>
S>если применяется механизм TLV (он же BER из ASN.1), то само отсутствие тега для поля говорит о том, что поля во входящем потоке нет. При записи архива так же все просто -- соответствующий TLV просто не пишется; S>если нет TLV, а поля располагаются по порядку (как в PER из ASN.1), то могут использоваться какие-то битовые маски, которые пишутся либо в начале объекта, либо в определенных точках. Либо в самом простом случае каждому опциональному полю может предшествовать байт-маркер (если 0, значит поля нет). S>
S>Но это пока речь шла больше об опциональности при чтении из входного потока. Отдельный вопрос -- это поддержка опциональности при записи. Могут быть случаи, когда у объекта N полей, которые практически всегда содержат дефолтные значения. Если эти поля всегда серилизовать, то неэкономно расходуется место, чего хотелось бы избежать. Поэтому интересно иметь возможность задавать предикаты, которые бы подсказывали, нуждается поле в сохранении или нет.
нужно подумать...
S>Почитайте, как устроены двоичные форматы BER и PER из ASN.1. Эти, имхо, подошли к проблеме версионирования наиболее серьезно. В том же google protobuf, afaik, всего лишь вариация на тему BER-а. Еще можно глянуть в сторону MessagePack.
ок, почитаю, посмотрю...
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
поддержка JSON таки была реализована. это было невероятно сложно %)
в отличии от большинства JSON парсеров(хотя, наверное, всех), YAS не парсит JSON в рантаймовскую структуру типа ключ-значение с последующим извлечением по имени ключей.
взгляните на этот пример кода:
int a=1;
double b=3.14;
string c="str";
auto obj = YAS_OBJECT(
nullptr
,a
,b
,c
);
тут YAS_OBJECT() — макрос. первый агрумент которого в данный момент не используется, но в будущем планируется использовать его в качестве имени(идентификатора) объекта.
остальные аргументы — переменные, ссылки на которые и хранит obj в тьюпле. так же obj хранит сгенеренную в компайл-тайм, отсортированную в компайл-тайм по ключу, static const мапу типа uint32(hash of key)->uint8(pos in tuple).
и вот, при десериализации JSON, при считывании ключа — считаем хеш ключа, — в мапе, за логарифмическое время находим пару, из пары извлекаем значение(позиция в тьюпле), и контекст десериализатора передаем для десериализации нужного элемента. из этого, как вы могли догадаться, вытекает следующее(что, оказывается, большинство кодеров повергает в ступор): невозможно десериализовать JSON, структура которого неизвестна! (некоторое отступление от темы: с++ — статически типизированный ЯП, для меня, как для с++ кодера, такое "ограничение" кажется закономерным. но за последний месяц при внедрении YAS в качестве JSON сериализатора-десериализатора мне пришлось множеству кодеров(и коллег, в том числе) объяснять, что то, как они привыкли работать с JSON в с++ — не соответствует не только идеологии самого с++, но и идеологии плюсовых кодеров. они же привыкли, при помощи любой из доступных библиотек для работы с JSON, сначала десериализовать весь JSON полностью, и только потом, использую геттеры — забрать только нужное, несмотря на то, что пришлось десериализовать весь JSON, в рантаймовскую структуру, со множеством аллокаций и зверским оверхедом)
если же при десериализации нам приходит ключ который мы не просили — YAS просто скипает все до тех пор, пока JSON-контекст не достигнет слеующего ключа этого же уровня. и да, obj может ссылаться на другие объекты, которые могут ссылаться на другие объекты, етц...
ввиду того, что YAS требует описания стуктуры JSON объектов — YAS не аллоцирует временные объекты или какие-либо рантаймовские структуры. как приятный бонус — сериализация и десериализация JSON формата в YAS, в десяток раз быстрее топовой(не буду называть проект) по производительности библиотеки для работы с JSON в с++.
далее.
при десериализации JSON-объектов созданных при помощи YAS — комбинируйте опции yas::json и yas::compact, это еще несколько повысит скорость разбора JSON из-за того, что при использовании опции yas::compact YAS расчитывает на то, что JSON-объект точно передает порядок следования ключей и что в JSON-объекте нет никаких лишних символов, типа отступов и переносов строк.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
за последнее время реализовал такие мелочи как:
1. yas::save()/yas::load(), пример можно глянуть тут
2. поддержку std::optional<>/std::variant<> и std::string_view для С++17
3. добавил макросы-кодогенераторы YAS_DEFINE_STRUCT_SERIALIZE()/YAS_DEFINE_STRUCT_SERIALIZE_NVP()/YAS_DEFINE_INTRUSIVE_SERIALIZE()/YAS_DEFINE_INTRUSIVE_SERIALIZE_NVP()
сейчас думаю на тем, чтоб выкатить новый формат текстовой структурированной сериализации, наподобие JSON, но более "быстрой" и менее человекочитаемой =)
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)
в YAS есть некоторая ошибка, которую нужно фиксить на big-endian машине.
вопрос в том, может ли кто-нить предоставить доступ к такой машине, приблизительно на час-два?
спасибо.
пачка бумаги А4 стОит 2000 р, в ней 500 листов. получается, лист обычной бумаги стОит дороже имперского рубля =)