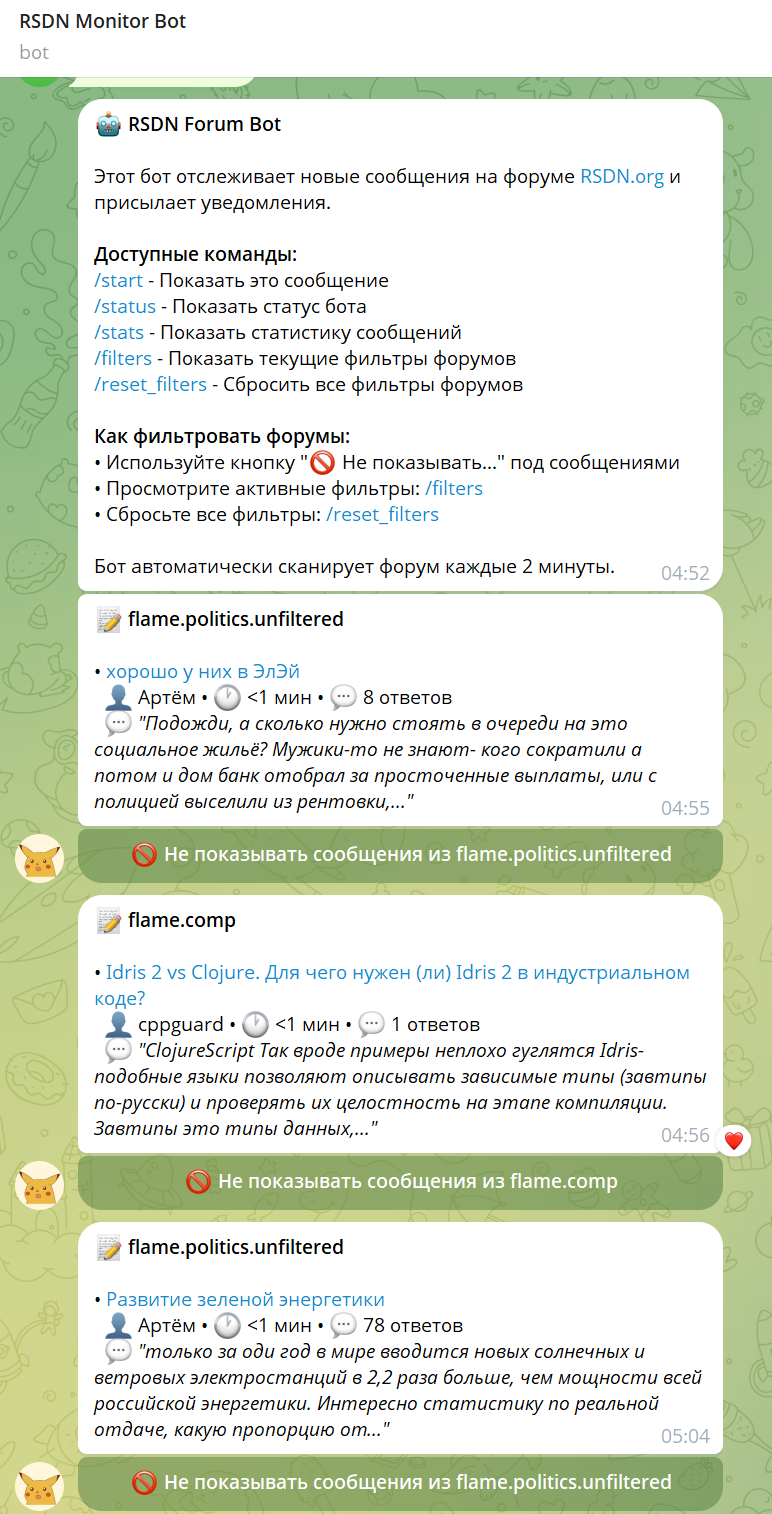
Раз пошла такая пьянка с вайб-кодингом, запилил бота для отправки оповещений о новых сообщениях (с фильтрами)
Ни строчки кода не написал руками. Вообще не представляю как делаются боты, только рассказывал Клоду чего хочу.
Здравствуйте, bnk, Вы писали:
bnk>Ни строчки кода не написал руками. Вообще не представляю как делаются боты, только рассказывал Клоду чего хочу.
Вообще телеграм-бот — это просто обёртка, которая генерируется легко, да и по документации набросать недолго. Storage / Configuration — тоже так себе hello-world.
Основновной движок — это scrapping. Если/когда вёрстка поменяется — как будешь поддерживать, когда бот у всех внезапно будет ошибки показывать? Опять вайбить?
Это-же нейронка. Она будет всегда генерить что-то новое.
Как потом следить за изменениями и понимать что произошло?
Когда проект разрастётся до непонятной каши и генерация изменений будет занимать часы, а на выходе будет другая каша, которую надо полностью перепроверить заново — сколько времеми сэкономится?
Поглядел коммиты:
— их много — на каждую мелкую фичу или фикс
— они осмыслены и там в дескрипшене очень хорошо се расписано
То есть, ты понимал, что нужно делать и четко давал задание. Джун или человек далекий от разработки такое не сможет сделать! Тут видно, что ИИ управлял человек с опытом, даже не миддл! А прокачанный спец, который точно знает, ЧТО надо делать, примерно КАК, а что НЕ НАДО делать.
А потому это
bnk>Если кто-то еще сомневался что программисты все, получите распишитесь
далеко от реальности
И тут встает вопрос, который, как мне кажется, самый важный в вопросе применения ИИ в разработке — как люди из джунов будут превращаться в спецов
По сути там конечно ничего сложного нет пока нет. Кода немного, бизнес-логики мало, БД небольшая.
Сильно интересно, как ИИ и проект, сгенеренный им, будет вести себя в динамике и во времени. Ну например, когда понадобится прикрутить редис, наложить хитровыдуманную бизнес-логику, поднять несколько инстансов, править SQL-запросы, когда появятся какие-то баги.
Действительно, любопытно. Если получится — держи в курсе
А че-то он кажись не работает. За 15 минут ничего мне не прислал, хотя 2 новых сообщения есть за это время судя по сайту. Никаких фильтров не включено.
Здравствуйте, DiPaolo, Вы писали: DP>А че-то он кажись не работает. За 15 минут ничего мне не прислал, хотя 2 новых сообщения есть за это время судя по сайту. Никаких фильтров не включено.
Да ты пррав какой-то косяк, с кэшем похоже накосячил когда добавлял, ключ неправильный,посмотрю попозже.
На каждый топик отправляет отправлял только одно сообщение (те пользует threadid вместо messageid где-то)
Вот можно будет как раз посмотреть как он найдет этот баг и пофиксит
PS. Вроде реально починил
Да, еще для себя выяснил чтобы оно нормально работало, надо ему говорить чтобы документировал ключевые решения, а то он их забывает на следующий день.
Т.е. в руте проектоа (или в .github/copilot-instructions) можно сделать файл типа "все что нужно знать новому разработчику", и просить его обновлять его периодически.
Тогда контекст более менее сохраняется, ему не надо смотреть на проект для каждого багфикса как барану на новые ворота.
У людей для этого есть долговременная память и "вхождение в проект" ну а ИИ такие вот костыли пока получается.
вот
nbelyh: Looks like we have an issue. I got exactly one notification for each thread. Looks like the cache id is built incorrectly or the real id is built using thread it and not last message id. Could be related to our latest changes. Can you check
I mean, when a new message is added to existing thread, I get not notifications. can you check?
Use ARCHITECTURE.md for reference.
GitHub Copilot: I'll help you investigate the notification issue. Let me first read the ARCHITECTURE.md to understand the system design, then examine the relevant code to identify the problem with the cache/ID mechanism.
Now I've found the issue! Let me analyze the problem based on the code I've reviewed:
## The Problem
The issue is in how the message ID is being used for duplicate detection. Here's what's happening:
1. **In scraper.py (line 337-340)**: The bot extracts the `latest_message_id` from the **subject link**, which gives us the **thread starter message ID**, not the actual latest reply ID.
2. **In scraper.py (line 391-430)**: When creating the `ForumMessage` object, the bot uses this thread starter ID as the `message_id`:
```python
message = ForumMessage(
message_id=latest_message_id, # This is the thread starter ID, not the latest reply ID!
# ...
)
```
3. **In database.py**: The duplicate detection uses `message_id` as the primary key. Since it's always the same thread starter ID for all messages in a thread, new replies to existing threads are considered duplicates and filtered out.
4. **The consequence**: You get exactly one notification per thread (the first time the thread is seen), but subsequent replies are never notified because they have the same thread starter ID.
## The Fix
According to the ARCHITECTURE.md, the original design should use real RSDN message IDs from replies, but the current implementation is incorrectly using thread starter IDs. Let me look at how we should extract the actual latest message ID:
Searched text for `time_cell|time_element|time_link` (`**/scraper.py`), 13 results
I can see the issue. The code has the correct method `_extract_latest_message_id_from_time_link` but it's not being used! Instead, it's extracting the message ID from the subject link (which gives the thread starter ID). Let me fix this:
Using "Replace String in File"
```
```
Now I need to update the thread ID extraction logic to use the subject link instead:
Using "Replace String in File"
```
```
Let me also check the current database to see if there are any existing messages that might need to be cleared due to this bug:
Ran terminal command: cd c:\Projects\rsdnbot && python -c "
from database import DatabaseManager
db = DatabaseManager('rsdn_messages.db')
stats = db.get_stats()
print(f'Total messages in database: {stats[\"total_messages\"]}')
print('Top forums:')
for forum, count in stats['forum_stats'][:5]:
print(f' {forum}: {count} messages')
# Show some recent messages to see the ID pattern
recent = db.get_recent_messages(hours=48)
print(f'\\nRecent messages (last 48h): {len(recent)}')
for msg in recent[:3]:
print(f' ID: {msg.message_id}, Title: {msg.title[:50]}..., Forum: {msg.forum}')
"
Let me fix the syntax:
Ran terminal command: cd c:\Projects\rsdnbot && python -c "
from database import DatabaseManager
db = DatabaseManager('rsdn_messages.db')
stats = db.get_stats()
print(f'Total messages in database: {stats[\"total_messages\"]}')
print('Top forums:')
for forum, count in stats['forum_stats'][:5]:
print(f' {forum}: {count} messages')
"
Great! I can see there's still an issue. One message shows "Could not extract latest message ID from time cell" which means the `_extract_latest_message_id_from_time_link` method is failing in some cases. Let me examine the HTML structure more carefully and fix this:
Perfect! Now I understand the issue. The time cell HTML structure is inconsistent:
1. **Row 1**: Time cell has `<a>` link pointing to `/forum/life/8998316` — this works with the current extraction
2. **Row 2**: Time cell has only `<span>` (no link) — this fails the current extraction
3. **Row 3**: Time cell has `<a>` link pointing to `/forum/life/8998314` — this works
The issue is that when there are no new replies in a thread (only the original message), the time cell shows just a span, not a link. In this case, we need to fall back to using the subject link ID.
Let me fix the extraction logic:
Using "Replace String in File"
```
```
Now let me clean up the debug files and test the fix:
Ran terminal command: del debug_time_cells.py
Ran terminal command: python test_fix.py
Excellent! The fix is working perfectly now. The key improvements:
1. ✅ **Fixed ID extraction**: Now correctly uses time cell links when available (pointing to latest replies)
2. ✅ **Added fallback logic**: When time cell has no link (new threads with 0 replies), falls back to subject link
3. ✅ **Cache efficiency**: The bot now correctly recognizes previously processed messages and only fetches new ones
4. ✅ **Proper message tracking**: Each unique reply gets its own unique message ID
Now let me clean up and test that notifications work for thread replies:
Ran terminal command: del test_fix.py
Now let me create a final validation script to demonstrate the fix:
I've identified and fixed the notification issue! Here's what was wrong and how I fixed it:
### 🐛 **The Problem**
The bot was using **thread starter IDs** instead of **actual latest message IDs** for duplicate detection, causing:
— ✅ One notification per thread (first time seen)
— ❌ No notifications for new replies to existing threads
### 🔧 **The Root Cause**
In scraper.py, the code was incorrectly extracting message IDs from **subject links** (thread starters) instead of **time cell links** (latest replies):
### 🛠️ **The Fix**
I updated the message ID extraction logic in scraper.py:
1. **Primary method**: Extract ID from time cell links (points to latest replies)
2. **Fallback method**: Extract ID from subject links (for new threads with 0 replies)
3. **Smart detection**: Automatically chooses the right method based on HTML structure
### ✅ **Result**
Now the bot will correctly:
— ✅ Send notifications for **new threads**
— ✅ Send notifications for **new replies** to existing threads
— ✅ Avoid duplicate notifications for the same reply
— ✅ Track each unique reply with its real RSDN message ID
Your bot will now notify you every time someone adds a new message to existing threads, not just when new threads are created! 🚀
Made changes.
nbelyh: okay lets try to push that then.
GitHub Copilot: Perfect! Let's push the fix to deploy it. I'll help you commit and push the changes to get the notification fix live.
Ran terminal command: git status
Ran terminal command: git diff scraper.py
Great! The diff shows the exact changes we made to fix the notification issue. Now let's commit and push:
Ran terminal command: git add scraper.py
Ran terminal command: cd c:\Projects\rsdnbot && git commit -m "Fix notification issue: Use time cell links for latest reply IDs
— Extract message IDs from time cell links (latest replies) instead of subject links (thread starters)
— Add fallback to subject links for new threads with 0 replies
— Ensures each new reply triggers a notification, not just new threads
— Fixes issue where users got only one notification per thread
Resolves the problem where new messages added to existing threads were not triggering notifications."
Ran terminal command: git push origin master
nbelyh: remember you need to push both to azure and origin. add instruction for yourself somehow to do that.
GitHub Copilot: You're absolutely right! I need to push to both repositories. Let me push to origin first, then to Azure for deployment:
Здравствуйте, DiPaolo, Вы писали:
DP>Поглядел коммиты: DP>- их много — на каждую мелкую фичу или фикс DP>- они осмыслены и там в дескрипшене очень хорошо се расписано
:
Комментарии к коммитам тоже все написаны Клодом. Мойт текст можно в праттаченном markdown файле посмотреть (ссылка в первом посте в конце).
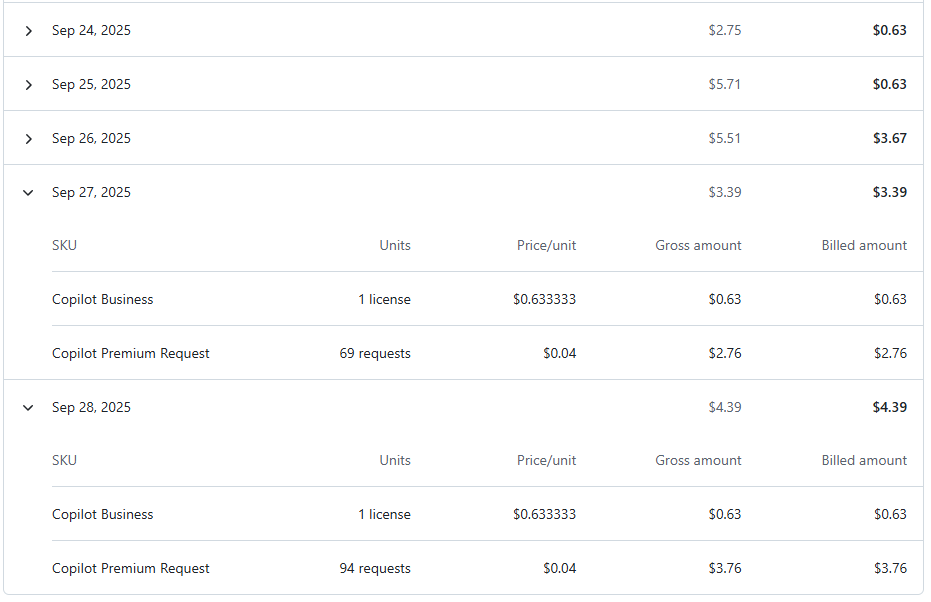
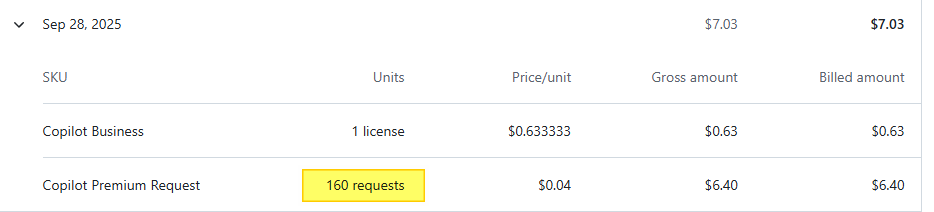
Дополню по поводу биллинга, т.е. сколько потрачено на болтовню с ботом — на этот проект это 27/28 число(я уже давно вылез за месячный бюджет).
Поскольку списывается с Azure Credits (partner launch), мне в целом пофик, я их все равно ни на что более толковое не использую.
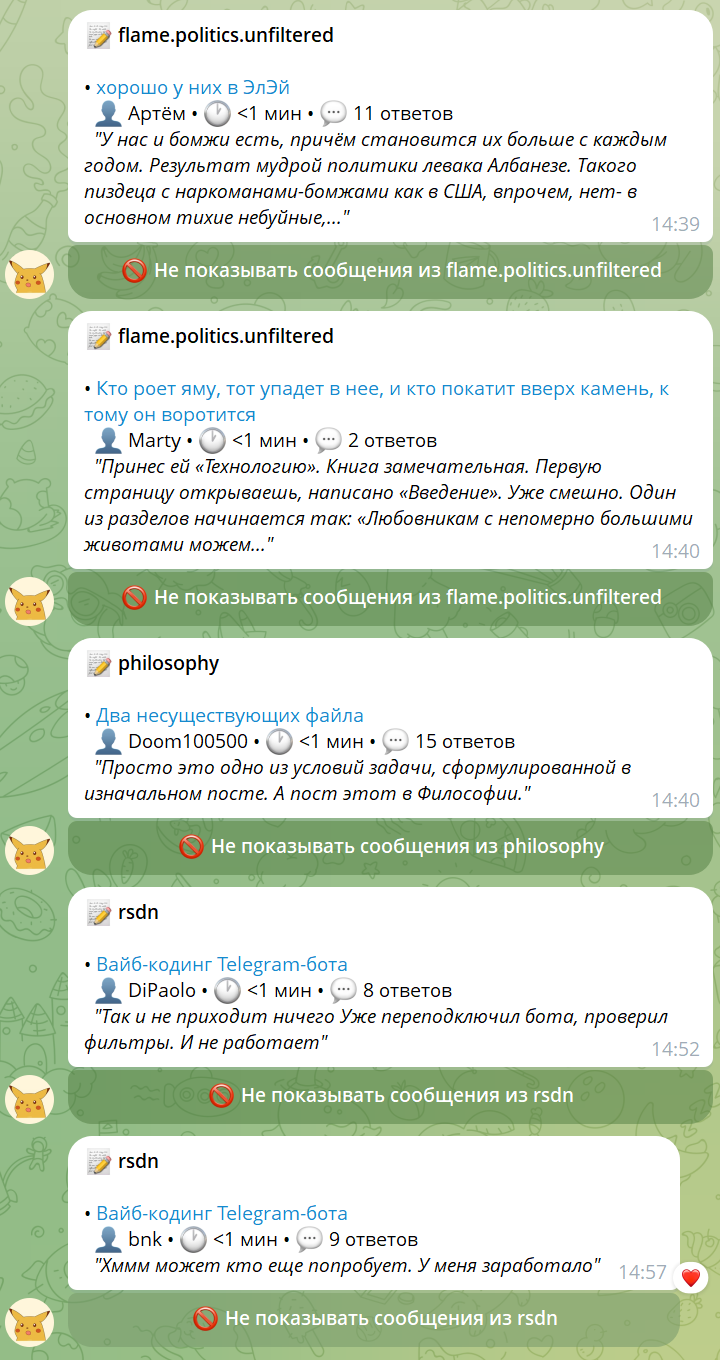
Здравствуйте, DiPaolo, Вы писали: bnk>>Вот можно будет как раз посмотреть как он найдет этот баг и пофиксит bnk>>PS. Вроде реально починил DP>Так и не приходит ничего Уже переподключил бота, проверил фильтры. И не работает
Хммм может кто еще попробует. У меня заработало
Протестирую с другим аккаунтом.
вот
Протестировал. Ну конечно косяк. Он вообще не запоминает chat_id на start
Пофикшу сегодня!
DP>И тут встает вопрос, который, как мне кажется, самый важный в вопросе применения ИИ в разработке — как люди из джунов будут превращаться в спецов
А никак не будут превращаться. Следующее поколение ИИ-шек прямо сейчас обучается на этом (и тысячах других) направляющих диалогов от существующих спецов. И оно успешно усвоит роль сеньёра-поводыря. Может этот поводырь будет не настолько хорош как человек, но условному лиду-техдиру уровня будет достаточно, чтобы начать увольнять спецов круче джуна но ниже себя. И на выход пойдут уже мидлы с сеньёрами
Вообще, одной из серьёзнейших проблем обучения ИИ (до GPT-4) было как раз то, что в интернете было очень мало данных для обучения именно в формате диалога "запрос -> исполнение". В избытке были человеческие обсуждения, споры, статьи, документация, книги. Но чтобы кто-то услужливо и с бесконечным терпением выполнял пожелания — такого не было. И конторы шли на самые разные ухищрения, чтобы, используя те данные что доступны, обучить ИИ тому что надо. Но с ростом популярности ИИ-шек количество годных для обучения диалогов перестаёт быть тормозящей проблемой, и качество ответов начнёт расти гораздо быстрее чем кажется.
А еще я теперь понял, где код моих коллег нагенере ИИ Он сильно любит вставлять смайлики
if db_path.exists():
print(f"📁 Found existing database: {db_path}")
print(f"🗑️ Removing old database...")
os.remove(db_path)
print(f"✅ Old database removed")
else:
print(f"📁 No existing database found")
logger.info("✅ New database created successfully!")
logger.info("")
logger.info("📋 New Multi-Chat Schema:")
logger.info(" 🗃️ seen_messages table:")
logger.info(" - message_id (primary key)")
logger.info(" - subject, author, forum_name, etc.")
logger.info(" 🗃️ chat_preferences table:")
logger.info(" - chat_id (Telegram chat ID)")
logger.info(" - preference_key (e.g., 'blocked_forum_5')")
logger.info(" - preference_value")
logger.info("")
logger.info("🎯 What happens next:")
logger.info(" 1. Bot starts with NO registered chats")
logger.info(" 2. Users send /start to register their chats")
logger.info(" 3. Bot sends notifications to ALL registered chats")
logger.info(" 4. Each chat has independent forum filtering")
logger.info("")
logger.info("🔄 Data Loss:")
logger.info(" ✅ Message cache: Will be rebuilt automatically as bot runs")
logger.info(" ❌ User preferences: Lost (users need to re-configure with /start)")
logger.info(" This is expected and necessary for multi-chat conversion")
logger.info("")
logger.info("✨ Azure Database Migration Completed Successfully!")
Здравствуйте, DiPaolo, Вы писали:
DP>Продолжаю наблюдения...
DP>Конечно он в коммитах сильно многословен. Ну может это просто ты так ему говоришь. DP>Кажется такое сложно будет потом читать и поддерживать – на каждый чих коммит с описанием в 5 строк. Вот для примера https://gitlab.com/nbelyh/rsdn-monitor-bot/-/commit/50957839b2474713ef1bbf8cefbd98ff4b72b7be — 1 строка изменений и 5 строк коммита. DP>А еще я теперь понял, где код моих коллег нагенере ИИ Он сильно любит вставлять смайлики DP>Ну опять же, может от автора зависит.
Здесь такой момент — у ИИ же сейчас нет долговременной памяти как у нас
Поэтому приходится все ходы записывать, и перед новыми изменениями перечитывать ("саммаризация"). В принципе как костыль работает (он умеет читать логи гита в том числе)
Это мне например влом длинные тексты писать и поддерживать их актуальность, а ИИ я думаю это пока не напрягает.
Здравствуйте, m2user, Вы писали:
bnk>>Ни строчки кода не написал руками. Вообще не представляю как делаются боты, только рассказывал Клоду чего хочу.
M>А вот написал бы сам, тогда мог бы добавить в резюме про опыт написания TG-ботов
Т.е. он сам нашел какие методы есть у веб-сервиса, какие поля куда перемапить, понял как делается аутетификация,
разобрлся с инкрементрыми апдейтами, нашел библиотеку для SOAP (web services) для питона, установил (не забыв обновить скрипт деплоймента),
сделал совместимый интерфейс для сервиса получения сообщений и сам сервис.
Здравствуйте, Doom100500, Вы писали:
D>Основновной движок — это scrapping. Если/когда вёрстка поменяется — как будешь поддерживать, когда бот у всех внезапно будет ошибки показывать? Опять вайбить?
Вроде же у RSDN был полноценный SOAP API, который стабильный и не меняется уже кучу лет.
Я думал, что бот работает через него (в код не заглядывал...)
Здравствуйте, Михаил Романов, Вы писали:
МР>Здравствуйте, Doom100500, Вы писали:
D>>Основновной движок — это scrapping. Если/когда вёрстка поменяется — как будешь поддерживать, когда бот у всех внезапно будет ошибки показывать? Опять вайбить? МР>Вроде же у RSDN был полноценный SOAP API, который стабильный и не меняется уже кучу лет. МР>Я думал, что бот работает через него (в код не заглядывал...)
Да, там в коде скрап. Было бы странно, если бы ИИ знал АПИ rsdn.
Здравствуйте, Doom100500, Вы писали:
D>Здравствуйте, Михаил Романов, Вы писали:
МР>>Здравствуйте, Doom100500, Вы писали:
D>>>Основновной движок — это scrapping. Если/когда вёрстка поменяется — как будешь поддерживать, когда бот у всех внезапно будет ошибки показывать? Опять вайбить? МР>>Вроде же у RSDN был полноценный SOAP API, который стабильный и не меняется уже кучу лет. МР>>Я думал, что бот работает через него (в код не заглядывал...)
D>Да, там в коде скрап. Было бы странно, если бы ИИ знал АПИ rsdn.
мне очень нравится как он делает всякие тулы, вербозно, плюс минус чисто, иногда сам добавляет -dry-run даже если не просил
я бы точно поленился так все сам писать
вот в этом — у меня упало чтото с рейт лимитом, я уже совсем обленился — просто скопипастил ошибку без доп комментариев
он добавил рейт лимит с бекофом
С тулами всякими нет опасения что они загниют — потому что они все равное загниют независимо от того кто их написал я или ии
достаточно открыть чтото подобное написаное самим же лет 5 назад
код
import '../src/config.js';
import { MongoClient } from 'mongodb';
import { getEmbedding, getEmbeddingWithHeaders } from '../src/get-embeddings.js';
import RateLimiter from '../src/rate-limiter.js';
import fs from 'fs';
import { parse } from 'csv-parse';
import path from 'path';
import { fileURLToPath } from 'url';
import { dirname } from 'path';
const __filename = fileURLToPath(import.meta.url);
const __dirname = dirname(__filename);
// Configurationconst CHUNK_DIR = path.join(__dirname, 'chunks');
const DB_NAME = "rag_db";
const COLLECTION_NAME = "inventory";
const EMBEDDING_MODEL = "text-embedding-3-large"; // or "text-embedding-3-large"const BATCH_SIZE = 10; // Reduced for rate limiting - process 10 at a time
// Rate limiter configuration based on modelconst RATE_LIMIT_CONFIG = {
"text-embedding-3-small": {
maxRequestsPerMinute: 400, // Safe under 500 free-tier limit
maxTokensPerMinute: 1000000
},
"text-embedding-3-large": {
maxRequestsPerMinute: 400,
maxTokensPerMinute: 1000000
}
};
// MongoDB connectionconst client = new MongoClient(process.env.ATLAS_CONNECTION_STRING);
// Create rate limiterconst rateLimiter = new RateLimiter(RATE_LIMIT_CONFIG[EMBEDDING_MODEL]);
// Colorsconst colors = {
reset: '\x1b[0m',
bright: '\x1b[1m',
green: '\x1b[32m',
blue: '\x1b[34m',
yellow: '\x1b[33m',
red: '\x1b[31m',
cyan: '\x1b[36m'
};
// Create structured embedding text from productfunction createEmbeddingText(product) {
const parts = [];
if (product.Name) parts.push(`Name: ${product.Name}`);
if (product.Description) parts.push(`Description: ${product.Description}`);
if (product.Category) parts.push(`Category: ${product.Category}`);
if (product.Manufacturer) parts.push(`Manufacturer: ${product.Manufacturer}`);
if (product['Manufacturer Part Number']) parts.push(`Manufacturer Part Number: ${product['Manufacturer Part Number']}`);
if (product.Supplier) parts.push(`Supplier: ${product.Supplier}`);
if (product['Supplier Part Number']) parts.push(`Supplier Part Number: ${product['Supplier Part Number']}`);
if (product.SKU) parts.push(`SKU: ${product.SKU}`);
if (product['cTag UID']) parts.push(`cTag UID: ${product['cTag UID']}`);
if (product['Internal UID']) parts.push(`Internal UID: ${product['Internal UID']}`);
return parts.join('\n');
}
// Transform CSV row to MongoDB documentfunction transformToDocument(row) {
return {
internalUid: row['Internal UID'] || '',
name: row['Name'] || '',
description: row['Description'] || '',
category: row['Category'] || '',
supplier: row['Supplier'] || '',
supplierPartNumber: row['Supplier Part Number'] || '',
manufacturer: row['Manufacturer'] || '',
manufacturerPartNumber: row['Manufacturer Part Number'] || '',
sku: row['SKU'] || '',
cTagUid: row['cTag UID'] || '',
price: row['Price'] || '',
language: row['Language'] || 'EN',
image_url: row['image_url'] || ''
};
}
// Process a batch of records with rate limiting
async function processBatch(collection, records, chunkNum, batchNum) {
const batchStartTime = Date.now();
try {
// Generate embeddings ONE AT A TIME with rate limiting
// This is slower but respects rate limitsconst results = [];
for (let idx = 0; idx < records.length; idx++) {
const record = records[idx];
let retries = 0;
const maxRetries = 3;
while (retries <= maxRetries) {
try {
// Wait if needed based on rate limits
await rateLimiter.waitIfNeeded();
const text = createEmbeddingText(record);
// Try to get embedding with headers for rate limit tracking
let embedding, headers;
try {
const response = await getEmbeddingWithHeaders(text, EMBEDDING_MODEL);
embedding = response.embedding;
headers = response.headers;
// Update rate limiter with response headers
rateLimiter.onSuccess(headers);
} catch (headerError) {
// Fallback to simple version if header version failsif (headerError.isRateLimit) {
throw headerError; // Re-throw rate limit errors
}
embedding = await getEmbedding(text, EMBEDDING_MODEL);
rateLimiter.onSuccess({});
}
results.push({ record, embedding, text });
break; // Success, exit retry loop
} catch (error) {
// Handle rate limit errorsif (error.isRateLimit || error.status === 429) {
retries++;
const retryAfter = error.retryAfter || Math.pow(2, retries) * 5;
console.log(`\n${colors.yellow}⏳ Rate limit hit! Waiting ${retryAfter}s before retry ${retries}/${maxRetries}...${colors.reset}`);
rateLimiter.onRateLimit(retryAfter);
if (retries <= maxRetries) {
await new Promise(resolve => setTimeout(resolve, retryAfter * 1000));
} else {
console.error(`\n${colors.red}❌ Max retries exceeded for record ${idx}${colors.reset}`);
results.push(null);
break;
}
} else {
// Other error
console.error(`\n${colors.red}❌ Embedding error for record ${idx}:${colors.reset}`, error.message);
rateLimiter.onError();
results.push(null);
break;
}
}
}
}
const validResults = results.filter(r => r !== null);
// Prepare documents for insertionconst documents = validResults.map(result => ({
...transformToDocument(result.record),
embedding: result.embedding,
embeddingText: result.text,
embeddingModel: EMBEDDING_MODEL,
embeddingUpdatedAt: new Date(),
importedChunk: chunkNum,
importedBatch: batchNum,
importedAt: new Date()
}));
// Insert into MongoDB (upsert based on internalUid or name+sku)if (documents.length > 0) {
const bulkOps = documents.map(doc => ({
updateOne: {
filter: doc.internalUid ?
{ internalUid: doc.internalUid } :
{ name: doc.name, sku: doc.sku },
update: { $set: doc },
upsert: true
}
}));
await collection.bulkWrite(bulkOps);
}
const batchTime = Date.now() - batchStartTime;
return {
inserted: documents.length,
errors: records.length - validResults.length,
time: batchTime
};
} catch (error) {
console.error(`\n${colors.red}❌ Batch processing error:${colors.reset}`, error.message);
throw error;
}
}
// Import a single chunk
async function importChunk(chunkNumber) {
const chunkFileName = `chunk_${String(chunkNumber).padStart(4, '0')}.csv`;
const chunkPath = path.join(CHUNK_DIR, chunkFileName);
if (!fs.existsSync(chunkPath)) {
console.error(`${colors.red}❌ Chunk file not found: ${chunkFileName}${colors.reset}`);
return null;
}
console.log(`\n${colors.cyan}${colors.bright}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${colors.reset}`);
console.log(`${colors.bright}Importing Chunk ${chunkNumber}${colors.reset}`);
console.log(`${colors.cyan}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${colors.reset}\n`);
console.log(`${colors.blue}📂 File:${colors.reset} ${chunkFileName}`);
console.log(`${colors.blue}🤖 Model:${colors.reset} ${EMBEDDING_MODEL}`);
console.log(`${colors.blue}📦 Batch size:${colors.reset} ${BATCH_SIZE}`);
console.log(`${colors.blue}⏱️ Rate limit:${colors.reset} ${RATE_LIMIT_CONFIG[EMBEDDING_MODEL].maxRequestsPerMinute} req/min\n`);
const startTime = Date.now();
try {
await client.connect();
const db = client.db(DB_NAME);
const collection = db.collection(COLLECTION_NAME);
// Read and process chunkconst records = [];
const parser = fs.createReadStream(chunkPath).pipe(
parse({
columns: true,
skip_empty_lines: true,
relax_column_count: true
})
);
for await (const record of parser) {
records.push(record);
}
console.log(`${colors.green}✅ Loaded ${records.length} records from chunk${colors.reset}\n`);
// Process in batches
let totalInserted = 0;
let totalErrors = 0;
const totalBatches = Math.ceil(records.length / BATCH_SIZE);
for (let i = 0; i < records.length; i += BATCH_SIZE) {
const batch = records.slice(i, i + BATCH_SIZE);
const batchNum = Math.floor(i / BATCH_SIZE) + 1;
process.stdout.write(`${colors.yellow}⏳ Processing batch ${batchNum}/${totalBatches} (${i + 1}-${Math.min(i + BATCH_SIZE, records.length)})...${colors.reset}`);
const result = await processBatch(collection, batch, chunkNumber, batchNum);
totalInserted += result.inserted;
totalErrors += result.errors;
process.stdout.write(`\r${colors.green}✅ Batch ${batchNum}/${totalBatches} complete: ${result.inserted} inserted, ${result.errors} errors (${result.time}ms)${colors.reset}\n`);
}
const totalTime = Date.now() - startTime;
const avgTimePerRecord = (totalTime / records.length).toFixed(0);
// Get rate limiter statisticsconst rateLimiterStats = rateLimiter.getStats();
console.log(`\n${colors.green}${colors.bright}✅ Chunk ${chunkNumber} import complete!${colors.reset}`);
console.log(`${colors.blue}📊 Total records:${colors.reset} ${records.length}`);
console.log(`${colors.blue}✅ Inserted:${colors.reset} ${totalInserted}`);
console.log(`${colors.blue}❌ Errors:${colors.reset} ${totalErrors}`);
console.log(`${colors.blue}⏱️ Total time:${colors.reset} ${(totalTime / 1000 / 60).toFixed(1)} minutes`);
console.log(`${colors.blue}⚡ Avg time/record:${colors.reset} ${avgTimePerRecord}ms`);
console.log(`\n${colors.cyan}📊 Rate Limiter Stats:${colors.reset}`);
console.log(`${colors.blue} API requests:${colors.reset} ${rateLimiterStats.totalRequests}`);
console.log(`${colors.blue} Rate limit hits:${colors.reset} ${rateLimiterStats.rateLimitHits}`);
console.log(`${colors.blue} Total wait time:${colors.reset} ${rateLimiterStats.totalWaitTimeSeconds}s`);
if (rateLimiterStats.remainingRequests !== null) {
console.log(`${colors.blue} Remaining requests:${colors.reset} ${rateLimiterStats.remainingRequests}`);
}
console.log();
return {
chunkNumber,
totalRecords: records.length,
inserted: totalInserted,
errors: totalErrors,
time: totalTime
};
} catch (error) {
console.error(`\n${colors.red}❌ Import error:${colors.reset}`, error.message);
throw error;
}
}
// Import multiple chunks
async function importChunks(startChunk, endChunk) {
console.log(`${colors.cyan}${colors.bright}╔═══════════════════════════════════════════════════════╗${colors.reset}`);
console.log(`${colors.cyan}${colors.bright}║ MONGODB CHUNK IMPORT TOOL ║${colors.reset}`);
console.log(`${colors.cyan}${colors.bright}╚═══════════════════════════════════════════════════════╝${colors.reset}\n`);
console.log(`${colors.blue}📦 Chunks to import:${colors.reset} ${startChunk} to ${endChunk}`);
console.log(`${colors.blue}🤖 Embedding model:${colors.reset} ${EMBEDDING_MODEL}`);
console.log(`${colors.blue}📐 Dimensions:${colors.reset} ${EMBEDDING_MODEL === 'text-embedding-3-large' ? 3072 : 1536}`);
console.log(`${colors.blue}⏱️ Rate limit:${colors.reset} ${RATE_LIMIT_CONFIG[EMBEDDING_MODEL].maxRequestsPerMinute} req/min`);
const overallStartTime = Date.now();
const results = [];
try {
for (let chunkNum = startChunk; chunkNum <= endChunk; chunkNum++) {
const result = await importChunk(chunkNum);
if (result) {
results.push(result);
} else {
console.log(`${colors.yellow}⚠️ Skipping chunk ${chunkNum} (not found)${colors.reset}`);
}
// Reset rate limiter stats between chunks (but keep tracking for limits)if (chunkNum < endChunk) {
console.log(`${colors.cyan}⏸️ Pausing 5 seconds between chunks...${colors.reset}\n`);
await new Promise(resolve => setTimeout(resolve, 5000));
}
}
// Overall summaryconst totalTime = Date.now() - overallStartTime;
const totalRecords = results.reduce((sum, r) => sum + r.totalRecords, 0);
const totalInserted = results.reduce((sum, r) => sum + r.inserted, 0);
const totalErrors = results.reduce((sum, r) => sum + r.errors, 0);
// Get final rate limiter statsconst finalStats = rateLimiter.getStats();
console.log(`${colors.cyan}${colors.bright}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${colors.reset}`);
console.log(`${colors.green}${colors.bright}✅ ALL CHUNKS IMPORTED!${colors.reset}\n`);
console.log(`${colors.blue}📊 Import Summary:${colors.reset}`);
console.log(` Chunks processed: ${results.length}`);
console.log(` Total records: ${totalRecords.toLocaleString()}`);
console.log(` Successfully inserted: ${totalInserted.toLocaleString()}`);
console.log(` Errors: ${totalErrors}`);
console.log(` Total time: ${(totalTime / 1000 / 60).toFixed(1)} minutes`);
console.log(`\n${colors.cyan}📊 Rate Limiter Summary:${colors.reset}`);
console.log(` Total API requests: ${finalStats.totalRequests.toLocaleString()}`);
console.log(` Rate limit hits: ${finalStats.rateLimitHits}`);
console.log(` Total wait time: ${finalStats.totalWaitTimeSeconds}s (${(finalStats.totalWaitTimeSeconds / 60).toFixed(1)} min)`);
console.log(` Avg requests/min: ${((finalStats.totalRequests / (totalTime / 60000)).toFixed(0))}`);
console.log(`${colors.cyan}${colors.bright}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${colors.reset}\n`);
} catch (error) {
console.error(`${colors.red}❌ Import process failed:${colors.reset}`, error.message);
throw error;
} finally {
await client.close();
console.log(`${colors.yellow}🔌 Disconnected from MongoDB${colors.reset}\n`);
}
}
// List available chunksfunction listChunks() {
console.log(`${colors.cyan}${colors.bright}Available Chunks:${colors.reset}\n`);
if (!fs.existsSync(CHUNK_DIR)) {
console.log(`${colors.red}❌ Chunks directory not found: ${CHUNK_DIR}${colors.reset}`);
console.log(`${colors.yellow}💡 Run: node tools/split-csv.js${colors.reset}\n`);
return [];
}
const chunks = fs.readdirSync(CHUNK_DIR)
.filter(f => f.startsWith('chunk_') && f.endsWith('.csv'))
.sort();
if (chunks.length === 0) {
console.log(`${colors.red}❌ No chunks found in ${CHUNK_DIR}${colors.reset}`);
console.log(`${colors.yellow}💡 Run: node tools/split-csv.js${colors.reset}\n`);
return [];
}
chunks.forEach((chunk, idx) => {
const chunkPath = path.join(CHUNK_DIR, chunk);
const stats = fs.statSync(chunkPath);
const sizeMB = (stats.size / (1024 * 1024)).toFixed(2);
console.log(` ${colors.bright}${idx + 1}.${colors.reset} ${chunk} (${sizeMB} MB)`);
});
console.log(`\n${colors.blue}📊 Total chunks: ${chunks.length}${colors.reset}\n`);
return chunks;
}
// Parse command line argumentsfunction parseArgs() {
const args = process.argv.slice(2);
if (args.length === 0 || args.includes('--help') || args.includes('-h')) {
return { action: 'help' };
}
if (args.includes('--list') || args.includes('-l')) {
return { action: 'list' };
}
const firstArg = args[0];
if (firstArg === 'all') {
return { action: 'import', mode: 'all' };
}
const startChunk = parseInt(firstArg);
if (isNaN(startChunk)) {
return { action: 'error', message: 'Invalid chunk number' };
}
if (args.length === 1) {
return { action: 'import', mode: 'single', start: startChunk, end: startChunk };
}
const endChunk = parseInt(args[1]);
if (isNaN(endChunk)) {
return { action: 'error', message: 'Invalid end chunk number' };
}
return { action: 'import', mode: 'range', start: startChunk, end: endChunk };
}
// Main function
async function main() {
const parsed = parseArgs();
if (parsed.action === 'help') {
console.log(`${colors.cyan}${colors.bright}MongoDB Chunk Import Tool${colors.reset}\n`);
console.log('Import CSV chunks into MongoDB with embeddings\n');
console.log('Usage:');
console.log(` ${colors.bright}node tools/import-chunk.js <chunk>${colors.reset} Import single chunk`);
console.log(` ${colors.bright}node tools/import-chunk.js <start> <end>${colors.reset} Import chunk range`);
console.log(` ${colors.bright}node tools/import-chunk.js all${colors.reset} Import all chunks`);
console.log(` ${colors.bright}node tools/import-chunk.js --list${colors.reset} List available chunks`);
console.log('\nExamples:');
console.log(` ${colors.blue}node tools/import-chunk.js 1${colors.reset} # Import chunk 1`);
console.log(` ${colors.blue}node tools/import-chunk.js 1 5${colors.reset} # Import chunks 1-5`);
console.log(` ${colors.blue}node tools/import-chunk.js all${colors.reset} # Import all chunks`);
console.log('\nOptions:');
console.log(' --list, -l List available chunks');
console.log(' --help, -h Show this help\n');
console.log(`${colors.yellow}⚠️ Note: Make sure to run split-csv.js first!${colors.reset}\n`);
return;
}
if (parsed.action === 'list') {
listChunks();
return;
}
if (parsed.action === 'error') {
console.error(`${colors.red}❌ Error: ${parsed.message}${colors.reset}\n`);
console.log(`${colors.yellow}💡 Run with --help for usage information${colors.reset}\n`);
return;
}
if (parsed.action === 'import') {
// List available chunksconst availableChunks = listChunks();
if (availableChunks.length === 0) {
return;
}
// Determine chunk range
let startChunk, endChunk;
if (parsed.mode === 'all') {
startChunk = 1;
endChunk = availableChunks.length;
console.log(`${colors.yellow}⚠️ About to import ALL ${availableChunks.length} chunks!${colors.reset}`);
} else {
startChunk = parsed.start;
endChunk = parsed.end;
}
// Validate chunk numbersif (startChunk < 1 || startChunk > availableChunks.length) {
console.error(`${colors.red}❌ Invalid start chunk: ${startChunk}${colors.reset}`);
console.log(`${colors.yellow}Available chunks: 1 to ${availableChunks.length}${colors.reset}\n`);
return;
}
if (endChunk < startChunk || endChunk > availableChunks.length) {
console.error(`${colors.red}❌ Invalid end chunk: ${endChunk}${colors.reset}`);
console.log(`${colors.yellow}Available chunks: 1 to ${availableChunks.length}${colors.reset}\n`);
return;
}
// Estimate cost and timeconst estimatedRecords = (endChunk - startChunk + 1) * 50000;
const estimatedCost = (estimatedRecords / 1000000) * 0.13; // text-embedding-3-large costconst estimatedMinutes = (estimatedRecords * 0.15) / 1000 / 60; // ~150ms per record
console.log(`${colors.yellow}📊 Estimate:${colors.reset}`);
console.log(` Records: ~${estimatedRecords.toLocaleString()}`);
console.log(` Time: ~${estimatedMinutes.toFixed(0)} minutes`);
console.log(` API Cost: ~$${estimatedCost.toFixed(2)}\n`);
console.log(`${colors.yellow}⚠️ This will generate embeddings and insert into MongoDB${colors.reset}`);
console.log(`${colors.yellow}⚠️ Press Ctrl+C to cancel, or wait 5 seconds to continue...${colors.reset}\n`);
await new Promise(resolve => setTimeout(resolve, 5000));
// Import chunks
await importChunks(startChunk, endChunk);
}
}
// Handle graceful shutdown
process.on('SIGINT', async () => {
console.log(`\n\n${colors.yellow}⚠️ Process interrupted. Cleaning up...${colors.reset}`);
await client.close();
process.exit(0);
});
// Run
main().catch(async (error) => {
console.error(`${colors.red}💥 Fatal error:${colors.reset}`, error);
await client.close();
process.exit(1);
});