У существующего форматтера есть целый ряд недостатков:
1) Он построен на тормозных регексах, да еще и с целой кучей проходов
2) Отсутствует программная модель разметки, как следствие сложно реализовать различные вещи типа правильного цитирования таблиц, изменений при цитировании картинок и т.п.
3) Не очень удобный для использования и избыточный синтаксис.
4) Крайне ограниченные возможности по расширению, опять же за счет того что большая часть построена на регексах
5) Отсутствие формальной и легко читаемой спецификации, что усложняет жизнь по реализации на платформах, отличных от дотнета. Ну и готовый набор тесткейсов тоже был бы не лишними.
6) У статей свой собственный, отдельный язык разметки
В связи с чем предлагаю:
1) Поднять руку тому, кому эта тема вообще интересна.
2) Обсудить оптимальный синтаксис, чтобы его и писать было удобно, и парсить не слишком сложно.
3) Если появится достаточное количество желающих — сформировать формальную спецификацию, тесткейсы и реализовать форматтер (прежде всего под .NET, ну и под другие платформы по желанию).
4) Интегрировать все это в сайт и оффлайн-клиентов.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK> В связи с чем предлагаю: AVK> 1) Поднять руку тому, кому эта тема вообще интересна.
AVK> 3) Если появится достаточное количество желающих — сформировать формальную спецификацию, тесткейсы и реализовать форматтер (прежде всего под .NET, ну и под другие платформы по желанию).
Я на данный момент готов собрать максимальное количестов тэгов разметки, которые так или иначе использовались (то, что форматтер их не поддерживает, часто не мешает людям использовать). Это позволит посмотреть с чем вообще имеем дело и сможем ли сохранить обратную совместимость, возможно чем-то пожертвовать и т.д. Т.е. оценить "масштаб бедствия".
А так же писать/поддерживать тесты, если формат входящих и сравниваемых данных будет независим от .NET (чтобы иметь возможность проверять тесты локально).
Здравствуйте, Anton Batenev, Вы писали:
AB>Я на данный момент готов собрать максимальное количестов тэгов разметки, которые так или иначе использовались (то, что форматтер их не поддерживает, часто не мешает людям использовать)
Это ты вообще о чем?
AB>. Это позволит посмотреть с чем вообще имеем дело и сможем ли сохранить обратную совместимость, возможно чем-то пожертвовать и т.д. Т.е. оценить "масштаб бедствия".
Обратная совместимость вовсе не обязательна. Мне вообще идея тегов совсем не нравится, много писанины и переключений раскладки. Я скорее к чему то навроде markdown предрасположен. А для старых сообщений можно либо конвертер сделать, либо просто ввести флажок в БД сервера — тип форматтера.
AB>А так же писать/поддерживать тесты, если формат входящих и сравниваемых данных будет независим от .NET (чтобы иметь возможность проверять тесты локально).
Формат, разумеется, будет независим. Именно в этом и смысл. Да и какой там формат? Размеченный текст на входе, html в качестве образца результата.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>У существующего форматтера есть целый ряд недостатков: AVK>1) Он построен на тормозных регексах, да еще и с целой кучей проходов AVK>2) Отсутствует программная модель разметки, как следствие сложно реализовать различные вещи типа правильного цитирования таблиц, изменений при цитировании картинок и т.п. AVK>3) Не очень удобный для использования и избыточный синтаксис. AVK>4) Крайне ограниченные возможности по расширению, опять же за счет того что большая часть построена на регексах AVK>5) Отсутствие формальной и легко читаемой спецификации, что усложняет жизнь по реализации на платформах, отличных от дотнета. Ну и готовый набор тесткейсов тоже был бы не лишними. AVK>6) У статей свой собственный, отдельный язык разметки
AVK>В связи с чем предлагаю: AVK>1) Поднять руку тому, кому эта тема вообще интересна. AVK>2) Обсудить оптимальный синтаксис, чтобы его и писать было удобно, и парсить не слишком сложно. AVK>3) Если появится достаточное количество желающих — сформировать формальную спецификацию, тесткейсы и реализовать форматтер (прежде всего под .NET, ну и под другие платформы по желанию). AVK>4) Интегрировать все это в сайт и оффлайн-клиентов.
У меня есть некоторое свободное время до конца года, из нужного тебе опыта — создания компилятора из теха в метайфайл для врачей и разметки различных виндовских логов по группам (ну это далеко), так что если есть потребность в руках — свисти.
Здравствуйте, denisko, Вы писали:
D>У меня есть некоторое свободное время до конца года, из нужного тебе опыта — создания компилятора из теха в метайфайл для врачей и разметки различных виндовских логов по группам (ну это далеко), так что если есть потребность в руках — свисти.
Пока есть потребность придумать удобный и функциональный синтаксис, покрывающий все возможности форматтера текущего. Как я уже писал — за основу можно взять markdown.
Проект на bitbucket я открою.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, denisko, Вы писали:
D>>У меня есть некоторое свободное время до конца года, из нужного тебе опыта — создания компилятора из теха в метайфайл для врачей и разметки различных виндовских логов по группам (ну это далеко), так что если есть потребность в руках — свисти.
AVK>Пока есть потребность придумать удобный и функциональный синтаксис, покрывающий все возможности форматтера текущего.
Ок, понял. Прими тогда в качестве реквеста поддержку отображения формул (если есть возможность), потому что иногда надо что -то формулой показать, а на словах выходит криво.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, denisko, Вы писали:
D>>У меня есть некоторое свободное время до конца года, из нужного тебе опыта — создания компилятора из теха в метайфайл для врачей и разметки различных виндовских логов по группам (ну это далеко), так что если есть потребность в руках — свисти.
AVK>Пока есть потребность придумать удобный и функциональный синтаксис, покрывающий все возможности форматтера текущего. Как я уже писал — за основу можно взять markdown.
Здравствуйте, AndrewVK, Вы писали:
AVK>5) Отсутствие формальной и легко читаемой спецификации, что усложняет жизнь по реализации на платформах, отличных от дотнета. Ну и готовый набор тесткейсов тоже был бы не лишними. AVK>6) У статей свой собственный, отдельный язык разметки
Накидаю идей. Мой выбор тегов продиктов
1) удобством употребления тегов форматиования в текстах на языках программирования. Последовательности символов должны быть редки или невозможны для популярных языков.
1) удобством употребления тегов форматиования в текстах на языках. Последовательности символов должны быть редки или невозможны для популярных языков, удобны при надо в русской раскладке.
2) удобстовм набора
3) припродной недекватностью
Пока что придумалось такое, но я вижу много разных проблем и надо думать ещё.
$ — условное обозначение начала строки. Символ после $ — первый в строке
Style
RSDN ML
Мой выбор
Header level 1
[h1]Header[/h1]
$! Header
Header level 2
[h2]Header[/h2]
$!! Header
Header level 3
[h3]Header[/h3]
$!!! Header
Header level 4
[h4]Header[/h4]
$!!!! Header
Header level 5
[h5]Header[/h5]
$!!!!! Header
Header level 6
[h6]Header[/h6]
$!!!!!! Header
Bold
[b]bold[/b]
**bold**
Italic
[i]italic[/i]
//italic//
Underlike
[u]underline[/u]]
___underline__
Strikethrough
[s]strikethrough[/s]
--strikethough--
Block quote
[q]quote[/q]
@@quote@@
Horizontal rule
[hr]
$------
Cписки
.1 пункт
.1.1 под-пункт
.4 пункт с принудительным номером
=====csharp
public static class Program
{
public static void Main(string[] args)
{
public const string HtmlTemplate =@"
=====html
<html><body></body></html>
=====
";
}
}
====
Здравствуйте, AndrewVK, Вы писали:
AVK> AB>Я на данный момент готов собрать максимальное количестов тэгов разметки, которые так или иначе использовались (то, что форматтер их не поддерживает, часто не мешает людям использовать) AVK> Это ты вообще о чем?
Я просто думал, что предполагается оставить совместимость с уже имеющейся разметкой.
AVK> Обратная совместимость вовсе не обязательна. Мне вообще идея тегов совсем не нравится, много писанины и переключений раскладки. Я скорее к чему то навроде markdown предрасположен. А для старых сообщений можно либо конвертер сделать, либо просто ввести флажок в БД сервера — тип форматтера.
На сколько я понимаю, синтаксис markdown покрывает практически все текущие потребности и для него есть уже готовые парсеры на разных языках (т.е. изобретать ничего особо не придется, а даже наоборот, возможно, урезать).
Основная используемая разметка на форумах:
* Списки (~1%)
* Изображения (~2%)
* Цитаты (~6%) — в markdown отсутствует явный аналог
* Код (~15%) — потребует небольшой доработки для разделения по языкам (типа как на github)
* Ссылки (~18%)
* Таглайн (22%) — с удовольствием бы пожертвовал за ненадобностью
* Выделение текста — B/U/I/S (~25%)
Тэги email и msdn легко заменяются ссылками, остаются тэг moderator и таблицы.
Оставлю эту статистику до утра — с хорошей мыслью надо переспать.
Здравствуйте, denisko, Вы писали:
d> Ок, понял. Прими тогда в качестве реквеста поддержку отображения формул (если есть возможность), потому что иногда надо что -то формулой показать, а на словах выходит криво.
С формулами, к счастью, все более-менее просто — достаточно тэга img:
Здравствуйте, Anton Batenev, Вы писали:
AB>На сколько я понимаю, синтаксис markdown покрывает практически все текущие потребности
И десятой части не покрывает.
AB> и для него есть уже готовые парсеры на разных языках (т.е. изобретать ничего особо не придется, а даже наоборот, возможно, урезать).
Боюсь, все таки придется.
AB>* Цитаты (~6%) — в markdown отсутствует явный аналог
Цитаты там есть, почти такие же как сейчас, только без указания автора в префиксе. Или ты про блочную цитату?
AB>* Код (~15%) — потребует небольшой доработки для разделения по языкам (типа как на github) AB>* Ссылки (~18%) AB>* Таглайн (22%) — с удовольствием бы пожертвовал за ненадобностью AB>* Выделение текста — B/U/I/S (~25%) AB>Тэги email и msdn легко заменяются ссылками, остаются тэг moderator и таблицы.
Здравствуйте, Mamut, Вы писали:
M>В маркдауне есть одна большая проблема — он контекстно зависим. То ест, например, внутри блочных элементов по канону маркдаун не парсится: http://daringfireball.net/projects/markdown/syntax
Поэтому — взять за основу.
M>Плюс есть свои заморочки типа inline html
Выкинуть.
M>То есть, все сильно зависит от того, насколько сильно вы будете основывать именно на маркдауне
В меру разумного.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>1) Поднять руку тому, кому эта тема вообще интересна.
+ AVK>2) Обсудить оптимальный синтаксис, чтобы его и писать было удобно, и парсить не слишком сложно.
В качестве базы весьма симпатичен Tiddlywiki: списки, нумерованные списки, ссылки, цитаты, заголовки, таблицы (http://www.scribd.com/doc/2189287/Tiddlywiki-Formatting-Guide).
Впрочем, у большинства вики-движков синтаксис аналогичен или близок.
Сложный вопрос — форматирование цитат при ответе. AVK>3) Если появится достаточное количество желающих — сформировать формальную спецификацию, тесткейсы и реализовать форматтер (прежде всего под .NET, ну и под другие платформы по желанию).
Спецификацию — можно попробовать.
Тесткейсы — возможно (если порог входа не очень крутой).
Форматтер — точно нет.
Здравствуйте, Don Reba, Вы писали:
DR>А почему бы не взять готовый форматтер, типа Sundown который используют на Гитхабе? У него есть байндинги для .NET.
На странице с верхней ссылки, в самом начале, тоже идёт линк на http://daringfireball.net/projects/markdown/syntax (Markdown Syntax Guide at Daring Fireball) + далее "Differences from traditional Markdown" (я так понимаю, там перечисляются гитхабовские расширения).
Т.е. для знакомства с языком можно использовать обе ссылки.
Здравствуйте, Don Reba, Вы писали:
DR>А почему бы не взять готовый форматтер, типа Sundown который используют на Гитхабе? У него есть байндинги для .NET.
Я не уверен, что он хорошо подойдет под потребности рсдн.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>У существующего форматтера есть целый ряд недостатков:
Самый большой недостаток в отсутсвии четкой иерархии и независмости, и потому он не исправимый..
Поясню свою мысль..
Допустим надо определить (изменить) шрифт или еще какой-то параметр. Для реализации такой задачи применяется тег или команда или инструкция. Ну, так как мы привыкли в программировании. Область действия этой инструкции не задается никак. Считается что она действует вплоть до следующей команды изменяющей или отменяющей значение этого параметра. Отсюда программа, которая обеспечивает выполнение, отмену или изменение этого параметра должна не только выполнять действия с учетом значения этого параметра, но и хранить его до тех пор пока не поступит новая инструкция по изменению этого параметра... Т.е. изменяться. Понятное дело что такая программа должна заведомо знать все возможные инструкции, параметры и варианты взаимодействия. Таким образом программа реализующая инструкции должна быть достаточно сложной (апологеты фунционального языка понимают о чем речь) и являться по сути средой для тех же инструкций.
Хороший язык должен обеспечивать вложенность каждого тега (или инструкции) и обеспечивать собой среду для всех инструкций находящихся внутри нее (или его если это тег).
Здесь нас подстерегает другая проблема. Если данная инструкция обеспечивает среду (т.е. параметры) для вложенных в нее инструкций, то мы не сможем отттранслировать (не говоря уже о том что бы выполнить) данную инструкцию потому как данная инструкция заканчивается после всех инструкций находящихся внутри ее, а потому и трансляция и выполнение тоже не возможны. Получается некая неразрешимая проблема. Что б задать параметры для выполнения вложенных инструкций нужно выполнить эту инструкцию, а выполнить ее не можем потому что она еще не закончилась. Но эту проблема таки можно решать.. Если такой подход интересует, то можем продолжить с интересующимися. А если высказался не в тему, то извините.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Don Reba, Вы писали:
DR>>А почему бы не взять готовый форматтер, типа Sundown который используют на Гитхабе? У него есть байндинги для .NET.
AVK>Я не уверен, что он хорошо подойдет под потребности рсдн.
А какие у него потребности? Ты хочешь чтобы новый форматтер использовался для форума или для статей тоже?
Если для форума, то я согласен с adontz надо выбрать наиболее эргономичные комбинации для форматирования сообщений и разработать не гемморойный механизм подсветки кода.
Если для сайта тоже, то я бы рекоммендовал что-то ТЕХоподобное, поскольку множества народа который пишет статьи [ на рсдн] и множества народа, который владеет техом сильно пересекается. Тех удобен тем, что можно задать под себя окружение и область действия команд, что для форума оверкилл и вредно.
Здравствуйте, dеnisko, Вы писали:
AVK>>Я не уверен, что он хорошо подойдет под потребности рсдн. D>А какие у него потребности?
Покрытие всего существующего функционала как минимум. Доступ к модели разметки для допфункций типа цитирования (у большинства готовых форматтеров такого нет, там просто на входе разметка, на выходе html).
D> Ты хочешь чтобы новый форматтер использовался для форума или для статей тоже?
Да.
D>Если для форума, то я согласен с adontz надо выбрать наиболее эргономичные комбинации для форматирования сообщений и разработать не гемморойный механизм подсветки кода.
И я тоже с этим согласен.
D>Если для сайта тоже, то я бы рекоммендовал что-то ТЕХоподобное
Т.е. опять два разных формата да еще и рендерер теха в html?
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, dеnisko, Вы писали:
AVK>>>Я не уверен, что он хорошо подойдет под потребности рсдн. D>>А какие у него потребности?
AVK>Покрытие всего существующего функционала как минимум. Доступ к модели разметки для допфункций типа цитирования (у большинства готовых форматтеров такого нет, там просто на входе разметка, на выходе html).
Ну надо начать тогда с того, чтобы собрать требования, причем расширенные, и фичреквесты. Может быть тебе следовало бы написать спеку существующего функционала (как сайта, так и форума), чтобы все знали что есть, чего нет.
D>>Если для сайта тоже, то я бы рекоммендовал что-то ТЕХоподобное
AVK>Т.е. опять два разных формата да еще и рендерер теха в html?
РСДН еще и бумажный журнал, который так или иначе нужно верстать, проще всего это сделать в техе. Можно сблизить поелику возможно, т.е. сделать близкий по духу к ТЕХ ML, а из него сделать конвертер в настояющий ТЕХ для бумаги и в HTML для сайта.
Здравствуйте, dеnisko, Вы писали:
D>Ну надо начать тогда с того, чтобы собрать требования, причем расширенные, и фичреквесты.
Я не против. Минимум в стартовом сообщении я указал.
D> Может быть тебе следовало бы написать спеку существующего функционала (как сайта, так и форума), чтобы все знали что есть, чего нет.
Если есть вопросы по семантике какого то тега — спрашивай.
AVK>>Т.е. опять два разных формата да еще и рендерер теха в html? D>РСДН еще и бумажный журнал
Там все равно тех не годится, там нужен ворд.
D>, который так или иначе нужно верстать, проще всего это сделать в техе.
Это много раз обсуждалось. Ответ редакторов неизменен — тех не нужен.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Это мало пригодно для дополнительного форматирования исходного кода. То есть var x = 1/2; станет началом курсивного блока. Будет путаница.
Соглашусь с batu (я мало понял его мысль, но что потом не обиделся, что украли) об интересности, ассиметричного форматирования.
То есть например :* начинает жирный текст, :/ начинает курсив, :: очищает форматирование.
:*жирный и :/курсив:: просто текст -> жирный и курсив просто текст
Здравствуйте, adontz, Вы писали:
A>Это мало пригодно для дополнительного форматирования исходного кода. То есть var x = 1/2; станет началом курсивного блока. Будет путаница.
Я не уверен что внутри блока допформатирование нужно. И альтернативы существенно более тяжеловесны.
A>То есть например :* начинает жирный текст, :/ начинает курсив, :: очищает форматирование.
То есть в 2 раза больше писанины и не декларативно. Не уверен что это лучше возможных ложных срабатываний.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Из первых косяков.
Битбакетовская вика не полностью поддерживает русский язык в заголовках, поэтому построить оглавление с использованием встроенных средств не получится (<<toc 3>> — оглавление вплоть до третьего уровня заголовков). Само оглавление построится, но переходить по ссылкам будет невозможно.
Здравствуйте, adontz, Вы писали:
AVK>>Я не уверен что внутри блока допформатирование нужно. И альтернативы существенно более тяжеловесны.
A>Ладно, тогда хорошо бы писать номера строк. потому что код бывает длиный.
Не понял. Ты имеешь в виду при форматировании добавлять к строкам номера или что?
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
A>>Ладно, тогда хорошо бы писать номера строк. потому что код бывает длиный. AVK>Не понял. Ты имеешь в виду при форматировании добавлять к строкам номера или что?
Да, потому что бывает надо сконцентрировать внимание на конкретном участке довольно длиного кода (10-15 строк). Можно добавлять номера строк. Так многие делают и это полезно. Ещё можно как-то выделять строки (менять фон), типа текущей строки в редакторе (как в новой VS), то есть вся подсветка такая же, но цвет фона немного другой.
Здравствуйте, ShaggyOwl, Вы писали:
SO>Из первых косяков. SO>Битбакетовская вика не полностью поддерживает русский язык в заголовках, поэтому построить оглавление с использованием встроенных средств не получится (<<toc 3>> — оглавление вплоть до третьего уровня заголовков). Само оглавление построится, но переходить по ссылкам будет невозможно.
Это проблема в их реализации и только — я давно как-то им писал об этом, но видимо так и не починили, всё таки буржуям этим наш русский нафиг не упал.
PS: А вот Nemerle в свойства репы — добавили быстро и без проблем (тем более, что N и так уже подсвечивался пигментами).
Мне лично нравятся creole-like, т.е. знаки равно в начале строки.
Во-первых, это напрямую связывается с h1/h2/../h6 (логически).
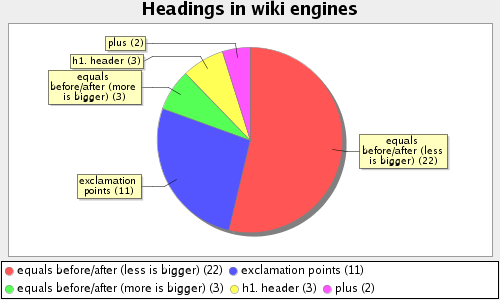
Во-вторых мой мозг испорчен креолом.
Ну и в третьих — судя по твоей диаграмме — это выбор большинства.
Здравствуйте, fddima, Вы писали:
F> Это проблема в их реализации и только — я давно как-то им писал об этом, но видимо так и не починили, всё таки буржуям этим наш русский нафиг не упал.
Так с этим никто и не спорит — пойнт в том, что нам теперь с этим косяком жить и он совершенно не очевиден в начале работы. Плюс, косвенное свидетельство сырости битбакетовской вики — надо быть готовым и к другим сюрпризам.
Здравствуйте, fddima, Вы писали:
F>Мне лично нравятся creole-like, т.е. знаки равно в начале строки. F>Во-первых, это напрямую связывается с h1/h2/../h6 (логически). F>Во-вторых мой мозг испорчен креолом. F>Ну и в третьих — судя по твоей диаграмме — это выбор большинства.
Вариант с восклицательными знаками не так уж плох. А вот ====== неправильное количество знаков до и после ===== может сильно раздражать.
Здравствуйте, adontz, Вы писали:
A>Вариант с восклицательными знаками не так уж плох. А вот ====== неправильное количество знаков до и после ===== может сильно раздражать.
Но в креоли не требуется равное количество знаков, их в конце можно не писать вообще. Т.е. вполне можно сделать, так, что бы последние знаки не игнорировать, а использовать как текст — тогда не будет "несуразицы".
А восклицательные знаки — я согласен, ничем не хуже. Я ж и написал, что лично я привык к =, и мне они нравятся. Но имхо совершенно не принципиально. Тут нужно решить, и лучше решить так, что бы было либо то, либо другое, а не так как получилось в креоли с концевыми равно, которые существуют видимо больше для совместимости с другими, имхо.
Здравствуйте, adontz, Вы писали:
A>Да, потому что бывает надо сконцентрировать внимание на конкретном участке довольно длиного кода (10-15 строк).
Тогда это не важно сейчас, это просто особенность уже генератора html.
A>Ещё можно как-то выделять строки (менять фон), типа текущей строки в редакторе (как в новой VS), то есть вся подсветка такая же, но цвет фона немного другой.
Можно подумать. Например в начале строки добавлять >>>
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, ShaggyOwl, Вы писали:
SO>Какие будут предложения по выбору синтаксиса?
Я в https://bitbucket.org/andrewvk/rsdn.format/wiki/Specification указал вариант со знаками =. Как оказалось, он же наиболее часто используемый. !! мне не нравится, h2. плохо видно в неформатированном тексте — сливается с ним и уровни неразличимы. = в конце в большинстве вик опционально и просто игнорируется. Мне кажется, смысла в таком нет, и так все хорошо видно.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, ShaggyOwl, Вы писали:
SO>Мне более симпатичен вариант с восклицательными знаками.
Восклицательные знаки, имхо, коррелируют с каким то аварийным сообщением. В текущем виде я эту комбинацию оставил под модераторские и системные сообщения, по семантике вроде бы больше подходит.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, adontz, Вы писали:
A>Вариант с восклицательными знаками не так уж плох. А вот ====== неправильное количество знаков до и после ===== может сильно раздражать.
Уровни больше 3 все равно редко используются. А 1-4 уровни очень хорошо различимы.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Я тут подумал. Не весь код, ведь, оформляеться, как код. То есть как бы текст
"Если поле _first класса LinkedList равно полю _last, то список считается пустым"
не превратился в
"Если поле first класса LinkedList равно полю last, то список считается пустым"
С подчерками и другими значками надо осторожнее. Я потому и хотел их удваивать. Иначе придётся кучу исключений продумать и не факт что будет всегда нормально работать.
Ну и по реализации. ИМХО лучше делать code->AST->html, потому что на конце может быть не только html. Может банальность сказал и уже говорилось, тогда извините.
Здравствуйте, adontz, Вы писали:
A> Я потому и хотел их удваивать. Иначе придётся кучу исключений продумать и не факт что будет всегда нормально работать.
А с удвоением выглядит хуже. Так что я ХЗ.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, adontz, Вы писали:
A>Ну и по реализации. ИМХО лучше делать code->AST->html
Я об этом в стартовом сообщении написал.
A>потому что на конце может быть не только html
Это как раз ерунда. Куда важнее, что есть алгоритмы, прежде всего подготовка цитирования, где парсинг тоже нужен. Сейчас такой код частично дублируется, а прикрутить дополнительные вещи типа специального цитирования каких то конструкций довольно трудно.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Обратная совместимость вовсе не обязательна. Мне вообще идея тегов совсем не нравится, много писанины и переключений раскладки. Я скорее к чему то навроде markdown предрасположен. А для старых сообщений можно либо конвертер сделать, либо просто ввести флажок в БД сервера — тип форматтера.
Для олдфагов оставьте BBCode, пожалуйста
Комментарии.
1. Жирный, курсив, подчёркивание, зачёркивание, верхний и нижний индексы — только с помощью двойных символов **bold**, //italic// и т.д. Аргументация — одиночные символы время от времени встречаются в простом тексте и неочевидный результат форматирования обязательно будет сбивать с толку новичков. По выбранным символам комментариев нет.
2. Заголовки. ИМХО, более интуитивно простыми будут восклицательные знаки, но против знаков равенства особых возражений нет. Отсутствие знаков с правой стороны от заголовка — большой плюс.
3. Списки. Важно добавить уровни
*
**
***
#
##
###
4. Ссылки
[[a link]]
[[a link|with title]]
Изображения сделать на основе ссылок (конкретное предложение будет чуть позже).
5. Код и цитирование
Какие альтернативы есть? Тут ошибиться в выборе нельзя, иначе потом будет мучительно больно.
Здравствуйте, Marty, Вы писали:
SO>># M>А как же препроцессор языка C?
Будет располагаться в блоке кода, на который распространяются совсем другие правила форматирования.
Список
# Lorem ipsum dolor sit amet, consectetur adipiscing elit.
# Suspendisse volutpat est sed ante iaculis lacinia.
# Quisque sit amet metus in justo laoreet bibendum.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, adontz, Вы писали:
A>>Вариант с восклицательными знаками не так уж плох. А вот ====== неправильное количество знаков до и после ===== может сильно раздражать.
AVK>Уровни больше 3 все равно редко используются. А 1-4 уровни очень хорошо различимы.
Тогда может быть сделать заголовки \section -> \subsection -> \subsectionN , где N -- показатель глубины вложенности секции должен быть от 2 до бесконечности
Вообще мне хочется, чтобы была возможность включить определенное форматирование типа \begin{italic} \end{italic} для большой группы текста.
Также надо продумать о форматировании кода, т.е. либо жестко забиваем кывтовское форматирование кода, либо позволяем включать свое т.е.
[code]
\setoffset{tabs}
\setoffset{spaces}
\setbraces{java}
пошел код
Здравствуйте, dеnisko, Вы писали:
D>Тогда может быть сделать заголовки \section -> \subsection -> \subsectionN , где N -- показатель глубины вложенности секции должен быть от 2 до бесконечности
Аргументы против синтаксиса :
* Не используется ни в одной вики http://www.wikimatrix.org/syntax.php?i=115 (да и на форумах, предполагаю, может применяться нечасто).
* Достаточно громоздок по сравнению с #Заголовок первого уровня, ##Заголовок второго уровня
D>Вообще мне хочется, чтобы была возможность включить определенное форматирование типа \begin{italic} \end{italic} для большой группы текста.
//Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. //
И всё форматируется наклонным шрифтом. Возможно, до конца абзаца.
D>Также надо продумать о форматировании кода, т.е. либо жестко забиваем кывтовское форматирование кода, либо позволяем включать свое т.е. D>[code] D>\setoffset{tabs} D>\setoffset{spaces} D>\setbraces{java} D>пошел код D>[\code]
А можешь прокомментировать что будут делать в данном случае setoffset{tabs}, setoffset{spaces}? Преобразовывать существующие в блоке кода отступы?
Здравствуйте, ShaggyOwl, Вы писали:
SO>Здравствуйте, dеnisko, Вы писали:
D>>Тогда может быть сделать заголовки \section -> \subsection -> \subsectionN , где N -- показатель глубины вложенности секции должен быть от 2 до бесконечности SO>Аргументы против синтаксиса : SO>* Не используется ни в одной вики http://www.wikimatrix.org/syntax.php?i=115 (да и на форумах, предполагаю, может применяться нечасто). SO>* Достаточно громоздок по сравнению с #Заголовок первого уровня, ##Заголовок второго уровня
Зато читать легче, в #,##,## путаешься постоянно
например
je slepi tekst, ki se uporablja pri razvoju tipografij in pri pripravi za tisk. Lorem Ipsum je v uporabi že več kot petsto let saj je to kombinacijo znakov neznani tiskar združil v vzorčno knjigo že v začetku 16. stoletja. To besedilo pa ni zgolj preživelo pet stoletij, temveč se je z malenkostnimi spremembami uspešno uveljavilo tudi v elektronskem namiznem založništvu. Na priljubljenosti je Lorem Ipsum pridobil v sedemdesetih letih prejšnjega stoletja, ko so na trg lansirali Letraset folije z Lorem Ipsum odstavki. V zadnjem času se Lorem Ipsum pojavlja tudi v priljubljenih programih za namizno založništvo kot je na primer Aldus PageMaker.
#littleheader
okazano je, da razumljiva vsebina, med pregledovanjem oblikovne rešitve določene strani, neželeno preusmeri pozornost bralca. Ker ima Lorem Ipsum relativno enakomerno razporeditev znakov uspešno nadomesti začasna vsebinsko pomenska besedila. Veliko namizno založniških programov in spletnih urejevalnikov uporablja Lorem Ipsum kot privzeti slepi tekst. Zato spletno iskanje s ključnimi besedami "lorem ipsum" vrne številne zadetke še nedokončanih spletnih mest. Tekom let so namreč nastale številne različice tega slepega teksta, bodisi nenačrtovano ali namenoma, z različnimi šaljivimi in drugimi vložki.
против
je slepi tekst, ki se uporablja pri razvoju tipografij in pri pripravi za tisk. Lorem Ipsum je v uporabi že več kot petsto let saj je to kombinacijo znakov neznani tiskar združil v vzorčno knjigo že v začetku 16. stoletja. To besedilo pa ni zgolj preživelo pet stoletij, temveč se je z malenkostnimi spremembami uspešno uveljavilo tudi v elektronskem namiznem založništvu. Na priljubljenosti je Lorem Ipsum pridobil v sedemdesetih letih prejšnjega stoletja, ko so na trg lansirali Letraset folije z Lorem Ipsum odstavki. V zadnjem času se Lorem Ipsum pojavlja tudi v priljubljenih programih za namizno založništvo kot je na primer Aldus PageMaker.
\section{littleheader}
okazano je, da razumljiva vsebina, med pregledovanjem oblikovne rešitve določene strani, neželeno preusmeri pozornost bralca. Ker ima Lorem Ipsum relativno enakomerno razporeditev znakov uspešno nadomesti začasna vsebinsko pomenska besedila. Veliko namizno založniških programov in spletnih urejevalnikov uporablja Lorem Ipsum kot privzeti slepi tekst. Zato spletno iskanje s ključnimi besedami "lorem ipsum" vrne številne zadetke še nedokončanih spletnih mest. Tekom let so namreč nastale številne različice tega slepega teksta, bodisi nenačrtovano ali namenoma, z različnimi šaljivimi in drugimi vložki.
имхо, во втором при редактировании заголовок найти проще.
D>>Вообще мне хочется, чтобы была возможность включить определенное форматирование типа \begin{italic} \end{italic} для большой группы текста. SO>
SO>//Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. //
SO>
SO>И всё форматируется наклонным шрифтом. Возможно, до конца абзаца.
// может использоваться еще где-то в тексте, а \\ забили для ссылок, будет путаница + ориентироваться по крупным конструкциям проще без предпросмотра. Мое имхо, лучшая логика для текста с разметкой -- для мелких блоков используется мелкие и максимально эргономичные конструкции типа //курсив// для крупных
\begin{italic}
абзац
\end{italic}. Причина -- проще ориентироваться.
D>>Также надо продумать о форматировании кода, т.е. либо жестко забиваем кывтовское форматирование кода, либо позволяем включать свое т.е. D>>[code] D>>\setoffset{tabs} D>>\setoffset{spaces} D>>\setbraces{java} D>>пошел код D>>[\code] SO>А можешь прокомментировать что будут делать в данном случае setoffset{tabs}, setoffset{spaces}? Преобразовывать существующие в блоке кода отступы?
для подогнать отступы под твое видение мира, setoffset{tabs} -- записать табами, setoffset{spaces} -- пробелами, setoffset{spaces = 3} -- все отступы пробелами, таб /автоотступ заменяется на 3 пробела.
Здравствуйте, dеnisko, Вы писали:
D>>>Тогда может быть сделать заголовки \section -> \subsection -> \subsectionN , где N -- показатель глубины вложенности секции должен быть от 2 до бесконечности SO>>Аргументы против синтаксиса : SO>>* Не используется ни в одной вики http://www.wikimatrix.org/syntax.php?i=115 (да и на форумах, предполагаю, может применяться нечасто). SO>>* Достаточно громоздок по сравнению с #Заголовок первого уровня, ##Заголовок второго уровня D>Зато читать легче, в #,##,## путаешься постоянно
Вероятно, это субъективно, но я не путаюсь (правда в моём случае заголовки это не "==" или "##", а "!!").
Совершенно точно не путаюсь в списках (имхо, тривиальный и интуитивно понятный способ записи).
*
**
**
#
#
##
D>// может использоваться еще где-то в тексте
Сделать поиск по своим текстам — как часто вне кода ты используешь двойной слеш, двойное подчёркивание, двойное умножение и т.д. Думаю, практически не используешь. Именно поэтому подобный синтаксис активно используется в различных вики, см. http://www.wikimatrix.org/syntax.php?i=24
SO>>А можешь прокомментировать что будут делать в данном случае setoffset{tabs}, setoffset{spaces}? D>для подогнать отступы под твое видение мира, setoffset{tabs} -- записать табами, setoffset{spaces} -- пробелами, setoffset{spaces = 3} -- все отступы пробелами, таб /автоотступ заменяется на 3 пробела.
Тут комментировать затрудняюсь.
Большой необходимости не вижу, но если реализовать будет легко, то почему бы нет?
Здравствуйте, dеnisko, Вы писали:
D>Тогда может быть сделать заголовки \section -> \subsection -> \subsectionN , где N -- показатель глубины вложенности секции должен быть от 2 до бесконечности
Я понимаю твою любовь к теху, но проблема та же, что и у h1 — прохо различимы уровни, нужно раскрадку переключать, да еще и писанины много да конфликтов куча. D>Вообще мне хочется, чтобы была возможность включить определенное форматирование типа \begin{italic} \end{italic} для большой группы текста.
Можно добавить блочные аналоги для существующих стилей — типа *** и /// скобок.
D>Также надо продумать о форматировании кода, т.е. либо жестко забиваем кывтовское форматирование кода, либо позволяем включать свое т.е.
Я пока склоняюсь к тому, чтобы разрешить только выделение болдом внутри кода.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Восклицательные знаки, имхо, коррелируют с каким то аварийным сообщением. В текущем виде я эту комбинацию оставил под модераторские и системные сообщения, по семантике вроде бы больше подходит.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, dеnisko, Вы писали:
D>>Тогда может быть сделать заголовки \section -> \subsection -> \subsectionN , где N -- показатель глубины вложенности секции должен быть от 2 до бесконечности
AVK>Я понимаю твою любовь к теху, но проблема та же, что и у h1 — прохо различимы уровни, нужно раскрадку переключать, да еще и писанины много да конфликтов куча.
Насчет раскладки согласен, насчет различимости только с 2 и выше уровней. Насчет писанины зависит от того, как ты хочешь реализовывать. Если ползать чем-то типа saxа по тексту, ловить ключевики, искать совпадаюшие с ними конечные ключевики и потом плеваться блоками между этими ключевиками на обработку форматтеру, то \section это просто еще один ключевик, для которого задаются правила. Если по другому, то да может превратиться в геморрой.
AVK>Можно добавить блочные аналоги для существующих стилей — типа *** и /// скобок.
Ну тогда надо добавить, ибо удобно.
D>>Также надо продумать о форматировании кода, т.е. либо жестко забиваем кывтовское форматирование кода, либо позволяем включать свое т.е.
AVK>Я пока склоняюсь к тому, чтобы разрешить только выделение болдом внутри кода.
А к переформатированию как относишься? Иногда нужно, ибо читать совсем не форматированный или дико-форматированный код тяжело.
Здравствуйте, ShaggyOwl, Вы писали:
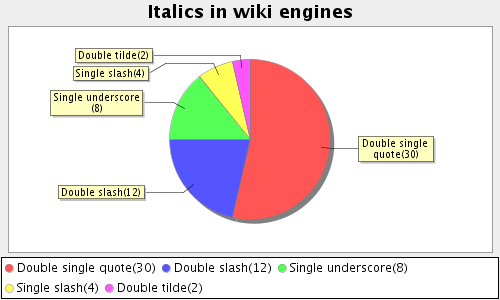
SO>1. Жирный, курсив, подчёркивание, зачёркивание, верхний и нижний индексы — только с помощью двойных символов **bold**, //italic// и т.д. Аргументация — одиночные символы время от времени встречаются в простом тексте и неочевидный результат форматирования обязательно будет сбивать с толку новичков. По выбранным символам комментариев нет.
Против. Нужно, чтобы одиночные символы в простом тексте не считались за маркеры форматирования.
Неформально, чтобы понять, может ли пара символов интерпретироваться как маркеры форматирования, нужно попробовать заменить их на скобки. Если при этом получается недопустимая по правилам типографики последовательность — значит, не может.
Примеры:
foo*bar — нет (отсутствует парность)
*foo* bar — (foo) bar — да
*foo *bar — (foo )bar — нет: у скобки не может быть пробела с внутренней стороны и не может быть буквы с внешней
foo* bar* — foo( bar — нет, по тем же причинам
foo*bar*baz — нет
foo*bar baz*quux — нет
foo *bar baz* quux — да
foo *bar*. — foo (bar). — да
*Foo bar.* Baz quux frob. — (Foo bar.) Baz quux frob. — да
Случаи, когда требуется выделить часть слова, считаю редкими и предлагаю обсудить отдельно на примерах. Сразу парочку контрпримеров, где выделение части слова не нужно:
* ударение: неправильно — напис/а/л; правильно — написа́л (и да, давайте сменим шрифт с Verdan’ы, пока не все ещё проапгрейдились)
* исправление орфографии: неправильно — «не к/а/рова, а к/о/рова», правильно — проигнорировать или написать в личку
SO>2. Заголовки. ИМХО, более интуитивно простыми будут восклицательные знаки, но против знаков равенства особых возражений нет. Отсутствие знаков с правой стороны от заголовка — большой плюс.
Я за == с игнорированием знаков справа.
SO>3. Списки. Важно добавить уровни
+1.
SO>4. Ссылки SO>[[a link]] SO>[[a link|with title]] SO>Изображения сделать на основе ссылок (конкретное предложение будет чуть позже).
+1.
SO>5. Код и цитирование SO>Какие альтернативы есть? Тут ошибиться в выборе нельзя, иначе потом будет мучительно больно.
Trac: (shebang-конвенция активно не нравится!)
{{{
#!php
…
}}}
bbcode-style: (да, считаю для фрагментов кода допустимым)
[[php]
[[/php]
старый Confluence:
{code=php}
{code}
новый Confluence: (слишком многословно)
{code:language=php}
{code}
Bruce Eckel–style: (Thinking in C++/Java)
//:
//#
Неудачные варианты: классический Markdown, классическая Ward’s Wiki (индентация).
А кроме того, я полагаю, что можно перенести синтаксическую раскраску на клиента: в HTML отдавать <pre><code class="language-php">, а клиентский скрипт пусть расставляет все span’ы.
Цитирование вещь неочевидная. Fido-style префиксы (FML>) хороши для гейтования в NNTP, но желателен алгоритм reflow при перецитировании. В идеале, должно быть можно взять сообщение, применить на него алгоритм цитирования (приклеивающий префикс FML> к оригинальным строкам и увеличивающий уровень вложенности в цитированных), затем вставить свои новые строки (возможно, с разметкой) в любом месте, и получившееся должно быть валидным сообщением. В частности, должен работать пример:
VP> {{{ c++
VP> #include <iostream>
VP>
VP> void main()
В C++ функция {{main}} должна возвращать {{int}}.
VP> {
VP> std::cout << "Hello World!\n";
VP> }
VP> }}}
Ожидаемое поведение:
<blockquote data-attribution="VP"><pre><code class="language-cpp">#include <iostream>
void main()</code></pre></blockquote>
<p>В C++ функция <code>main</code> должна возвращать <code>int</code>.
<blockquote data-attribution="VP"><pre><code class="language-cpp">{
std::cout << "Hello World!\n";
}</code></pre></blockquote>
Здравствуйте, dеnisko, Вы писали:
D>Насчет писанины зависит от того, как ты хочешь реализовывать. Если ползать чем-то типа saxа по тексту
Под писаниной я понимаю, что писать при наборе текста много. Никто не будет выписывать длинные теховские теги в форумном сообщении.
AVK>>Я пока склоняюсь к тому, чтобы разрешить только выделение болдом внутри кода. D>А к переформатированию как относишься?
Вменяемый форматтер только для одного мейнстрим языка — это минимум человекомесяцы работы.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, ShaggyOwl, Вы писали:
SO>1. Жирный, курсив, подчёркивание, зачёркивание, верхний и нижний индексы — только с помощью двойных символов **bold**, //italic// и т.д. Аргументация — одиночные символы время от времени встречаются в простом тексте и неочевидный результат форматирования обязательно будет сбивать с толку новичков. По выбранным символам комментариев нет.
Видимо да, придется.
SO>3. Списки. Важно добавить уровни
Да, тут просто я не уверен на 100% пока в синтаксисе.
SO>4. Ссылки SO>[[a link]] SO>[[a link|with title]]
А чем предложенное не устраивает?
SO>Изображения сделать на основе ссылок (конкретное предложение будет чуть позже).
Вроде бы так и есть сейчас.
SO>5. Код и цитирование SO>Какие альтернативы есть? Тут ошибиться в выборе нельзя, иначе потом будет мучительно больно.
Альтернатив не очень много. Помимо двойных и тройных {} я встречал 4-5 символов =, но это писать больше. В маркдауне используется grave accent, но у некоторых этот символ используется для переключения раскладки. Еще есть выделение кода 4 пробелами с начала строки, тут я вообще затрудняюсь оценить, насколько оно удобно. Ббшный [code][/code] тоже применяется, но он очень многословен. Остальные варианты довольно экзотичны, но если кто знает какой интересный вариант — можно обсудить.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, Centaur, Вы писали:
C>А кроме того, я полагаю, что можно перенести синтаксическую раскраску на клиента: в HTML отдавать <pre><code class="language-php">, а клиентский скрипт пусть расставляет все span’ы.
Мысль, конечно, интересная, особенно интересная тем, что можно что нибудь готовое использовать, типа highlight.js. Но требования к клиенту, если мы раскраску хотим, существенно повышаются. И добавление нового языка будет несколько проблематично (nemerle, скажем, точно готового нет, а ведь захотят некоторые). С другой стороны, всегда ведь можно раскраску сразу в генераторе html прикрутить позже.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали: SO>>4. Ссылки SO>>[[a link]] SO>>[[a link|with title]] AVK>А чем предложенное не устраивает?
О квадратных скобках. http://www.wikicreole.org/wiki/LinksReasoning
Классическое решение для вики — ссылка в одинарных или двойных квадратных скобках.
О двойных квадратных скобках.
С учётом того, что на рсдн в обычном тексте вполне могут мелькать одинарные квадратные скобки (индексы в контейнерах, отрезки, диапазоны), то имеет смысл сделать двойные скобки. Двойные квадратные скобки тоже могут встречаться в обычном тексте, но предполагаю, существенно реже.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, ShaggyOwl, Вы писали:
SO>>Классическое решение для вики — ссылка в одинарных или двойных квадратных скобках.
AVK>Есть одна проблема — сиволов [|] нет в русской раскладке. Но чем их заменить у меня идей нет. Двойными или тройными обычными скобками?
Может, кавычками (если ты их не забил уже), а цитата частный случай ссылки?
Здравствуйте, dеnisko, Вы писали:
AVK>>Есть одна проблема — сиволов [|] нет в русской раскладке. Но чем их заменить у меня идей нет. Двойными или тройными обычными скобками? D>Может, кавычками (если ты их не забил уже)
Блочная цитата использует.
D>, а цитата частный случай ссылки?
Ничего общего вроде бы. Блочная цитата это то, что сейчас выделяется тегом [q]. А одинарные кавычки в русской раскладке отсутствуют.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, adontz, Вы писали:
A>Что это вообще?
Шаблонное форматирование. Т.е. ты описываешь шаблон, без параметров или с каким то их количеством, и потом просто используешь его по имени с передачей значений параметров, если необходимо.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
A>>Что это вообще? AVK>Шаблонное форматирование. Т.е. ты описываешь шаблон, без параметров или с каким то их количеством, и потом просто используешь его по имени с передачей значений параметров, если необходимо.
Макросы что ли? Ну, по идее, любое форматирование может рассматриваться как частный случай макроса.
Здравствуйте, AndrewVK, Вы писали:
AVK>Есть одна проблема — сиволов [|] нет в русской раскладке. Но чем их заменить у меня идей нет. Двойными или тройными обычными скобками?
Мдямс. Об этом я как-то не подумал.
С другой стороны, насколько это необходимо? Ориентируясь на собственный опыт — раскладка меняется постоянно, десятки раз на дню: документы, комментарии, заметки и тексты, часть поисковых запросов пишутся на русском; адреса в браузере, код, команды в консоли, часть запросов в гугл — на английском, соответственно нажатие alt+shift уже отработано до автоматизма.
Здравствуйте, AndrewVK, Вы писали:
D>>, а цитата частный случай ссылки?
AVK>Ничего общего вроде бы. Блочная цитата это то, что сейчас выделяется тегом [q]. А одинарные кавычки в русской раскладке отсутствуют.
Ну любая цитата может рассматриваться как частный случай ссылки без указания источника (что в общем сейчас и происходит).
Т.е.
Как сказал Иван иваныч блаблабла
по сути дела означает
Как сказал Иван иваныч блаблабла [ссылка на то, где он это сказал]
Другое дело, что это не спасет нас от переключения раскладки, но поможет сэкономить один тэг / символ.
Внутри блока кода вместо одинарного символа * следует использовать двойной **
Так никто не будет делать. Код копипейстится откуда-нибудь, где его проверяли на то, что он компилируется (или не компилируется) и работает (не работает), после чего его не трогают.
Допустимый способ выделения чего-либо в программном коде — подстрочное подчёркивание или стрелочка в комментарии:
Здравствуйте, dеnisko, Вы писали:
D>Ну любая цитата может рассматриваться как частный случай ссылки без указания источника (что в общем сейчас и происходит).
Смысл этой словесной эквилибристики? URL и цитата куска текста — совершенно разные сущности, даже если по русски их можно обозвать одним словом.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, ShaggyOwl, Вы писали:
SO>С другой стороны, насколько это необходимо?
Необходимость переключения раскладки существенно замедляет набор и делает его менее комфортным, а так же иногда приводит к ошибкам с не той раскладкой. Поэтому мне кажется, что в часто используемых конструкциях без смены раскладки желательно обойтись. При этом для редких вещей, типа суперскрипта, это уже не так важно.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, Centaur, Вы писали:
C>Так никто не будет делать. Код копипейстится откуда-нибудь, где его проверяли на то, что он компилируется (или не компилируется) и работает (не работает), после чего его не трогают.
Исходя из такой логики, [b] внутри кода сейчас тоже не работает. Однако факты нам говорят, что все же работает. Наверное, потому что не всегда копипастят, а когда копипастят, то могут подправить.
C>// ^^^^ так делать нельзя!
И как, будем для каждого языка писать парсер комментариев?
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Необходимость переключения раскладки существенно замедляет набор и делает его менее комфортным, а так же иногда приводит к ошибкам с не той раскладкой. Поэтому мне кажется, что в часто используемых конструкциях без смены раскладки желательно обойтись. При этом для редких вещей, типа суперскрипта, это уже не так важно.
Тогда вероятно да, двойные круглые скобки могут подойти.
Здравствуйте, dеnisko, Вы писали: D>>>Тогда может быть сделать заголовки \section -> \subsection -> \subsectionN , где N -- показатель глубины вложенности секции должен быть от 2 до бесконечности
После некоторого осмысления. По прежнему кажется, что для небольших сообщений более удачными будут короткие спецсимволы вроде "==", но вот для статей, возможно что правда окажется немного другой.
У меня к сожалению нет опыта применения таких тегов (и написания более-менее крупных текстов), надо пробовать.
Здравствуйте, AndrewVK, Вы писали:
SO>>5. Код и цитирование SO>>Какие альтернативы есть? Тут ошибиться в выборе нельзя, иначе потом будет мучительно больно.
AVK>Альтернатив не очень много. Помимо двойных и тройных {} я встречал 4-5 символов =, но это писать больше. В маркдауне используется grave accent, но у некоторых этот символ используется для переключения раскладки. Еще есть выделение кода 4 пробелами с начала строки, тут я вообще затрудняюсь оценить, насколько оно удобно. Ббшный [code][/code] тоже применяется, но он очень многословен. Остальные варианты довольно экзотичны, но если кто знает какой интересный вариант — можно обсудить.
После некоторого осмысления, вариант с тройными скобками кажется вполне допустимым.
Кстати, а до двух скобок получится сократиться?
Ещё идея в копилку. Мы, пока что, при обсуждении синтаксиса исходим из абсолютной примитивности редактора разметки. В то же время даже для браузера это не верно, не говоря уже об отдельном приложении.
То есть если меня спросить что проще и логичнее набрать
мама **мыла** раму
или
мама [Ctrl+B]мыла[Ctrl+B] раму (где [Ctrl+B] может вставлять любой неудобный для набора код форматирования)
то я голосую за второй вариант. Мы все регулярно пользуемся клавиатурными cокращениями, так что ничего нового тут нет. Тем кто мало набирает всё равно, а тем кто много, удобнее. Ведь даже если взять символ /. Да, он есть в обеих раскладках, но на разных клавишах, а это сводит на нет всю выгоду.
Сырая идея на осмысление.
В случаях, когда текст должен содержать некоторую зарезервированную форматтером последовательность символов, например "//", тильда может отменять форматирование. Т.е. при наборе "~//", получим "//".
Дополнения:
* "Звёздочка" в каждой ячейке — заголовке (будет трансформирована в <th>)
* Выравнивание по левой/правой сторонам, центру в зависимости от расположения текста в ячейке
Здравствуйте, ShaggyOwl, Вы писали:
SO>После некоторого осмысления. По прежнему кажется, что для небольших сообщений более удачными будут короткие спецсимволы вроде "==", но вот для статей, возможно что правда окажется немного другой.
Важный момент — не надо думать об специфике бумажного журнала — все равно все статьи переверстываются (раньше был ворд через конвертер в индизайн, сейчас хз). Под статьями надо понимать прежде всего то, что выкладывается в веб и, потенциально, в личный блог. Т.е. когда речь о статье, то это не какая то специфичная вестка, а просто наличие ряда конструкций, отсутствующих или редко присутствующих в сообщении — заголовки, содержание, сноски и т.п.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, ShaggyOwl, Вы писали:
SO>После некоторого осмысления, вариант с тройными скобками кажется вполне допустимым. SO>Кстати, а до двух скобок получится сократиться?
ХЗ. В принципе — наверное да.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, ShaggyOwl, Вы писали:
SO>Дополнения: SO>* "Звёздочка" в каждой ячейке — заголовке (будет трансформирована в <th>) SO>* Выравнивание по левой/правой сторонам, центру в зависимости от расположения текста в ячейке SO>
Я таблички еще днем добавил. Отличие от твоего варианта только одно — у меня достаточно звездочки в первой ячейке. Потому что в одной строке и заголовки и обычные ячейки — малополезная штука, так зачем дублировать.
SO>Возможно ещё colspan, rowspan добавить.
Можно, но как?
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, ShaggyOwl, Вы писали:
SO>Сырая идея на осмысление. SO>В случаях, когда текст должен содержать некоторую зарезервированную форматтером последовательность символов, например "//", тильда может отменять форматирование. Т.е. при наборе "~//", получим "//".
В креоле так, да. Только опять проблемы с раскладкой — тильда может использоваться для переключения раскладок.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK> Исходя из такой логики, [b] внутри кода сейчас тоже не работает. Однако факты нам говорят, что все же работает. Наверное, потому что не всегда копипастят, а когда копипастят, то могут подправить.
Допустить ошибку форматирования в исходнике гораздо проще, нежели в простом тексте. Я бы вообще оставил исходный код в покое кроме подсветки синтаксиса и, возможно, нумерации строк (опционально).
Здравствуйте, AndrewVK, Вы писали:
C>>Так никто не будет делать. Код копипейстится откуда-нибудь, где его проверяли на то, что он компилируется (или не компилируется) и работает (не работает), после чего его не трогают.
AVK>Исходя из такой логики, [b] внутри кода сейчас тоже не работает. Однако факты нам говорят, что все же работает. Наверное, потому что не всегда копипастят, а когда копипастят, то могут подправить.
[b] — гораздо менее частотная последовательность, чем *. Даже взятие элемента массива по индексу i встречается сильно реже, чем умножение и разыменование указателя/итератора. А то ещё бывают комментарии (*в Паскале*) и /*в Си-подобных*/, их тоже будем выделять?
Здравствуйте, adontz, Вы писали:
A>То есть если меня спросить что проще и логичнее набрать A>мама **мыла** раму A>или A>мама [Ctrl+B]мыла[Ctrl+B] раму (где [Ctrl+B] может вставлять любой неудобный для набора код форматирования) A>то я голосую за второй вариант.
+1 и я даже писал Greasemonkey-скрипт для таких вещей. Только, во-первых, по одному нажатию вставляется сразу пара кодов (открывающий и закрывающий) и курсор ставится между ними. Это если нет выделения. А если выделение есть, то оно заключается в пару кодов и они тоже включаются в выделение.
А во-вторых, у кого-нибудь может возникнуть соблазн развить идею до WYSIWYG-редактора, и вот это я уже приветствовать не могу.
Здравствуйте, ShaggyOwl, Вы писали:
SO>В случаях, когда текст должен содержать некоторую зарезервированную форматтером последовательность символов, например "//", тильда может отменять форматирование. Т.е. при наборе "~//", получим "//".
Тогда уж не тильда, а классический бэкслэш. И да, такая практика есть, в старом Confluence это было.
AVK>Я таблички еще днем добавил. Отличие от твоего варианта только одно — у меня достаточно звездочки в первой ячейке. Потому что в одной строке и заголовки и обычные ячейки — малополезная штука, так зачем дублировать.
Для клиента не нужны. Для разработчика парсера — хз.
+ я выравнивание в ячейках обозначил.
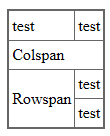
SO>>Возможно ещё colspan, rowspan добавить. AVK>Можно, но как?
|test|test|
|>|Colspan|
|Rowspan|test|
|~|test|
Позаимствовано из TiddlyWiki. Не верх изящества, однако работает
Здравствуйте, AndrewVK, Вы писали:
AVK>В креоле так, да. Только опять проблемы с раскладкой — тильда может использоваться для переключения раскладок.
Как вариант — бэкслэш.
A>мама [Ctrl+B]мыла[Ctrl+B] раму (где [Ctrl+B] может вставлять любой неудобный для набора код форматирования)
A>то я голосую за второй вариант. Мы все регулярно пользуемся клавиатурными cокращениями, так что ничего нового тут нет.
Только вот в разных браузерах и ОСях эти клавиатурные сокращения моугт быть зарезервированы, например. Плюс они не покрывают всех вариантов разметкм
Здравствуйте, ShaggyOwl, Вы писали:
AVK>>В креоле так, да. Только опять проблемы с раскладкой — тильда может использоваться для переключения раскладок. SO>Как вариант — бэкслэш.
Принято
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Опять тильда, а так приемлемо.
Согласен.
Как альтернатива — "^". Придётся переключать раскладку, но rowspan достаточно редкая операция, поэтому больших затруднений не будет.
Обновил в соответствии с пожеланиями.
Нужно решить вопрос с жирным и курсивом — толи удваивать символы, толи воспользоваться предложением по ограничению комбинаций корректными для обычных скобок вариантами.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, dеnisko, Вы писали:
D>>Ну любая цитата может рассматриваться как частный случай ссылки без указания источника (что в общем сейчас и происходит).
AVK>Смысл этой словесной эквилибристики?
Смысл в том, чтобы сэкономить на теге довольно естественным способом.
AVK>URL и цитата куска текста — совершенно разные сущности, даже если по русски их можно обозвать одним словом.
Для меня они различаются только тем, что в урле больше ссылки, в цитате больше текста, но я не навязываюсь.
Надо добавить дублирующий синтаксис для таблиц в статьях на сайте, ибо на сайте могут быть вложенные и сложные таблицы с различной разметкой и там палочки считать задолбаешься. Я бы опять таки сделал либо через
<table> <row><\row> <\table> либо через \begin{table}\begin{row} и.т.д.
Здравствуйте, dеnisko, Вы писали:
AVK>>Смысл этой словесной эквилибристики? D>Смысл в том, чтобы сэкономить на теге довольно естественным способом.
Но тогда придется придумывать несимметричный синтаксис. Потому что, когда поле с url обязательно, наличие только одного поля интерпретируется строго как опускание текста и оставление url. А вот если оба поля необязательны — нужны средства чтобы понять, какое именно поле опустили. Скажем, в текщем варианте придется сделать обязательным значок |. Или вернуться к варианту маркдауна. И еще одна проблема — урл строчный, а вот цитата уже блочная конструкция, т.е нельзя уже отсекать по нахождению на одной строке, что повышает вероятность случайного срабатывания.
D>Надо добавить дублирующий синтаксис для таблиц в статьях на сайте, ибо на сайте могут быть вложенные и сложные таблицы с различной разметкой и там палочки считать задолбаешься. Я бы опять таки сделал либо через D><table> <row><\row> <\table> либо через \begin{table}\begin{row} и.т.д.
Я думаю, что борьбу со специальными возможностями для статей надо отложить на второй этап. Т.е. помнить об этом нужно, но уделять пристальное внимание не стоит.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Обновил в соответствии с пожеланиями. AVK>Нужно решить вопрос с жирным и курсивом — толи удваивать символы, толи воспользоваться предложением по ограничению комбинаций корректными для обычных скобок вариантами.
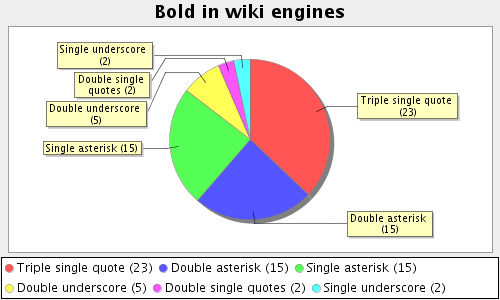
Голосую за удвоенные символы по причинам:
* простоты реализации
* привычности записи
А как предполагается осуществлять внедрение нового движка? Т.е. если внезапно изменится язык форматирования, то насколько негативно это может быть воспринято?
Здравствуйте, ShaggyOwl, Вы писали:
SO>Голосую за удвоенные символы по причинам: SO>* простоты реализации
Это точно вторично по сравнению с удобством.
SO>* привычности записи
Тоже вопрос тонкий. Вики еще не настолько в нашу жизнь вошли.
SO>Вот статистика от скрупулёзных коллег:
Ну, если опираться только на статистику, тогда надо креолу реализовывать и не морочить людям голову Тем паче что sigle asterisk вполне заметную часть занимает, да и single slash не на последнем месте.
Ну ок, возьмем за базовый вариант удвоенные * и /. Что насчет подчеркивания — тоже удваиваем и утраиваем сабскрипт?
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, Mamut, Вы писали:
A>>то я голосую за второй вариант. Мы все регулярно пользуемся клавиатурными cокращениями, так что ничего нового тут нет. M>Только вот в разных браузерах и ОСях эти клавиатурные сокращения моугт быть зарезервированы, например. Плюс они не покрывают всех вариантов разметкм
Согласен, что свободных клавиатурных сокращений не так уж много. Но вот, например, Ctrl+U в Firefox это View Source. Насколько часто надо смотреть исходный код страницы при наборе сообщения?
Здравствуйте, ShaggyOwl, Вы писали:
SO>А как предполагается осуществлять внедрение нового движка?
Видимо, флажок в БД и сразу два форматтера параллельно на первое время. И возможность выбрать разметку при написании сообщения. А дальше по статистике — если старым форматтером будет мало народу пользоваться, то выкинуть возможность использования и, в перспективе, сконвертировать старые сообщения в новый формат.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Видимо, флажок в БД и сразу два форматтера параллельно на первое время. И возможность выбрать разметку при написании сообщения. А дальше по статистике — если старым форматтером будет мало народу пользоваться, то выкинуть возможность использования и, в перспективе, сконвертировать старые сообщения в новый формат.
A>>>то я голосую за второй вариант. Мы все регулярно пользуемся клавиатурными cокращениями, так что ничего нового тут нет. M>>Только вот в разных браузерах и ОСях эти клавиатурные сокращения моугт быть зарезервированы, например. Плюс они не покрывают всех вариантов разметкм
A>Согласен, что свободных клавиатурных сокращений не так уж много. Но вот, например, Ctrl+U в Firefox это View Source. Насколько часто надо смотреть исходный код страницы при наборе сообщения?
Вопрос не только об этом. Вопрос и о том, кто будет запоминать все шорткаты? А их может получиться очень и очень немало. Каждый раз тянуться за мышкой, чтобы тыкать что-то в тулбаре? Не, увольте
Здравствуйте, AndrewVK, Вы писали:
SO>>* простоты реализации AVK>Это точно вторично по сравнению с удобством. SO>>* привычности записи AVK>Тоже вопрос тонкий. Вики еще не настолько в нашу жизнь вошли.
Вообще говоря да.
Я когда впервые с вики-синтаксисом столкнулся был слегка изумлён, уж больно непривычно для глаза выглядел ("эта мешанина из закорючек ещё и работает?!"). Впрочем, порог входа в язык разметки минимальный, удалось освоиться быстро. И есть ощущение, что если человек хоть раз сталкивался с любым из языков разметки, для освоения нового достаточно посмотреть на небольшую шпаргалку, чтобы въехать в тему (сделать такую шпаргалку будет несложно).
Интересно, насколько часто посетители рсдн сталкивались с созданием статей в вики. Опрос, что ли замутить.
Здравствуйте, Mamut, Вы писали:
A>>Согласен, что свободных клавиатурных сокращений не так уж много. Но вот, например, Ctrl+U в Firefox это View Source. Насколько часто надо смотреть исходный код страницы при наборе сообщения? M>Вопрос не только об этом. Вопрос и о том, кто будет запоминать все шорткаты? А их может получиться очень и очень немало. Каждый раз тянуться за мышкой, чтобы тыкать что-то в тулбаре? Не, увольте
Во-первых, шорткаты будут по возможности стандартными. Во-вторых, запомнит любой кто будет часто польоваться. В-третьих, речь идёт о часто употребляемых тегах форматирования, а не о всех вообще.
Скажем для форматирования кода в любом случае надо будет переключить раскладку на английскую чтобы набрать название языка программирования.
Здравствуйте, adontz, Вы писали:
A>Во-первых, шорткаты будут по возможности стандартными. Во-вторых, запомнит любой кто будет часто польоваться. В-третьих, речь идёт о часто употребляемых тегах форматирования, а не о всех вообще.
В янусе оно так уже сейчас. Только это не отменяет необходимости удобного формата разметки.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, ShaggyOwl, Вы писали: SO>Интересно, насколько часто посетители рсдн сталкивались с созданием статей в вики. Опрос, что ли замутить. http://www.rsdn.ru/poll/3671.aspx
Здравствуйте, AndrewVK, Вы писали:
A>>Во-первых, шорткаты будут по возможности стандартными. Во-вторых, запомнит любой кто будет часто польоваться. В-третьих, речь идёт о часто употребляемых тегах форматирования, а не о всех вообще. AVK>В янусе оно так уже сейчас. Только это не отменяет необходимости удобного формата разметки.
В Янусе я могу не трогая мыши, ничего не выделяя, набрать "привет Ctrl+B мир Ctrl+B" и получитcя "привет мир"?
A>Во-первых, шорткаты будут по возможности стандартными. Во-вторых, запомнит любой кто будет часто польоваться. В-третьих, речь идёт о часто употребляемых тегах форматирования, а не о всех вообще.
Что будем делать с тэгами «вставить ссылку», «вставить изображение», «вставить кусок кода», «вставить список», «вставить цитату»? Об этом тоже идет речь, а не только о том, как выделить кусок текста полужирным или курсивом
A>Скажем для форматирования кода в любом случае надо будет переключить раскладку на английскую чтобы набрать название языка программирования.
Переключили, и дальше что? Мне все равно хочется набрать какое-то минмиальное количество символов, а не запоминать какой-нить «Ctrl+Shift+K» для вставки кода
Здравствуйте, Mamut, Вы писали:
A>>Во-первых, шорткаты будут по возможности стандартными. Во-вторых, запомнит любой кто будет часто польоваться. В-третьих, речь идёт о часто употребляемых тегах форматирования, а не о всех вообще. M>Что будем делать с тэгами «вставить ссылку», «вставить изображение», «вставить кусок кода», «вставить список», «вставить цитату»? Об этом тоже идет речь, а не только о том, как выделить кусок текста полужирным или курсивом
Надо подумать. Мне не очень нравится полный уход от bbcode, потому что получается набор сиюминутных хаков, вместо логичной, пусть и многословной, системы.
A>>Скажем для форматирования кода в любом случае надо будет переключить раскладку на английскую чтобы набрать название языка программирования. M>Переключили, и дальше что? Мне все равно хочется набрать какое-то минмиальное количество символов, а не запоминать какой-нить «Ctrl+Shift+K» для вставки кода
Это вопрос пользовательского интерфейса вообще, а не кодов форматирования. Если, например, после вставки из буфера редактор сам поймёт что это код на языке программирования, то не всё ли равно как это будет записано?
A>Надо подумать. Мне не очень нравится полный уход от bbcode, потому что получается набор сиюминутных хаков, вместо логичной, пусть и многословной, системы.
Что значит "хаков". Помимо bbcode есть вагон и маленькая тележка других способов форматирования текста.
A>>>Скажем для форматирования кода в любом случае надо будет переключить раскладку на английскую чтобы набрать название языка программирования. M>>Переключили, и дальше что? Мне все равно хочется набрать какое-то минмиальное количество символов, а не запоминать какой-нить «Ctrl+Shift+K» для вставки кода
A>Это вопрос пользовательского интерфейса вообще, а не кодов форматирования. Если, например, после вставки из буфера редактор сам поймёт что это код на языке программирования, то не всё ли равно как это будет записано?
Здравствуйте, Mamut, Вы писали:
A>>Надо подумать. Мне не очень нравится полный уход от bbcode, потому что получается набор сиюминутных хаков, вместо логичной, пусть и многословной, системы. M>Что значит "хаков".
Значит что нет единообразия. Понятно, что для удобства наиболее необходимых тегов форматирования, они сделаны краткими **, //, я сам это предлагал. Но здесь уже вообще все теги особенные. Вот, скажем, я хочу добавить тег для графа на языке dot, или графика формулы. Нет никакого способа логично расширить набор тегов.
A>>Это вопрос пользовательского интерфейса вообще, а не кодов форматирования. Если, например, после вставки из буфера редактор сам поймёт что это код на языке программирования, то не всё ли равно как это будет записано? M>Меня не интересуют теоретические изыскания.
Ну а я не понимаю, как едеждевно пользуясь автодополнением при написании программ не хотетть того же при написании сообщений.
A>>>Надо подумать. Мне не очень нравится полный уход от bbcode, потому что получается набор сиюминутных хаков, вместо логичной, пусть и многословной, системы. M>>Что значит "хаков".
A>Значит что нет единообразия. Понятно, что для удобства
Ключевое. Никого не интересует единообразие, если оно приводит к увеличению количества текста, который надо набирать.
A>наиболее необходимых тегов форматирования, они сделаны краткими **, //, я сам это предлагал. Но здесь уже вообще все теги особенные. Вот, скажем, я хочу добавить тег для графа на языке dot, или графика формулы. Нет никакого способа логично расширить набор тегов.
И это решаемо. Так, как это сделано для git-flavored markdown для подсветки кода, например.
A>>>Это вопрос пользовательского интерфейса вообще, а не кодов форматирования. Если, например, после вставки из буфера редактор сам поймёт что это код на языке программирования, то не всё ли равно как это будет записано? M>>Меня не интересуют теоретические изыскания.
A>Ну а я не понимаю, как едеждевно пользуясь автодополнением при написании программ не хотетть того же при написании сообщений.
Я не понимаю, каким образом ты перешел от шорткатов к вставке и автоопределению кода к автодополнению. Вот убей меня, не понимаю.
Здравствуйте, Mamut, Вы писали:
A>>Значит что нет единообразия. Понятно, что для удобства M>Ключевое. Никого не интересует единообразие, если оно приводит к увеличению количества текста, который надо набирать.
Если оно изредка приводит к увеличению количества текста, который надо набирать, то единообразие существенно ускоряет обучение тегам.
A>>Ну а я не понимаю, как едеждевно пользуясь автодополнением при написании программ не хотетть того же при написании сообщений. M>Я не понимаю, каким образом ты перешел от шорткатов к вставке и автоопределению кода к автодополнению. Вот убей меня, не понимаю.
Потому что я думаю не о конкретной функциональности, а о user experience в целом.
A>>>Значит что нет единообразия. Понятно, что для удобства M>>Ключевое. Никого не интересует единообразие, если оно приводит к увеличению количества текста, который надо набирать.
A>Если оно изредка приводит к увеличению количества текста, который надо набирать, то единообразие существенно ускоряет обучение тегам.
Вопрос в обучаемости не стоит. Вопрос стоит в том, что текстов надо набирать доастаточно много и достаточно часто. В этом случае удобство выходит на первый план
A>>>Ну а я не понимаю, как едеждевно пользуясь автодополнением при написании программ не хотетть того же при написании сообщений. M>>Я не понимаю, каким образом ты перешел от шорткатов к вставке и автоопределению кода к автодополнению. Вот убей меня, не понимаю.
A>Потому что я думаю не о конкретной функциональности, а о user experience в целом.
Это теоретические изыскания. Потому что есть суровая реальность
Здравствуйте, Mamut, Вы писали:
A>>Если оно изредка приводит к увеличению количества текста, который надо набирать, то единообразие существенно ускоряет обучение тегам. M>Вопрос в обучаемости не стоит. Вопрос стоит в том, что текстов надо набирать доастаточно много и достаточно часто. В этом случае удобство выходит на первый план
Ты считаешь, что частота использования всех тегов форматирования абсолютно одинакова? Причём тут объём текстов? Ты понимаешь что значит оптимизировать интерфейс под сценарий использования?
A>>Потому что я думаю не о конкретной функциональности, а о user experience в целом. M>Это теоретические изыскания. Потому что есть суровая реальность
Ну повторяй эту фразу как мантру. С такими страхами получится ещё один форматтер, причём наверняка хуже существующих.
Здравствуйте, adontz, Вы писали:
A>Вот, скажем, я хочу добавить тег для графа на языке dot, или графика формулы. Нет никакого способа логично расширить набор тегов.
Ты невнимательно читал:
{{{ dot
...
}}}
{{{ formula
...
}}}
A>Ну а я не понимаю, как едеждевно пользуясь автодополнением при написании программ не хотетть того же при написании сообщений.
Хотеть то можно, а вот реализовать ...
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
A>>>Если оно изредка приводит к увеличению количества текста, который надо набирать, то единообразие существенно ускоряет обучение тегам. M>>Вопрос в обучаемости не стоит. Вопрос стоит в том, что текстов надо набирать доастаточно много и достаточно часто. В этом случае удобство выходит на первый план
A>Ты считаешь, что частота использования всех тегов форматирования абсолютно одинакова? Причём тут объём текстов? Ты понимаешь что значит оптимизировать интерфейс под сценарий использования?
Я понимаю. Поэтому я и говорю про ссылки, цитаты и прочая и прочая.
A>>>Потому что я думаю не о конкретной функциональности, а о user experience в целом. M>>Это теоретические изыскания. Потому что есть суровая реальность
A>Ну повторяй эту фразу как мантру. С такими страхами получится ещё один форматтер, причём наверняка хуже существующих.
Это не мантра, это просто понимание того, что сейчас возможно и не возможно сделать в браузере. «атвоматическое определение кода», «автодополнение» (автодополнение чего?) и прочая и прочая приведут к тому, что форматтер не появится никогда.
Если же делать форматтер, опираясь на реальность и на то, что уже есть «хуже существующих» не получится.
Здравствуйте, Mamut, Вы писали:
M>Это не мантра, это просто понимание того, что сейчас возможно и не возможно сделать в браузере. «атвоматическое определение кода», «автодополнение» (автодополнение чего?) и прочая и прочая приведут к тому, что форматтер не появится никогда. M>Если же делать форматтер, опираясь на реальность и на то, что уже есть «хуже существующих» не получится.
Во-первых, в HTML DOM есть событие OnPaste. Во-вторых, код программы легко отличить по, например, отступам (символам \t, четырём и более пробелам подряд в начале строки). Можно вырезать общий для всех строк отступ, это будет весьма удобно. Я постоянно с этим мучаюсь. Я не о космических технологиях говорю, между прочим.
Автоопределение языка программирования уже на порядки более сложная задача, хотя её вполне можно решить частично для наиболее популярных языков. Главное, чтобы не было false positives. Они раздражают.
Аналогично для ссылок. Ввёл или вставил URL. Он распознался и пользователю показывается JavaScript Prompt Box чтобы ввести описание для ссылки. Аналогично с картинками.
Здравствуйте, adontz, Вы писали:
A>Аналогично для ссылок. Ввёл или вставил URL. Он распознался и пользователю показывается JavaScript Prompt Box чтобы ввести описание для ссылки. Аналогично с картинками.
Вот модальных окон ввода не надо. Лучше курсор спозиционировать.
Здравствуйте, _Raz_, Вы писали:
A>>Аналогично для ссылок. Ввёл или вставил URL. Он распознался и пользователю показывается JavaScript Prompt Box чтобы ввести описание для ссылки. Аналогично с картинками. _R_>Вот модальных окон ввода не надо. Лучше курсор спозиционировать.
Ну или так. Я просто к тому что умный редактор это не фантастика какая-то.
A>Аналогично для ссылок. Ввёл или вставил URL. Он распознался и пользователю показывается JavaScript Prompt Box чтобы ввести описание для ссылки. Аналогично с картинками.
M>>Это не мантра, это просто понимание того, что сейчас возможно и не возможно сделать в браузере. «атвоматическое определение кода», «автодополнение» (автодополнение чего?) и прочая и прочая приведут к тому, что форматтер не появится никогда. M>>Если же делать форматтер, опираясь на реальность и на то, что уже есть «хуже существующих» не получится.
A>Во-первых, в HTML DOM есть событие OnPaste. Во-вторых, код программы легко отличить по, например, отступам (символам \t, четырём и более пробелам подряд в начале строки). Можно вырезать общий для всех строк отступ, это будет весьма удобно. Я постоянно с этим мучаюсь. Я не о космических технологиях говорю, между прочим.
Внезапно ты начал говорить про отрезание отступов. Извини, я не сопосбен уследить за прыжками твоих фантазий.
A>Автоопределение языка программирования уже на порядки более сложная задача, хотя её вполне можно решить частично для наиболее популярных языков. Главное, чтобы не было false positives. Они раздражают.
Выделенное ключевое. А так — да, конечно. Наши страхи не позволят сделать такой форматтер.
A>>>Аналогично для ссылок. Ввёл или вставил URL. Он распознался и пользователю показывается JavaScript Prompt Box чтобы ввести описание для ссылки. Аналогично с картинками. _R_>>Вот модальных окон ввода не надо. Лучше курсор спозиционировать.
A>Ну или так. Я просто к тому что умный редактор это не фантастика какая-то.

Без никаких модальных диалогов. То, что «можно и так». Но мы с интересом слушаем, какие откровения про умные редакторы
Здравствуйте, adontz, Вы писали:
A>Ну или так. Я просто к тому что умный редактор это не фантастика какая-то.
Не фантастика, но его еще написать надо. Тут Mamut ближе к реальности. Плюс AVK часто повторяет, что слаб в js, а мое имхо кричит, что на сообщество рассчитывать не приходится.
На правах ЗЫ: если будет AST, то поддержка орфографии в янусе не заставит себя ждать.
A>>Ну или так. Я просто к тому что умный редактор это не фантастика какая-то.
_R_>Не фантастика, но его еще написать надо. Тут Mamut ближе к реальности.
Да помиммо реальности, ту непонятно, про что adontz говорит.
То у него уже модальные диалоги для ссылок и изображений нужны, то не нужны (и в этом случае почти все существующие форматы подходят под требование).
То у него «анализ вставляемого кода», который неожиданно превращается в «автодополнение» (чего???), который неожиданно превращается в «убирание отступов слева»
Причем ежу понятно, что часть из этого перекрывается возможностями существующих систем (ссылки/картинки), часть сложности не представляет в любой из систем (отступы), а часть является адом вне зависимости от систем (эвристика по коду). Но adonz валит все это в кучу и заявляет «Я просто к тому что умный редактор это не фантастика какая-то»
M>>Да помиммо реальности, ту непонятно, про что adontz говорит. _R_>Ну не знаю. Лично я его понимаю и поддерживаю. Но вот работоемкость подобных идей зашкаливает.
Я тоже понимаю, что он говорит. Я не понимю, как он прыгает с одного на другое
Здравствуйте, AndrewVK, Вы писали:
AVK>Спрашивай у них. Пока что все угрозы переписать весь сайт, форматтер, etc заканчивались переписыванием компилятора Немерле.
А может просто случая не было? Прописать волшебный пендаль?
Здравствуйте, Mamut, Вы писали: M>Но adontz валит все это в кучу и заявляет «Я просто к тому что умный редактор это не фантастика какая-то»
Я не валю в кучу, я накидываю идеи. А ты просто упёрся в якобы большую сложность реализации. Вотя буквально на коленке набросал то о чём говорил. Вставляешь из буфера что-топохожее на код и он обрамляется тегом [code]. [b], [i], [u] вставляются по клавиатурным сокращениям. Как оказалось, можно отлавливать довольно странные комбинации, вроде Ctrl,Ctrl. Код проверял в FF и IE.
M>>Но adontz валит все это в кучу и заявляет «Я просто к тому что умный редактор это не фантастика какая-то»
A>Я не валю в кучу, я накидываю идеи.
Я не против накидывания идей. Я против складывания их в кучу. А именно этим ты и занимаешься.
A>А ты просто упёрся в якобы большую сложность реализации.
В сложность реализации чего? Шорткатов? Анализ кода без ложных срабатываний для практически произвольного кода? Автодополнения? Убирания отступов?
Ты бы сначала определился, о чем ты говоришь.
A>Вотя буквально на коленке набросал то о чём говорил. Вставляешь из буфера что-топохожее на код и он обрамляется тегом
Не находишь, что это немножко далеко от, цитирую
Если, например, после вставки из буфера редактор сам поймёт что это код на языке программирования...
не понимаю, как едеждевно пользуясь автодополнением при написании программ не хотетть того же при написании сообщений...
код программы легко отличить по, например, отступам (символам \t, четырём и более пробелам подряд в начале строки). Можно вырезать общий для всех строк отступ, это будет весьма удобно...
Автоопределение языка программирования уже на порядки более сложная задача, хотя её вполне можно решить частично для наиболее популярных языков. Главное, чтобы не было false positives...
M>>Я тоже понимаю, что он говорит. Я не понимю, как он прыгает с одного на другое
_R_>Рассказываю: он хочет, что бы было красиво и удобно. Это касается и того и другого, потому и прыгает.
Я тоже хочу красиво и удобно, но это не значит, что на замечание «анализ кода при вставке сделать сложно» надо отвечать «не понимаю, как можно жить без автодополнения», а на вопрос «что за автодополнение» отвечать «ну, при вставке надо обрезать отступы слева, я не о космических технологиях говорю, между прочим»
Все же предполагается, что собеседник будет все же хоть чуточку держать контекст разговора и оформлять свои мысли хоть немного структурировано, не?
Здравствуйте, Mamut, Вы писали:
A>>Вотя буквально на коленке набросал то о чём говорил. Вставляешь из буфера что-топохожее на код и он обрамляется тегом M>Не находишь, что это немножко далеко от, цитирую M>
M>код программы легко отличить по, например, отступам (символам \t, четырём и более пробелам подряд в начале строки). Можно вырезать общий для всех строк отступ, это будет весьма удобно...
Вообще-то это как раз то, о чём я говорил. Вставили исходный код и теги форматирования добавились сами.
Искать и вырезать общий отступ в начале строк я не стал. Не думаю, что наличие строковых функций в JavaScript требует доказательств.
Короче. Мой тезис прост — "умный" редактор с более многословными тегами может быть значительно удобнее примитивного редактора с менее многословными тегами. Ты не согласен? То что вещи о которых я говорю реализуются за разумное время я уже показал. Реализовал две функции. Автоопределения языка тоже не является мегасложной задачей с точки зрения сложности реализации. В каждом языке есть ключевые слова или последовательности ключевых слов, библиотечные функции, которые позволят его идентифицировать. Простой поиск подстрок, которые надо просто разумно выбрать. Ничего лучше и не надо, потому что автоматически определить является ли "var x = y + z" фрагментом на C# или JavaScript не возможно, да и вряд ли нужна специфическая подсветка для такого короткого фрагмента.
A>>>Вотя буквально на коленке набросал то о чём говорил. Вставляешь из буфера что-топохожее на код и он обрамляется тегом M>>Не находишь, что это немножко далеко от, цитирую M>>
M>>код программы легко отличить по, например, отступам (символам \t, четырём и более пробелам подряд в начале строки). Можно вырезать общий для всех строк отступ, это будет весьма удобно...
A>Вообще-то это как раз то, о чём я говорил. Вставили исходный код и теги форматирования добавились сами. A>Искать и вырезать общий отступ в начале строк я не стал. Не думаю, что наличие строковых функций в JavaScript требует доказательств.
A>Короче. Мой тезис прост — "умный" редактор с более многословными тегами может быть значительно удобнее примитивного редактора с менее многословными тегами. Ты не согласен?
Спорно, тем более, что ты этого не показал. Ты вместо разговора предпочел прыгать с одной темы на другую и придумывать за собесденика какие-то тезисы.
Так в чем плюс многословности?
A>То что вещи о которых я говорю реализуются за разумное время я уже показал.
Какие именно? В разговоре со мной ты как минимум о 5 разных вещах. Тут
Здравствуйте, Mamut, Вы писали:
A>>Короче. Мой тезис прост — "умный" редактор с более многословными тегами может быть значительно удобнее примитивного редактора с менее многословными тегами. Ты не согласен? M>Спорно, тем более, что ты этого не показал.
Не понимаю, как это может быть спорно, для человека использующего IDE . Нормальный Intellisence
M>Так в чем плюс многословности?
В уменьшении времени обучения. BBCode во многом повторяет HTML. Понятно, что сейчас [b] транслируется в <strong> потому что так культурнее, но вообще-то был (и есть) такой тег <b>. И синтаксическая аналогия между [img=...]...[/img], [url=...]...[/url], [code=...]...[/code] достаточно очевидна. Человек запомнив как пишется [b] легко экстраполирует своё знание на [i] и [u].
A>>То что вещи о которых я говорю реализуются за разумное время я уже показал.
M>Какие именно? В разговоре со мной ты как минимум о 5 разных вещах. Тут
Ладно, давай их разберём.
M>То у него уже модальные диалоги для ссылок и изображений нужны, то не нужны (и в этом случае почти все существующие форматы подходят под требование).
Ты не понял, что речь шла не о способе ввода информации, именно поэтому я легко отказался от модальных диалогов, а о том что триггером для ввода дополнительной информации — описания к ссылке или изображению, станет распознавание URL.
M> То у него «анализ вставляемого кода», который неожиданно превращается в «автодополнение» (чего???), который неожиданно превращается в «убирание отступов слева»
Уже не правильно. Не анализ кставляемого кода, а анализ вставляемого текста, проверка не является ли исходный текст кодом. Автодополнение (если текст является кодом) тегов форматирования. в примере {code}, но это не принципиально. Важно, что после вставки текста из буфера обмена, если он был идентифицирован как исходный код, вставленный текст автоматически обрамляется тегами форматирования. Что тут такого непонятного?
A>>Автоопределения языка тоже не является мегасложной задачей с точки зрения сложности реализации. M>Да ты что? Точно? Надо будет рассказать об этом highlight.js, а то они, бедняги, определения пишут, релевантность, еще всякую фигню придумывают.
Ну тут ты, мягко говоря, лукавишь. Они ищут код среди текста, а нам уже известно где находится код, надо только уточнить язык. Я опять таки, уже предложил неплохой вариант как.
Здравствуйте, AndrewVK, Вы писали:
C>>[b] — гораздо менее частотная последовательность, чем *.
AVK>Поэтому внутри кода * двойная. Мало? Можно сделать тройную.
Не мало, но глупо. Думаю, ты и сам пошлешь свою идею по дальше, после пары "а черт!..." при копипасте кода.
ЗЫ
работают в коде отлично только потому, что без закрывающего они не обрабатываются. А с ним вероятность появления этого дела в коде стремится к нулю.
ЗЗЫ
Вообще, от добра добра не ищут. Текущий формат вполне удобен. Имеет смысл развивать его, а не выдумывать разную муру. В нем есть явные неудобства. Я бы выделил неудобные заголовки, списки и таблицы. Вот нужно подумать как их упростить. С зоголовками все просто. !!! ли === всех устроит. Со списками тоже не сложно. ## отлично подходя. С таблицами все сложнее, но тоже решаемо.
Что до трудностей ручного написания ББ-тегов, то их никто руками не пишет. На то есть тулбар.
Ну, а для упрощения форматирования имеет смысл делать визивидж-редктор, а не колдовать с форматами.
ЗЗЗЫ
Что касается технической стороны, то это не особой проблемой не является. Мы на этом уже всех собак съели.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Не мало, но глупо. Думаю, ты и сам пошлешь свою идею по дальше, после пары "а черт!..." при копипасте кода.
Ну и? Твои предложения?
VD> работают в коде отлично только потому, что без закрывающего они не обрабатываются.
Я не планировал подобное поведение менять. Скорее наоборот, усложнять, чтобы заодно проверялось соотношение с границами слова.
VD>Вообще, от добра добра не ищут. Текущий формат вполне удобен.
Лично мне — нет. Можешь завести голосование.
VD>Что до трудностей ручного написания ББ-тегов, то их никто руками не пишет. На то есть тулбар.
Потому и не пишет, что жутко неудобно.
VD>Ну, а для упрощения форматирования имеет смысл делать визивидж-редктор, а не колдовать с форматами.
Сделай.
VD>Что касается технической стороны, то это не особой проблемой не является. Мы на этом уже всех собак съели.
Мне как то с ваших собак никакого прибытка. Что ты, что WH для сайта ничего не пишете, только флеймы разводите.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
Z>>Хотелось бы еще возможность указывать язык для однострочников.
AVK>Тогда придется придумать, как понять что это название языка, а не код
например так:
{{{lang:C# if (a > 0) {} else {} }}}
lang можно использовать и в многострочной версии, для единообразия, не так много букв, раскладку все равно переключать.
Здравствуйте, VladD2, Вы писали:
VD>Что до трудностей ручного написания ББ-тегов, то их никто руками не пишет. На то есть тулбар.
Глупости. Зачем отрывать руку от клавиатуры и целиться мышью в кнопку, если можно написать тэг?
VD>Ну, а для упрощения форматирования имеет смысл делать визивидж-редктор, а не колдовать с форматами.
A>>>Короче. Мой тезис прост — "умный" редактор с более многословными тегами может быть значительно удобнее примитивного редактора с менее многословными тегами. Ты не согласен? M>>Спорно, тем более, что ты этого не показал.
A>Не понимаю, как это может быть спорно, для человека использующего IDE . Нормальный Intellisence
При чем тут интеллисенс и IDE к редактору с тэгами, известно только тебе.
M>>Так в чем плюс многословности?
A>В уменьшении времени обучения. BBCode во многом повторяет HTML.
А, ну да. Прям-так все знают и обязаны знать HTML. С точки зрения не-веб-программиста, абсолютно пофиг, как выделять текст — через [b] или там через **. Если текстов надо набирать достаточно много, на первое место выходит удобство, а не теги.
A>>>То что вещи о которых я говорю реализуются за разумное время я уже показал.
M>>Какие именно? В разговоре со мной ты как минимум о 5 разных вещах. Тут
я все сказал по этому поводу.
A>Ладно, давай их разберём.
Неужели! Наконец-то!
M>>То у него уже модальные диалоги для ссылок и изображений нужны, то не нужны (и в этом случае почти все существующие форматы подходят под требование).
A>Ты не понял, что речь шла не о способе ввода информации, именно поэтому я легко отказался от модальных диалогов, а о том что триггером для ввода дополнительной информации — описания к ссылке или изображению, станет распознавание URL.
Каким триггером? Какое распознавание? Ты о чем вообще? Стояла задача: ввести ссылку и описание. ВНЕЗАПНО банальное что-то типа
!http://a/b/c описание!
будет в разы проще и понятнее, чем «триггеры для ввода доп. описания»
M>> То у него «анализ вставляемого кода», который неожиданно превращается в «автодополнение» (чего???), который неожиданно превращается в «убирание отступов слева»
A>Уже не правильно. Не анализ кставляемого кода, а анализ вставляемого текста, проверка не является ли исходный текст кодом.
Не только проверка, что это код. Еще и проверка, на каком языке программирования этот код, да так, чтобы не было ложных срабатываний. Ага-ага. Банальное
{{{ ruby
вставили код
}}}
решает все проблемы с удобством вставки, анализа кода, защитой от ложных срабатываний, расширяемость для люого кода и т.п.
A>Автодополнение (если текст является кодом) тегов форматирования. в примере {code}, но это не принципиально.
Вау. В 10 сообщении ты, наконец, соизволил объяснить, что ты имеешь в виду. Автокомплит не нужен, если мы не будем пользоваться излишне многословными тэгами.
A>Важно, что после вставки текста из буфера обмена, если он был идентифицирован как исходный код, вставленный текст автоматически обрамляется тегами форматирования. Что тут такого непонятного?
Если бы ты структурировал свои мысли и на вопрос «что такое автокомплит» не отвечал «а вот еще отступы убирать», было бы все понятно.
A>>>Автоопределения языка тоже не является мегасложной задачей с точки зрения сложности реализации. M>>Да ты что? Точно? Надо будет рассказать об этом highlight.js, а то они, бедняги, определения пишут, релевантность, еще всякую фигню придумывают.
A>Ну тут ты, мягко говоря, лукавишь. Они ищут код среди текста, а нам уже известно где находится код,
Только внезапно все ровно наоборот. highlight.js точно знает, где находится код и пытается определить, что это за код. А вот с какого перепугу нам известно, где находится код? У нас человек банально делает Ctrl-V. Что в этом вставленном тексте является кодом, а что — нет? Как ты там говорил? "Главное, чтобы не было ложных срабатываний". Ну-ну
A>надо только уточнить язык. Я опять таки, уже предложил неплохой вариант как.
Что в этом варианте неплохого, неизвестно. По Ctrl-V призодит неизвестно, какой текст. Надо его проанализировать, чтобы понять, код ли это, и какая часть из него является одом. Определить, что это за язык. И все — без ложных срабатываний.
А так — дадада, Неплохо вариант. Тлько вот от «если в тексте не дай бог встретится \t или пару пробелов» до «определить, что это код, на каком языке и без ложных срабатываний» — пропасть.
Здравствуйте, Mamut, Вы писали:
M>При чем тут интеллисенс и IDE к редактору с тэгами, известно только тебе.
При том что помошь редактора позволяет даже многословным языкам быть удобными при наборе. Почему тебе каждую мысль надо разжёвывать, а, например, _Raz_ всё сразу понял? Может дело в том, что ты просто немного не в тебе?
A>>В уменьшении времени обучения. BBCode во многом повторяет HTML. M>А, ну да. Прям-так все знают и обязаны знать HTML.
Я уверен, что не менее 90% общающихся тут людей имеют какое-то представление об HTML. В любом случае b, i, u это не с неба свалившиеся буквы, а bold, italics, underline.
M>>>То у него уже модальные диалоги для ссылок и изображений нужны, то не нужны (и в этом случае почти все существующие форматы подходят под требование). A>>Ты не понял, что речь шла не о способе ввода информации, именно поэтому я легко отказался от модальных диалогов, а о том что триггером для ввода дополнительной информации — описания к ссылке или изображению, станет распознавание URL.
M>Каким триггером? Какое распознавание? Ты о чем вообще? Стояла задача: ввести ссылку и описание. ВНЕЗАПНО банальное что-то типа M>
M>!http://a/b/c описание!
M>
M>будет в разы проще и понятнее, чем «триггеры для ввода доп. описания»
Я объяснл достаточно ясно. Твоё непонимание либо лень, либо троллинг.
A>>Уже не правильно. Не анализ кставляемого кода, а анализ вставляемого текста, проверка не является ли исходный текст кодом. M>Не только проверка, что это код. Еще и проверка, на каком языке программирования этот код, да так, чтобы не было ложных срабатываний. Ага-ага. Банальное M>
M>{{{ ruby
M>вставили код
M>}}}
M>
M>решает все проблемы с удобством вставки, анализа кода, защитой от ложных срабатываний, расширяемость для люого кода и т.п.
Вопрос только один, чем это лучше текущего решения? Подскажу правильный ответ — ничем.
M>Вау. В 10 сообщении ты, наконец, соизволил объяснить, что ты имеешь в виду.
Меньше пафоса. Никто кроме тебя вопрос не задал.
M>Автокомплит не нужен, если мы не будем пользоваться излишне многословными тэгами.
Если тебе тег набирать вообще не надо, то уже не важно насколько он многословен.
A>>>>Автоопределения языка тоже не является мегасложной задачей с точки зрения сложности реализации. M>>>Да ты что? Точно? Надо будет рассказать об этом highlight.js, а то они, бедняги, определения пишут, релевантность, еще всякую фигню придумывают. A>>Ну тут ты, мягко говоря, лукавишь. Они ищут код среди текста, а нам уже известно где находится код,
M>Только внезапно все ровно наоборот. highlight.js точно знает, где находится код и пытается определить, что это за код.
На первой странице сайта написано It's very easy to use because it works automatically: finds blocks of code, detects a language, highlights it.
Они врут?
M> У нас человек банально делает Ctrl-V. Что в этом вставленном тексте является кодом, а что — нет?
Это уже демагогия. Как в буфере обмена окажется смесь из кода и текста?
M>Что в этом варианте неплохого, неизвестно. По Ctrl-V призодит неизвестно, какой текст. Надо его проанализировать, чтобы понять, код ли это, и какая часть из него является кодом.
Не усложняй. Это либо целиком код, либо целиком не код.
M>А так — дадада, Неплохо вариант. Тлько вот от «если в тексте не дай бог встретится \t или пару пробелов» до «определить, что это код, на каком языке и без ложных срабатываний» — пропасть.
Не пара пробелов, а четыре подряд в начале строки. Я понимаю что можно скопировать код в notepad, приписать сверху стихи, снизу небольшую повесть, а потом скопировать результат в форму сообщения, но давай не выдавать параноидальные фантазии за реальные сценарии использования.
M>>При чем тут интеллисенс и IDE к редактору с тэгами, известно только тебе.
A>При том что помошь редактора позволяет даже многословным языкам быть удобными при наборе.
Какое отношение это имеет к многословным тэгам? Ровно никакого. Потому что в IDE, ка кни странно, тэгов нет. Там этот, как его, RichEdit/WYSIWIG и прочие радости жизни.
Но да, интеллисенс в IDE показывает преимущество многословных тэгов над короткими, ага. Осталось найти связь между интеллисенсом и многословными тэгами, но это такие мелочи, право.
A>>>В уменьшении времени обучения. BBCode во многом повторяет HTML. M>>А, ну да. Прям-так все знают и обязаны знать HTML.
A>Я уверен, что не менее 90% общающихся тут людей имеют какое-то представление об HTML.
Когда «уверен», креститься надо
A>В любом случае b, i, u это не с неба свалившиеся буквы, а bold, italics, underline.
Ну да, ну да. На форме всегда используется только и исключительно b,i,u. Списки, код, цитаты, изображения? Нет, не слышал. Что-то они вообще не повторяют HTML.
M>>Каким триггером? Какое распознавание? Ты о чем вообще? Стояла задача: ввести ссылку и описание. ВНЕЗАПНО банальное что-то типа M>>
M>>!http://a/b/c описание!
M>>
M>>будет в разы проще и понятнее, чем «триггеры для ввода доп. описания»
A>Я объяснл достаточно ясно. Твоё непонимание либо лень, либо троллинг.
Нет, ты ничего не объяснил. Твое объяснение работает только для модальных диалогов. Объясни мне, как будет работать твой триггер с распознованием для примера, что я привел выше. Когда модального диалога нет, а пользователь уже вбивает ссылку/изображение в текст.
A>>>Уже не правильно. Не анализ кставляемого кода, а анализ вставляемого текста, проверка не является ли исходный текст кодом. M>>Не только проверка, что это код. Еще и проверка, на каком языке программирования этот код, да так, чтобы не было ложных срабатываний. Ага-ага. Банальное M>>
M>>{{{ ruby
M>>вставили код
M>>}}}
M>>
M>>решает все проблемы с удобством вставки, анализа кода, защитой от ложных срабатываний, расширяемость для люого кода и т.п.
A>Вопрос только один, чем это лучше текущего решения? Подскажу правильный ответ — ничем.
Я и не говорю, что оно прямо мега лучше. Не надо придумывать за меня тезисы, которые я не говорю.
Я говорю, что твоя «автопроверка с автоанализом без сложных срабатываний» сложна для реализации, не даст 100% гарантии от сложных срабатываний, включает в себя кучу проблем (как обрабатывать короткий код? как обрабатывать код на схожих языках программирования? как обрабатывать смесь кода и не кода? как расширять?). При том, что показанный мной вариант не имеет таких проблем вообще.
A>>>>>Автоопределения языка тоже не является мегасложной задачей с точки зрения сложности реализации. M>>>>Да ты что? Точно? Надо будет рассказать об этом highlight.js, а то они, бедняги, определения пишут, релевантность, еще всякую фигню придумывают. A>>>Ну тут ты, мягко говоря, лукавишь. Они ищут код среди текста, а нам уже известно где находится код,
M>>Только внезапно все ровно наоборот. highlight.js точно знает, где находится код и пытается определить, что это за код.
A>На первой странице сайта написано It's very easy to use because it works automatically: finds blocks of code, detects a language, highlights it. A>Они врут?
Они ищут тэги <code>, а не произвольный код в тексте на странице. Вопрос про детектирование конкретного языка «без ложных срабатываний» ты благополучно пропустил. Что не удивительно.
M>> У нас человек банально делает Ctrl-V. Что в этом вставленном тексте является кодом, а что — нет? A>Это уже демагогия. Как в буфере обмена окажется смесь из кода и текста?
Ты этот вопрос на полном серьезе задаешь?
M>>Что в этом варианте неплохого, неизвестно. По Ctrl-V призодит неизвестно, какой текст. Надо его проанализировать, чтобы понять, код ли это, и какая часть из него является кодом.
A>Не усложняй. Это либо целиком код, либо целиком не код.
С какого перепугу?
M>>А так — дадада, Неплохо вариант. Тлько вот от «если в тексте не дай бог встретится \t или пару пробелов» до «определить, что это код, на каком языке и без ложных срабатываний» — пропасть.
A>Не пара пробелов, а четыре подряд в начале строки.
А ну да. Гугл со своим требованием «два-три отсупа в начале строки» для Питона пролетает. Потому что только 4 строки, и не меньше.
A>Я понимаю что можно скопировать код в notepad, приписать сверху стихи, снизу небольшую повесть, а потом скопировать результат в форму сообщения, но давай не выдавать параноидальные фантазии за реальные сценарии использования.
Я описываю реальные сценарии, которыми сам пользовался. Скопировать текст, содержащий, в том числе и код, и вставить его в качестве цитаты для подтверждения своих слов, например.
Ну и не забываем
Тлько вот от «если в тексте не дай бог встретится \t или пару пробелов» до «определить, что это код, на каком языке и без ложных срабатываний» — пропасть.
Здравствуйте, Mamut, Вы писали:
A>>При том что помошь редактора позволяет даже многословным языкам быть удобными при наборе. M>Какое отношение это имеет к многословным тэгам? Ровно никакого. Потому что в IDE, ка кни странно, тэгов нет. Там этот, как его, RichEdit/WYSIWIG и прочие радости жизни.
Ты когда последний раз набирал код? HTML, XML, XAML набираются тегами без всякого WYSIWYG, но с помошью редактора.
M>Но да, интеллисенс в IDE показывает преимущество многословных тэгов над короткими, ага. Осталось найти связь между интеллисенсом и многословными тэгами, но это такие мелочи, право.
Конечно же, интеллисенс в IDE не показывает преимущество многословных тэгов над короткими. Я не знаю откуда ты взял эту глупость. Интеллисенс в IDE нивелирует недостатки многословных тэгов перед короткими.
A>>В любом случае b, i, u это не с неба свалившиеся буквы, а bold, italics, underline. M>Ну да, ну да. На форме всегда используется только и исключительно b,i,u. Списки, код, цитаты, изображения? Нет, не слышал. Что-то они вообще не повторяют HTML.
Вообще-то повторяют. Например, теги [img], [q] и [code]. В том то всё и дело, что bbcode на 95% тот же HTML, просто вместо <> используются [[ ].
A>>Я объяснл достаточно ясно. Твоё непонимание либо лень, либо троллинг. M>Нет, ты ничего не объяснил. Твое объяснение работает только для модальных диалогов.
Я объяснил так что поняли все кроме тебя. Любой человек, который хоть раз пользовался снипетами Visual Studio понял бы меня. Удивительно как ты уверен в своей правоте, хотя не знаком с элементарнешими функциями существующих редакторов.
M>Я и не говорю, что оно прямо мега лучше. Не надо придумывать за меня тезисы, которые я не говорю.
Какой смысл предлагать что-то заменить на что-то другое, если оно не лучше?
M>Я говорю, что твоя «автопроверка с автоанализом без сложных срабатываний» сложна для реализации, не даст 100% гарантии от сложных срабатываний, включает в себя кучу проблем (как обрабатывать короткий код? как обрабатывать код на схожих языках программирования? как обрабатывать смесь кода и не кода? как расширять?). При том, что показанный мной вариант не имеет таких проблем вообще.
Ты почему-то считаешь что они друг друга исключают. Это не так.
M>Я описываю реальные сценарии, которыми сам пользовался. Скопировать текст, содержащий, в том числе и код, и вставить его в качестве цитаты для подтверждения своих слов, например.
В таком случае автоматика не сработает и придётся тебе теги писать вручную. А вот для подавляющего большинства менее извращённых пользователей жизнь станет удобнее. О чём ты вообще споришь?
M>Ну и не забываем M>
Тлько вот от «если в тексте не дай бог встретится \t или пару пробелов» до «определить, что это код, на каком языке и без ложных срабатываний» — пропасть.
Для любой эвристики, вообще любой сколько угодно сложной, можно придумать искуственный тест на котором она лажает. Но люди почему-то пользуются эвристиками. Видимо, тебе эта мысль не приходила в голову, но так в среднем удобнее.
Здравствуйте, AndrewVK, Вы писали:
AVK>Ну и? Твои предложения?
Если тебе уж так хочется сделать не BB-формат, то хотя бы взять редко встречаемую комбинацию. ** тоже плохо и __, так как они в коде встречаются во всю. Символ # в коде обычно встречается редко, так как он чаще всего в препроцессоре задействован. Можно взять сочетания #* и ему подобные.
Но я бы забил. BB вполне удобен, на мой взгляд.
VD>> работают в коде отлично только потому, что без закрывающего они не обрабатываются.
AVK>Я не планировал подобное поведение менять. Скорее наоборот, усложнять, чтобы заодно проверялось соотношение с границами слова.
У нас очень важная часть контента — это код. Всякие ** __ и тем более * и _ в словах будут кофликтовать по любому. В С++ частенько называют препроцессорные имена __XYZ__.
Так что эту идею надо сразу в топку выбросить. BB тем и были хороши, что они уникальны.
Пойдут разные вариации на тему *#, &#, ^#...
VD>>Вообще, от добра добра не ищут. Текущий формат вполне удобен.
AVK>Лично мне — нет. Можешь завести голосование.
У меня есть чем заняться. Развлечения мне не нужны. Ты главное старый формат оставь, а том что хочешь делай. Потому как мне приключения не нужны.
VD>>Что до трудностей ручного написания ББ-тегов, то их никто руками не пишет. На то есть тулбар.
AVK>Потому и не пишет, что жутко неудобно.
Сделай шорткаты. Не уж-то это проблема?
VD>>Ну, а для упрощения форматирования имеет смысл делать визивидж-редктор, а не колдовать с форматами.
AVK>Сделай.
Я тебе уже сказал, что не считаю, что в форматировании есть проблема. Но замена шила на мыла особого смысла не имет.
Котрол можно и банально купить. Думаю таких не мало продается.
VD>>Что касается технической стороны, то это не особой проблемой не является. Мы на этом уже всех собак съели.
AVK>Мне как то с ваших собак никакого прибытка. Что ты, что WH для сайта ничего не пишете, только флеймы разводите.
Есть такой моемент. Я вообще вебом почти не занимался. Вот грамматику помочь написать я могу.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
A>>>При том что помошь редактора позволяет даже многословным языкам быть удобными при наборе. M>>Какое отношение это имеет к многословным тэгам? Ровно никакого. Потому что в IDE, ка кни странно, тэгов нет. Там этот, как его, RichEdit/WYSIWIG и прочие радости жизни.
A>Ты когда последний раз набирал код? HTML, XML, XAML набираются тегами без всякого WYSIWYG, но с помошью редактора.
Еще раз повторю. Код в IDE отличается от набора текста в браузере. Чем? Тем что в IDE нет тэгов. Там уже все выделение, раскраска и прочая и прочая сделано за тебя.
Не говоря уже о том, что написание произвольного текста != IDE
M>>Но да, интеллисенс в IDE показывает преимущество многословных тэгов над короткими, ага. Осталось найти связь между интеллисенсом и многословными тэгами, но это такие мелочи, право.
A>Конечно же, интеллисенс в IDE не показывает преимущество многословных тэгов над короткими. Я не знаю откуда ты взял эту глупость. Интеллисенс в IDE нивелирует недостатки многословных тэгов перед короткими.
Интеллисенс не нужен, если тэги удобные и короткие, или если их нет вообще. Намек: в IDE тэги отсутсвуют, как класс.
A>>>В любом случае b, i, u это не с неба свалившиеся буквы, а bold, italics, underline. M>>Ну да, ну да. На форме всегда используется только и исключительно b,i,u. Списки, код, цитаты, изображения? Нет, не слышал. Что-то они вообще не повторяют HTML.
A>Вообще-то повторяют. Например, теги [img], [q] и [code]. В том то всё и дело, что bbcode на 95% тот же HTML, просто вместо <> используются [[ ].
Повторю: не-веб-программисту плевать на HTML. Для него [b]текст[/b] ничем не лучше *текст*, а даже хуже, потому что многословнее, сложнее в наборе и разбивает текст на куски какого-то другого текста. Не говоря о необходимости переключаться между раскладками (ведь ты так внятно и не рассказал, что делать со списками, ссылками, изображениями и т.п.)
Можно сравнить:
Интеллисенс [b ]не нужен[[/b], потому что:
[list]
[*]в IDE нет тэгов
[*]раскраской текст занимается сама IDE
[/list]
Интеллисенс *не нужен*, потому что:
* в IDE __нет__ тэгов
* раскраской текст занимается сама IDE
Но да, но да. Надо придумывать себе сложности, и активно с ними бороться: давайте интеллисенс! давайте эвристику текста! давайте автоматическое определение желаний пользователя! При том, что подавляющее большинство этих героических сражений не нужно просто даром.
A>>>Я объяснл достаточно ясно. Твоё непонимание либо лень, либо троллинг. M>>Нет, ты ничего не объяснил. Твое объяснение работает только для модальных диалогов.
A>Я объяснил так что поняли все кроме тебя.
ты говоришь «можно и так» про некое «позиционирование курсора».
A>Любой человек, который хоть раз пользовался снипетами Visual Studio понял бы меня. Удивительно как ты уверен в своей правоте, хотя не знаком с элементарнешими функциями существующих редакторов.
У ну да. Вместо того, чтобы объяснить, что ты имеешь в виду, надо уже третье сообщение подряд поднимать очи горе и тяжело вздыхать про несовершенство мира.
. Я ее вставляю в текст. Дальше что?
M>>Я и не говорю, что оно прямо мега лучше. Не надо придумывать за меня тезисы, которые я не говорю. A>Какой смысл предлагать что-то заменить на что-то другое, если оно не лучше?
Мне нравится, как ты, рассказывая сказки про то, что ты смотришь на все сразу, цепляешься строго и исключительно к выборочным вещам. Предлагается заменить уже существующую систему тэгов на основе BBCode, многословную и неудобную, на, возможно, другой вариант, который более удобен в использовании. В частности, вариант типа
{{{ lang
code
}}}
в разы удобнее набирать, чем
M>>Я говорю, что твоя «автопроверка с автоанализом без сложных срабатываний» сложна для реализации, не даст 100% гарантии от сложных срабатываний, включает в себя кучу проблем (как обрабатывать короткий код? как обрабатывать код на схожих языках программирования? как обрабатывать смесь кода и не кода? как расширять?). При том, что показанный мной вариант не имеет таких проблем вообще.
A>Ты почему-то считаешь что они друг друга исключают. Это не так.
Кто кого исключает?
M>>Я описываю реальные сценарии, которыми сам пользовался. Скопировать текст, содержащий, в том числе и код, и вставить его в качестве цитаты для подтверждения своих слов, например.
A>В таком случае автоматика не сработает и придётся тебе теги писать вручную. А вот для подавляющего большинства менее извращённых пользователей жизнь станет удобнее. О чём ты вообще споришь?
В чем она станет удобнее? Он станет удобнее только если ты сможешь 100% гарантировать распознавание и провильную проставку тэгов без ложных срабатываний. Пока что ты не смог справиться с этой задачей.
M>>Ну и не забываем M>>
Тлько вот от «если в тексте не дай бог встретится \t или пару пробелов» до «определить, что это код, на каком языке и без ложных срабатываний» — пропасть.
A>Для любой эвристики, вообще любой сколько угодно сложной, можно придумать искуственный тест на котором она лажает.
При чем тут искуственный текст? Вообще-то, отступ в два символа — ниболее распространен именно у питонщиков
A>Но люди почему-то пользуются эвристиками. Видимо, тебе эта мысль не приходила в голову, но так в среднем удобнее.
Эта мысль мне пришла в голову еще в тот момент, когда ты начал рассказывать сказки про «анализ кода с целью выяснения, на каком языке написано, да еще без ложных срабатываний».
Здравствуйте, Centaur, Вы писали:
VD>>Что до трудностей ручного написания ББ-тегов, то их никто руками не пишет. На то есть тулбар.
C>Глупости. Зачем отрывать руку от клавиатуры и целиться мышью в кнопку, если можно написать тэг?
Чтобы не писать тег. Ваш КО. Если очень хочется с клавы, то можно шорткат сделать. В ворде я тупо жму Ctrl+B, если мне нужно жирным выделить что-то.
VD>>Ну, а для упрощения форматирования имеет смысл делать визивидж-редктор, а не колдовать с форматами.
C>WYSIWYG — давить.
Фанатики идут в лес.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Mamut, Вы писали:
A>>Ты когда последний раз набирал код? HTML, XML, XAML набираются тегами без всякого WYSIWYG, но с помошью редактора. M>Еще раз повторю. Код в IDE отличается от набора текста в браузере. Чем? Тем что в IDE нет тэгов. Там уже все выделение, раскраска и прочая и прочая сделано за тебя. M>Не говоря уже о том, что написание произвольного текста != IDE
А чем, очень интересно, написание сообщения с bb-code принципиально отличается от написания HTML кода?
A>>Конечно же, интеллисенс в IDE не показывает преимущество многословных тэгов над короткими. Я не знаю откуда ты взял эту глупость. Интеллисенс в IDE нивелирует недостатки многословных тэгов перед короткими. M>Интеллисенс не нужен, если тэги удобные и короткие, или если их нет вообще. Намек: в IDE тэги отсутсвуют, как класс.
Намёк, они присутсвуют в куче языков разметки, тексты на которых редактируются в IDE. В HTML, XML, XAML теги есть. Зачем ты оспариваешь очевидную правду?
M>Повторю: не-веб-программисту плевать на HTML. Для него [b]текст[/b] ничем не лучше *текст*, а даже хуже, потому что многословнее, сложнее в наборе и разбивает текст на куски какого-то другого текста. Не говоря о необходимости переключаться между раскладками (ведь ты так внятно и не рассказал, что делать со списками, ссылками, изображениями и т.п.)
Во-первых, предположение что с HTML знакомы только веб программисты не верно. Во-вторых, символ * создаёт проблемы, потому что часто встречается в исходных кодах. Надо, как минимум, **. // предлагавшийся мной изначально по дурости как маркер курсива является началом однострочного комментария. bb-code хорош тем, что не создаёт конфликтов. По этому параметру он пока выигрывает.
A>>Любой человек, который хоть раз пользовался снипетами Visual Studio понял бы меня. Удивительно как ты уверен в своей правоте, хотя не знаком с элементарнешими функциями существующих редакторов. M>У ну да. Вместо того, чтобы объяснить, что ты имеешь в виду, надо уже третье сообщение подряд поднимать очи горе и тяжело вздыхать про несовершенство мира. M>Итак, дано. Есть ссылка типа http://rsdn.ru/forum/rsdn/4866056.1.aspx
Я просто не думал, что придётся с нуля объяснять как работают снипеты. Набери в редакторе C# текст "#region", нажми Tab, введи текст. Проще увидеть.
A>>Ты почему-то считаешь что они друг друга исключают. Это не так. M>Кто кого исключает?
Ручное написание тегов и их автоматическая вставка не исключают друг друга.
M>>>Я описываю реальные сценарии, которыми сам пользовался. Скопировать текст, содержащий, в том числе и код, и вставить его в качестве цитаты для подтверждения своих слов, например. A>>В таком случае автоматика не сработает и придётся тебе теги писать вручную. А вот для подавляющего большинства менее извращённых пользователей жизнь станет удобнее. О чём ты вообще споришь? M>В чем она станет удобнее? Он станет удобнее только если ты сможешь 100% гарантировать распознавание и провильную проставку тэгов без ложных срабатываний. Пока что ты не смог справиться с этой задачей.
Ты не прав.
A>>Для любой эвристики, вообще любой сколько угодно сложной, можно придумать искуственный тест на котором она лажает. M>При чем тут искуственный текст? Вообще-то, отступ в два символа — ниболее распространен именно у питонщиков
И в чём проблема? Возьми реальный кусок кода на питоне который имеет смысл куда-то вставлять и подумай встречается там 4 пробела подряд или нет.
SO>Посмотрим через пару дней на результаты
По состоянию на 24 августа 17:34 — из 33 ответивших 20 по большому счёту с вики-синтаксисом не сталкивались. Мне казалось с работой (и синтаксисом) вики знакомо чуть большее количество людей.
Подождем ещё несколько дней, поднаберётся статистика, тогда можно будет интерпретировать результаты.
M>>Не говоря уже о том, что написание произвольного текста != IDE A>А чем, очень интересно, написание сообщения с bb-code принципиально отличается от написания HTML кода?
То есть IDE существуют только и исключительно для HTML-кода, или ты из всех IDE решил взять в качестве примера только IDE для HTML?
A>>>Конечно же, интеллисенс в IDE не показывает преимущество многословных тэгов над короткими. Я не знаю откуда ты взял эту глупость. Интеллисенс в IDE нивелирует недостатки многословных тэгов перед короткими. M>>Интеллисенс не нужен, если тэги удобные и короткие, или если их нет вообще. Намек: в IDE тэги отсутсвуют, как класс.
A>Намёк, они присутсвуют в куче языков разметки, тексты на которых редактируются в IDE. В HTML, XML, XAML теги есть. Зачем ты оспариваешь очевидную правду?
Где я оспариваю? Я говорю прописные истины:
— написание произвольного текста != написание кода
— интеллисенс не нужен, если тэги короткие
A>Во-первых, предположение что с HTML знакомы только веб программисты не верно. Во-вторых, символ * создаёт проблемы, потому что часто встречается в исходных кодах. Надо, как минимум, **. // предлагавшийся мной изначально по дурости как маркер курсива является началом однострочного комментария. bb-code хорош тем, что не создаёт конфликтов. По этому параметру он пока выигрывает.
Это все упирается только в парсер. Например, «не создающий проблемы bbcode» на RSDN не позволяет написать [[b] внутри тэга [code], заменяя его на <b>.
Но да, но да, ты что проблем у BBCode нет, ага
A>>>Любой человек, который хоть раз пользовался снипетами Visual Studio понял бы меня. Удивительно как ты уверен в своей правоте, хотя не знаком с элементарнешими функциями существующих редакторов. M>>У ну да. Вместо того, чтобы объяснить, что ты имеешь в виду, надо уже третье сообщение подряд поднимать очи горе и тяжело вздыхать про несовершенство мира. M>>Итак, дано. Есть ссылка типа http://rsdn.ru/forum/rsdn/4866056.1.aspx
. Я ее вставляю в текст. Дальше что?
A>Я просто не думал, что придётся с нуля объяснять как работают снипеты. Набери в редакторе C# текст "#region", нажми Tab, введи текст. Проще увидеть.
Сейчас, только вот снесу МакОСь, поставлю Винду, на нее поставлю Visaul Studio, а потом в нем буду разбираться со сниппетами.
Показательно, что на протяжение уже, наверное, десятка сообщений ты так и не смог описать, что ты хочешь, в случае, если модальный диалог отсутствует.
A>>>Ты почему-то считаешь что они друг друга исключают. Это не так. M>>Кто кого исключает?
A>Ручное написание тегов и их автоматическая вставка не исключают друг друга.
Я нигде не пишу, что они друг друга исключают Я пишу, что ты выдумываешь какие-то проблемы и активно начинаешь с ними бороться. При том, что проблемы не существует. Вообще.
M>>В чем она станет удобнее? Он станет удобнее только если ты сможешь 100% гарантировать распознавание и провильную проставку тэгов без ложных срабатываний. Пока что ты не смог справиться с этой задачей.
A>Ты не прав.
Уровень аргументации мне нравится, ага.
A>>>Для любой эвристики, вообще любой сколько угодно сложной, можно придумать искуственный тест на котором она лажает. M>>При чем тут искуственный текст? Вообще-то, отступ в два символа — ниболее распространен именно у питонщиков
A>И в чём проблема? Возьми реальный кусок кода на питоне который имеет смысл куда-то вставлять и подумай встречается там 4 пробела подряд или нет.
Я тебя удивлю, но 4 пробела могут и будут встречаться не только на Питоне.
, например, может легко не встретиться. Не забудь, тебе еще надо определить, что это именно код, определить, на каком языке программирования этот код, и иметь 0% ложных срабатываний.
Здравствуйте, Mamut, Вы писали:
M>Где я оспариваю? Я говорю прописные истины: M>- написание произвольного текста != написание кода M>- интеллисенс не нужен, если тэги короткие
Я категорически не согласен с выделенным.
M>Это все упирается только в парсер. Например, «не создающий проблемы bbcode» на RSDN не позволяет написать [[b] внутри тэга [code], заменяя его на <b>. M>Но да, но да, ты что проблем у BBCode нет, ага
Проблемы есть у всех, речь о том где их меньше.
A>>Я просто не думал, что придётся с нуля объяснять как работают снипеты. Набери в редакторе C# текст "#region", нажми Tab, введи текст. Проще увидеть. M>Сейчас, только вот снесу МакОСь, поставлю Винду, на нее поставлю Visaul Studio, а потом в нем буду разбираться со сниппетами.
Ну то есть ты просто не знаком с тем как работает самая популярная в мире IDE, а виноват я?
M>Показательно, что на протяжение уже, наверное, десятка сообщений ты так и не смог описать, что ты хочешь, в случае, если модальный диалог отсутствует.
Мне казалось странным объяснять элементарщину. Поведение достаточно очевидно, после набора или вставки (не важно) URL (окончание набора можно обозначить пробелом или пунктуацией) он обрамляется соответствующим тегом, а курсор перемещается на описание. То есть, если показать в хронологии. | — курсор.
Ещё раз, это не что-то новое. То что лично ты не знаком с таким поведением редактора кода является лично твоей плохой информированностью.
A>>Ручное написание тегов и их автоматическая вставка не исключают друг друга. M>Я нигде не пишу, что они друг друга исключают Я пишу, что ты выдумываешь какие-то проблемы и активно начинаешь с ними бороться. При том, что проблемы не существует. Вообще.
Ну после того как стало ясно что ты пишешь на ObjC твоя любовь к многословию уже не так удивляет
A>>И в чём проблема? Возьми реальный кусок кода на питоне который имеет смысл куда-то вставлять и подумай встречается там 4 пробела подряд или нет. M>Я тебя удивлю, но 4 пробела могут и будут встречаться не только на Питоне.
, например, может легко не встретиться. Не забудь, тебе еще надо определить, что это именно код, определить, на каком языке программирования этот код, и иметь 0% ложных срабатываний.
Ты не понимаешь как решается задача и только поэтому она кажется тебе сложной.
Здравствуйте, VladD2, Вы писали:
VD>Если тебе уж так хочется сделать не BB-формат, то хотя бы взять редко встречаемую комбинацию. ** тоже плохо и __, так как они в коде встречаются во всю.
Код форматируется отдельно, и внутри кода работает только и исключительно выделение болдом. Поэтому притензии по поводу __ не релевантны.
VD> Символ # в коде обычно встречается редко
Вот только он на русской раскладке тоже отсутствует. Что для болда как наиболее часто используемого форматирования однозначный show stopper.
VD>У нас очень важная часть контента — это код.
Еще раз — внутри кода допустимо только одно форматирование — выделение болдом.
VD>>>Что до трудностей ручного написания ББ-тегов, то их никто руками не пишет. На то есть тулбар. AVK>>Потому и не пишет, что жутко неудобно. VD>Сделай шорткаты. Не уж-то это проблема?
Отличный подход к разработке синтаксиса.
AVK>>Сделай. VD>Я тебе уже сказал, что не считаю, что в форматировании есть проблема.
Ну мало ли что ты не считаешь.
VD>Котрол можно и банально купить. Думаю таких не мало продается.
Ну так купи.
VD>>>Что касается технической стороны, то это не особой проблемой не является. Мы на этом уже всех собак съели. AVK>>Мне как то с ваших собак никакого прибытка. Что ты, что WH для сайта ничего не пишете, только флеймы разводите. VD>Есть такой моемент. Я вообще вебом почти не занимался. Вот грамматику помочь написать я могу.
Сперва надо понять, грамматику чего надо писать.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Господа, предлагаю вашу энергию направить в мирное русло. Вопрос поддержки редактора сейчас не стоит. И, думаю, никто из вас не будет спорить, что вне зависимости от наличия хитрого редактора, понятный и удобный синтаксис очень важен. Поэтому стоит на синтаксисе и сосредоточится. А потом уж обсуждать, как докрутить редактор в вебе.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Код форматируется отдельно, и внутри кода работает только и исключительно выделение болдом. Поэтому притензии по поводу __ не релевантны.
ififif
Отказываемся от имеющейся функциональности? Или ты просто забыл что у нас поддерживается?
Потом удвоение звездочек в коде — это самый главный прикол. Хуже уже что-то придумать сложно.
VD>> Символ # в коде обычно встречается редко
AVK>Вот только он на русской раскладке тоже отсутствует.
Ну, да выделяя в коде фрагменты переключение на английский неприемлемо. Зато удаивать (а чё только уваивать?) звездочки удобно будет .
AVK>Что для болда как наиболее часто используемого форматирования однозначный show stopper.
Ты оторвался от реальности.
VD>>У нас очень важная часть контента — это код.
AVK>Еще раз — внутри кода допустимо только одно форматирование — выделение болдом.
Звездочкой?
Ну, и еще раз спрашиваю — даунгрэйтим функциональность?
VD>>Сделай шорткаты. Не уж-то это проблема?
AVK>Отличный подход к разработке синтаксиса.
Я не предлагал менять синтаксис. Кому вообще, кроме тебя нужно менять синтаксис? Ты хоть у посетителей для начала просил бы нужно ли им это.
AVK>>>Сделай. VD>>Я тебе уже сказал, что не считаю, что в форматировании есть проблема.
AVK>Ну мало ли что ты не считаешь.
Ага. Не мало. Не меньше чем ты, по крайней мере.
VD>>Котрол можно и банально купить. Думаю таких не мало продается.
AVK>Ну так купи.
Ну, так выбирай, которую. Мне не жалко.
AVK>Сперва надо понять, грамматику чего надо писать.
Вот это мне по фиг. Но если у меня спросить, то я бы для начала предложил бы реализовать то что есть. Идея ломки мира до основания, с последующей постройкой нового уже не раз проваливалась на практике.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Отказываемся от имеющейся функциональности?
Да. Она не используется реально.
VD> Или ты просто забыл что у нас поддерживается?
Учитыва, кто форматтер последние лет много правит — очень смешно.
VD>Потом удвоение звездочек в коде — это самый главный прикол. Хуже уже что-то придумать сложно.
Придумай лучше.
AVK>>Вот только он на русской раскладке тоже отсутствует.
VD>Ну, да выделяя в коде фрагменты переключение на английский неприемлемо
Почему только в коде? Или ты предлагаешь в тексте * выделять, а в коде #?
VD>Кому вообще, кроме тебя нужно менять синтаксис?
Да никомцу не нужно. Тут в топике почти все аккаунты — мои.
AVK>>Сперва надо понять, грамматику чего надо писать. VD>Вот это мне по фиг. Но если у меня спросить, то я бы для начала предложил бы реализовать то что есть.
Предлагать мы тут все умеем. А по факту — кто реально реализует, тот и прав.
VD> Идея ломки мира до основания, с последующей постройкой нового уже не раз проваливалась на практике.
Зато идея нифига не делать и критиковать — работает, да?
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, VladD2, Вы писали: VD>>Не мало, но глупо. Думаю, ты и сам пошлешь свою идею по дальше, после пары "а черт!..." при копипасте кода. AVK>Ну и? Твои предложения?
Внутри кода лучше использовать тэги — т.е. достаточно длинную, гарантированно редко встречающуюся последовательность. (**) — это весьма распространенный оператор. Да и в языках, где можно описывать свои операторы, комбинация может получиться любая. Операторы вида [b] мне неизвестны — особенно в аутфиксной форме.
Вообще здесь улучшением была бы не другая разметка, а возможность другого выделения. Болд как правило слабо заметен. А иногда нужно выделить участки кода. Для этого больше подошла бы подсветка фона типа highlight.
Здравствуйте, VladD2, Вы писали:
VD>Если тебе уж так хочется сделать не BB-формат, то хотя бы взять редко встречаемую комбинацию. ** тоже плохо и __, так как они в коде встречаются во всю. Символ # в коде обычно встречается редко, так как он чаще всего в препроцессоре задействован. Можно взять сочетания #* и ему подобные.
Я все поскипаю, потому что мы говорим об абсолютно разных вещах. В ачстности, ты упорно борешься со следствием, отказываясь лечить причину.
Итак, мы говорим не о программировании, мы говорим о написании текста. Неструктурированного произвольного текста. Для такого текста единственным удобным способом написания является собственно написание текста без дополнительных элементов. В простейшем варианте — это вообще неоотформатированный текст (notepad/nano/vim/etc...) или RichEdit/WYSIWIG (Wordpa/Word/Pages/etc.).
Если бы для веба имелся в наличии вменяемый второй вариант (richedit), то нашего разговора не было бы. Вставил контрол на страницу и рисуй себе оранжевое небо и оранжевый утюг, то есть форматируй себе текст так, как тебе угодно, какими угодно способами, без внесения в текст доп. элементов. К сожалению, таких контролов для веба нет, и они создают намного больше проблем, чем они решают.
Остается другая крайность — неотформатированный текст. В который надо вставлять какие-то метки, чтобы сайт смог отобразить этот текст, как отформатированный. Способов расставлять такие метки — миллион и маленькая тележка, и можно придумать еще больше.
Но надо, чтобы было удобно.
Ошибка — считать, что удобно — это когда удобно технической составляющей — парсеру/рендереру.
Ошибка — считать, что удобно — это соответствие каким-то техническим правилам/знаниям (ой, это соответствует HTML'ю, ой, это соответсвует Latex'у, ой, это соответсвует еще чему-то).
Единственный критерий удобства — это «насколько удобно набирать текст и расставлять эти метки». Все. Если для того, чтобы создать удобство, надо включать эвристику, сниппеты, автодополнения и т.п. только для того, чтобы набрать текст, то явно выбран плохой вариант разметки текста. Я ведь уже приводил пример:
Интеллисенс [b]не нужен[/b], потому что:
[list]
[*]в IDE нет тэгов
[*]раскраской текст занимается сама IDE
[/list]
Интеллисенс *не нужен*, потому что:
* в IDE __нет__ тэгов
* раскраской текст занимается сама IDE
Если в первом случае надо постоянно переключаться из раскладки в раскладку, а для обеспечения удобства ввода ндо полагаться полагаться на автокомплит и сниппеты, то во втором можно обойтись и без переключения раскладок, и без автокомплита, и без сниппетов, при этом ничего не потеряв в удобстве набора (или даже выиграв).
То есть в первом случае у тебя есть явная проблема: многословность тэгов и неудобство их набора. Вместо того, чтобы решить эту проблему, ты предлагаешь решать следствия, вызванные этой проблемой: а давайте автокомплит, а давайте сниппеты, а давайте эвристику, а давайте шорткаты, а давайте еще что-то.
При том, что эти последствия можно уменьшить или убрать банальной заменой синтаксиса, а некоторые из предложенных решений (типа шорткатов) можно оставить, как действительно средство, повышающее уже существующее удобство набора текста.
AVK>Господа, предлагаю вашу энергию направить в мирное русло. Вопрос поддержки редактора сейчас не стоит. И, думаю, никто из вас не будет спорить, что вне зависимости от наличия хитрого редактора, понятный и удобный синтаксис очень важен. Поэтому стоит на синтаксисе и сосредоточится. А потом уж обсуждать, как докрутить редактор в вебе.
Ну, если выбрать максимально удобный синтаксис, то редактор может быть дико примитивным
На самом деле, мне по синтаксису практически нечего добавить. Многолетняя борьба с разными вики, маркдаунами и текстилями сделала меня имунным к любым извращениям И мне пока очень нравится те варианты, что ты уже предлагаешь в вики форматтера (это можно видеть по оценкам «спасибо», что я ставлю)
Пока что единственным камнем преткновения являестя * в коде, но имхо, тут достаточно обсудить/решить, что в блоках кода парсер переключается в другой режим, в котором * не является меткой полужирного текста, и обсудить, как решать
ВВ>Вообще здесь улучшением была бы не другая разметка, а возможность другого выделения. Болд как правило слабо заметен. А иногда нужно выделить участки кода. Для этого больше подошла бы подсветка фона типа highlight.
Здравствуйте, Mamut, Вы писали:
M>Если в первом случае надо постоянно переключаться из раскладки в раскладку, а для обеспечения удобства ввода ндо полагаться полагаться на автокомплит и сниппеты, то во втором можно обойтись и без переключения раскладок, и без автокомплита, и без сниппетов, при этом ничего не потеряв в удобстве набора (или даже выиграв).
Ты уже предлагаешь отказаться от форматирования внутри блоков кода (не так чтоб очень надо было, просто отмечаю начало плохой тенденции). Потом само понятие удобства набора достаточно расплывчато. Те кто действительно быстро печатают не будут обращать внимание на длину тегов. Для меня удобство, это отсутсвие необходимости запоминать кучу закорючек. Мне надо разгрузить мозги, а не пальцы.
M>То есть в первом случае у тебя есть явная проблема: многословность тэгов и неудобство их набора. Вместо того, чтобы решить эту проблему, ты предлагаешь решать следствия, вызванные этой проблемой: а давайте автокомплит, а давайте сниппеты, а давайте эвристику, а давайте шорткаты, а давайте еще что-то.
То есть поступаю так же как поступают со многими другими искуственными языками. Тебе не кажется что ты сейчас напоминаешь борцов с синтаксическим оверхедом?
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, ShaggyOwl, Вы писали:
SO>>А как предполагается осуществлять внедрение нового движка?
AVK>Видимо, флажок в БД и сразу два форматтера параллельно на первое время. И возможность выбрать разметку при написании сообщения. А дальше по статистике — если старым форматтером будет мало народу пользоваться, то выкинуть возможность использования и, в перспективе, сконвертировать старые сообщения в новый формат.
Тогда будет проблема с цитированием при ответах — либо ты используешь тот же форматтер, что и автор исходного сообщения, либо конвертируешь всё в свой любимый синтаксис вручную.
Здравствуйте, RomikT, Вы писали:
RT>Тогда будет проблема с цитированием при ответах — либо ты используешь тот же форматтер, что и автор исходного сообщения, либо конвертируешь всё в свой любимый синтаксис вручную.
Ну да.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, adontz, Вы писали:
A>Ты уже предлагаешь отказаться от форматирования внутри блоков кода
Это де-факто общепринятая ситуация. Да и текущий форматтер позволяет использовать очень ограниченное количество тегов внутри кода. Ну и пользуются всем этим внутрикодовым форматированием весьма редко и с одной целью — выделить какой то кусочек кода. Как правильно заметил ВВ, семантика вообще не предполагает форматирование текста внутри кода, она только требует наличия средства выделения. И смена фона для этого даже лучше, чем болд. Вот и надо думать в сторону того, как это выделение (и ничего больше) внутри кода обозначать. Если б не дурацкие плюсовые переопределения операторов, можно было бы использовать >>>код<<<.
A>Те кто действительно быстро печатают не будут обращать внимание на длину тегов.
1) Это утверждение нуждается в доказательстве
2) Те кто быстро печатают — они очень не любят переключать часто раскладку.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
M>>Если в первом случае надо постоянно переключаться из раскладки в раскладку, а для обеспечения удобства ввода ндо полагаться полагаться на автокомплит и сниппеты, то во втором можно обойтись и без переключения раскладок, и без автокомплита, и без сниппетов, при этом ничего не потеряв в удобстве набора (или даже выиграв).
A>Ты уже предлагаешь отказаться от форматирования внутри блоков кода (не так чтоб очень надо было, просто отмечаю начало плохой тенденции).
Где я внезапно от этого отказываюсь?
A>Потом само понятие удобства набора достаточно расплывчато. Те кто действительно быстро печатают не будут обращать внимание на длину тегов. Для меня удобство, это отсутсвие необходимости запоминать кучу закорючек. Мне надо разгрузить мозги, а не пальцы.
То есть ты считаешь, что постоянное преключение раскладки, необходимость дважды писать одно и то же, и постоянное использование [/] — это удобно? Ну-ну.
M>>То есть в первом случае у тебя есть явная проблема: многословность тэгов и неудобство их набора. Вместо того, чтобы решить эту проблему, ты предлагаешь решать следствия, вызванные этой проблемой: а давайте автокомплит, а давайте сниппеты, а давайте эвристику, а давайте шорткаты, а давайте еще что-то.
A>То есть поступаю так же как поступают со многими другими искуственными языками. Тебе не кажется что ты сейчас напоминаешь борцов с синтаксическим оверхедом?
Нет, не кажется. Я просто указываю тебе на то, что ты борешься не с причиной, а со следсвием. Убери многословные, неудобные, дублирующиеся на ровном месте тэги, и тебе не надо будет ломать голову над тем, как эту всю гадость сделать так, чтобы было удобно набирать.
Здравствуйте, Mamut, Вы писали:
A>>Ты уже предлагаешь отказаться от форматирования внутри блоков кода (не так чтоб очень надо было, просто отмечаю начало плохой тенденции). M>Где я внезапно от этого отказываюсь?
Ну потому что ** и // встречаются в коде и их использовать нельзя.
A>>Потом само понятие удобства набора достаточно расплывчато. Те кто действительно быстро печатают не будут обращать внимание на длину тегов. Для меня удобство, это отсутсвие необходимости запоминать кучу закорючек. Мне надо разгрузить мозги, а не пальцы. M>То есть ты считаешь, что постоянное преключение раскладки, необходимость дважды писать одно и то же, и постоянное использование [/] — это удобно? Ну-ну.
Это не удобно. Но какой смысл в коротких тегах, которые не помнишь? Набрать [img=] может и сложно, но легко запомнить. А вот что из следующего картинка, а что ссылка [url|text]] ![url|text]]? Что дольше, набрать длинный код и подсмотреть короткий?
A>>То есть поступаю так же как поступают со многими другими искуственными языками. Тебе не кажется что ты сейчас напоминаешь борцов с синтаксическим оверхедом? M>Нет, не кажется. Я просто указываю тебе на то, что ты борешься не с причиной, а со следсвием. Убери многословные, неудобные, дублирующиеся на ровном месте тэги, и тебе не надо будет ломать голову над тем, как эту всю гадость сделать так, чтобы было удобно набирать.
На замену, пока что, предлагаются теги которые не запомнить. Как можно быстро пользоваться тем, что нельзя запомнить?
Здравствуйте, adontz, Вы писали:
A>Ну потому что ** и // встречаются в коде и их использовать нельзя.
Я правильно понимаю, что ради выделения болдом и италиком внутри кода ты готов пожертвовать удобством написания всего остального текста?
A>Это не удобно. Но какой смысл в коротких тегах, которые не помнишь?
А какой смысл в длинных тегах, которые не помнишь? Я вот сравнительно долго не помнил почти никаких тегов. Но подсказка внизу есть.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Вот и надо думать в сторону того, как это выделение (и ничего больше) внутри кода обозначать. Если б не дурацкие плюсовые переопределения операторов, можно было бы использовать >>>код<<<.
ИМХО не надо для выделений внутри кода использовать только операторные символы. Потому что (<<<) — это один токен. А [b] — это три токена. Даже если пара [b] [/b] оказывается валидным кодом на каком-нибудь языке (что вполне возможно), то это не такая уж и проблема — достаточно пробел вставить: [ b] [/b]. И все. Код по-прежнему валидный, а подсветки нет. А вот с операторами такое не прокатит.
К тому же и выбрать сложно. (<<<) и (>>>) — это, кстати, операторы битового сдвига в F# и композиции функций в Хаскелле (Категория).
Так что для выделения внутри кода — независимо от того, что используется для выделения в обычном тексте — лучше использовать все-таки обычные теги. То, что их набирать дольше не такая проблема — не в каждом сообщении это требуется.
Здравствуйте, AndrewVK, Вы писали:
A>>Ну потому что ** и // встречаются в коде и их использовать нельзя. AVK>Я правильно понимаю, что ради выделения болдом и италиком внутри кода ты готов пожертвовать удобством написания всего остального текста?
Меня, если честно, больше волнует зачёркивание.
A>>Это не удобно. Но какой смысл в коротких тегах, которые не помнишь? AVK>А какой смысл в длинных тегах, которые не помнишь? Я вот сравнительно долго не помнил почти никаких тегов. Но подсказка внизу есть.
Интересно как эта подсказка будет выглядеть с новыми тегами. Ведь сейчас там не текстовое описание, а сам тег. Как запомнить что __ это подчёркивание, а ___ это нижний индекс?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>К тому же и выбрать сложно. (<<<) и (>>>) — это, кстати, операторы битового сдвига в F# и композиции функций в Хаскелле (Категория).
Можно отсечь операторы от форматирования по такому признаку — в случае форматирования у >>> всегда слева пробел или начало строки, а справа символ, у <<< наоборот. Все остальное трактуется как текст.
ВВ>Так что для выделения внутри кода — независимо от того, что используется для выделения в обычном тексте — лучше использовать все-таки обычные теги.
Множественное число тут лишнее. Нужен ровно один способ выделения.
ВВ> То, что их набирать дольше не такая проблема — не в каждом сообщении это требуется.
Согласен.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, adontz, Вы писали:
AVK>>А какой смысл в длинных тегах, которые не помнишь? Я вот сравнительно долго не помнил почти никаких тегов. Но подсказка внизу есть.
A>Интересно как эта подсказка будет выглядеть с новыми тегами.
Никогда не видел короткие справки по разметке? Вот пример с кодплекса:
WIKI MARKUP GUIDE
*bold*
_italics_
+underline+
! Heading 1
!! Heading 2
* Bullet List
** Bullet List 2
# Number List
## Number List 2
[another wiki page]
[url:http://www.example.com]
[file:example.txt]
[image:example.gif]
{"Do not apply formatting"}
Full Markup Guide
A> Ведь сейчас там не текстовое описание, а сам тег. Как запомнить что __ это подчёркивание, а ___ это нижний индекс?
Как человек, регулярно пользующийся траком, могу тебе сказать — никаких проблем, не сложнее чем запомнить текущую разметку.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
ВВ>>К тому же и выбрать сложно. (<<<) и (>>>) — это, кстати, операторы битового сдвига в F# и композиции функций в Хаскелле (Категория). AVK>Можно отсечь операторы от форматирования по такому признаку — в случае форматирования у >>> всегда слева пробел или начало строки, а справа символ, у <<< наоборот. Все остальное трактуется как текст.
Т.е. вот так оно не будет выделять:
>>> x + 1<<<
а вот так будет:
>>>x + 1<<<
Как-то это не очень интуитивно
Использовать BB тэг тут, мне кажется, все же проще. Правила интуитивно-понятны, инструкции по использованию писать не надо. К тому же это способ проверенный.
A>>>Ты уже предлагаешь отказаться от форматирования внутри блоков кода (не так чтоб очень надо было, просто отмечаю начало плохой тенденции). M>>Где я внезапно от этого отказываюсь?
A>Ну потому что ** и // встречаются в коде и их использовать нельзя.
Все можно Главное, придумать, как
M>>То есть ты считаешь, что постоянное преключение раскладки, необходимость дважды писать одно и то же, и постоянное использование [/] — это удобно? Ну-ну.
A>Это не удобно.
Именно. Хотя сообщениями выше ты утверждаешь, что длинные тэги/bbcode — это удобно
A>Но какой смысл в коротких тегах, которые не помнишь? Набрать [img=] может и сложно, но легко запомнить. А вот что из следующего картинка, а что ссылка [url|text]] ![url|text]]? Что дольше, набрать длинный код и подсмотреть короткий?
Дольше — набрать длинный код. Подсказка обычно занимает строчек 10 рядом с полем редактирования. Кстати, насчет img. Ты ошибся. Тэг img набирается не так. Это к вопросу о запоминаемости и «соответствию HTML».
A>>>То есть поступаю так же как поступают со многими другими искуственными языками. Тебе не кажется что ты сейчас напоминаешь борцов с синтаксическим оверхедом? M>>Нет, не кажется. Я просто указываю тебе на то, что ты борешься не с причиной, а со следсвием. Убери многословные, неудобные, дублирующиеся на ровном месте тэги, и тебе не надо будет ломать голову над тем, как эту всю гадость сделать так, чтобы было удобно набирать.
A>На замену, пока что, предлагаются теги которые не запомнить. Как можно быстро пользоваться тем, что нельзя запомнить?
Не запомнить? Ты издеваешься? Тут большинство хоть раз пользовалось или гитхабом или StackOverflow. Прикинь, что там, что там нет, наверное, ни одного пользователя, который хотел бы bbcode. Несмотря на «незапоминающиеся» Markdown (GitHub и Stackoverflow) или ReStructured text/Orgmode/Textile/хзчтоеще (GitHub).
Здравствуйте, VladD2, Вы писали:
VD>Всмысле сведение нового оператора? Ну это уже реально редко будет встречаться.
Ну решеточку можно как операторный символ в ряде языков использовать. Например, в Хаскелле.
Ну и пользовательские операторы я бы не сказал, что так уж редко встречаются.
VD>В прочем можно и другое сочетание придумать. VD>ЗЫ VD>Идея прикуривая шорткатов к BB-телам мне нравится все больше и больше.
Не знаю, как с точки зрения обратной совместимости и прочих вещей, но набирать текст с использованием вики-стайл разметки все же быстрее и проще.
Здравствуйте, AndrewVK, Вы писали:
SO>>1. **(жирный), // (наклонный), -- (перечёркнутый), ^^ (верхний индекс), __ (нижний индекс)
AVK>Поправка. Двойная __ — подчеркивание, тройная ___ — нижний индекс.
Ок.
AVK>Для унификации тогда уж лучше AVK>{{cpp{ AVK> ... AVK>}}}
+1
AVK>Еще для блочного кода надо добавить синтаксис указания, что код надо показать в свернутом блоке:
+1
AVK>Забыли, кстати, про [cut].
Мм.. А что это?
Здравствуйте, AndrewVK, Вы писали:
AVK>Что именно тебя интересует?
Сейчас составили черновой вариант спецификации. Далее (например) выждали недельку, собрали все пожелания, зафиксировали спецификацию. Конечная же цель — появление на сайте нового форматтера.
Интересуют дальнейшие шаги по направлению к цели. Если точнее — чем ещё я могу помочь?
Здравствуйте, ShaggyOwl, Вы писали:
SO>Интересуют дальнейшие шаги по направлению к цели. Если точнее — чем ещё я могу помочь?
Дальнейший шаг очевиден — надо сделать прототип реализации парсера. Если тебя эта задача не пугает и дотнет не запрещает религия, могу дать доступ по записи к репозиторию с исходниками.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
По цитированию предложение.
Либо делать все предыдущее цитирование под катом,либо оставить как есть, но если цитата длинная, то все что длиннее 5 строк заменяется на ..., если хочешь именно этот текст процитировать, то делаешь усиление ___ваыв___ . В текущем механизме генерации сообщений цитирование подбешивает тем, что приходится делать работу по форматированию авто-генерированного текста, чтобы не сидеть в бане.
Здравствуйте, AndrewVK, Вы писали:
AVK>Дальнейший шаг очевиден — надо сделать прототип реализации парсера. Если тебя эта задача не пугает и дотнет не запрещает религия, могу дать доступ по записи к репозиторию с исходниками.
С дотнетом, к сожалению, не знаком.
Если порог вхождения в проект с тесткейсами будет невысоким, могу их поштамповать.
Здравствуйте, ShaggyOwl, Вы писали:
SO>Если порог вхождения в проект с тесткейсами будет невысоким, могу их поштамповать.
Тесткейсы устроены очень просто. Каждый тесткейс это два файла с одинаковым именем. В одном, с расширением txt, находится текст с разметкой, в другом, с расширением gold, html, который должен получиться на выходе. Еще нужны тесты парсера, там на выходе дамп дерева в каком то читаемом формате — тип узла, координаты, значения свойств.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Тесткейсы устроены очень просто. Каждый тесткейс это два файла с одинаковым именем. В одном, с расширением txt, находится текст с разметкой, в другом, с расширением gold, html, который должен получиться на выходе. Еще нужны тесты парсера, там на выходе дамп дерева в каком то читаемом формате — тип узла, координаты, значения свойств.
Т.е. задача видится вполне подъёмной. Я правильно понимаю — сейчас уже есть готовые тесты на которые можно будет посмотреть?
Как дойдёт дело до реализации — свисти, буду рад участвовать.
Контакты сейчас отправлю на мыло из профиля.
Здравствуйте, ShaggyOwl, Вы писали:
SO>Т.е. задача видится вполне подъёмной. Я правильно понимаю — сейчас уже есть готовые тесты на которые можно будет посмотреть?
Для нового форматтера тестов нет, для старого есть, но очень немного.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Выделяется символами ** с обеих сторон. При этом справа от открывающей ** должен быть пробел или начало строки, а слева не пробел и не конец строки. Для закрывающей, соответственно, не пробел и не начало строки справа, и пробел или конец строки слева.
Вопрос. Не очень понимаю, что такое начало строки в данном контексте.
2. Для табличек необходимо определять и правую границу.
3. Я как-то упустил момент обсуждения двойных звёздочек в коде. Можешь кинуть ссылку?
Здравствуйте, ShaggyOwl, Вы писали:
SO>Вопрос. Не очень понимаю, что такое начало строки в данном контексте.
А в чем проблема? Начало строки это начало строки. Первый символ после начала файла или переноса строки.
SO>2. Для табличек необходимо определять и правую границу.
Зачем? Табличка со стилем float:left?
SO>3. Я как-то упустил момент обсуждения двойных звёздочек в коде. Можешь кинуть ссылку?
С кодом пока ничего не решено. Строку целиком выделить сравнительно просто. Например, >>> в начале. А вот с произвольным куском непонятно. Я лично за >>>...<<< + правила с пробелами, как у стилей текста, с сишным сдвигом конфликтовать не должно.
... << RSDN@Home 1.2.0 alpha 5 rev. 65 on Windows 7 6.1.7601.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>А в чем проблема? Начало строки это начало строки. Первый символ после начала файла или переноса строки.
При этом справа от открывающей ** должен быть пробел или начало строки, а слева не пробел и не конец строки
https://bitbucket.org/andrewvk/rsdn.format/wiki/Specification
Справа от открывающей "**" не может находиться начало строки.
SO>>2. Для табличек необходимо определять и правую границу. AVK>Зачем? Табличка со стилем float:left?
Выравнивание по правой стороне.
| head1 | head2 |
|cell| right-aligned cell|
Нижняя правая ячейка будет выровнена по правой стороне (нет пробела/таба между содержимым и правой границей).
SO>>3. Я как-то упустил момент обсуждения двойных звёздочек в коде. Можешь кинуть ссылку? AVK>С кодом пока ничего не решено. Строку целиком выделить сравнительно просто. Например, >>> в начале. А вот с произвольным куском непонятно. Я лично за >>>...<<< + правила с пробелами, как у стилей текста, с сишным сдвигом конфликтовать не должно.
Пара ">>>" + "<<<" выглядит неплохо.
А какие альтернативы есть?
Здравствуйте, AndrewVK, Вы писали:
SO>>Справа от открывающей "**" не может находиться начало строки. AVK>Опечатка
Да, аналогично нужно про закрывающую пару звёздочек пофиксить.
AVK>Значит придется сделать замыкающий |.
Да.
AVK>ХЗ. Пока предлагался только [b]...[/b]
Не вписывается в новый синтаксис, ">>>"+"<<<" симпатичнее.