Здравствуйте, Sinix, Вы писали:
P_K>>Как можно создать файл dbschema имея терминальный доступ к серверу БД?
S>vsdbcmd? Не проверял.
Да, похоже оно. К тому же легко переносится на другую машину отдельно от студии.
P_K>>как удалять объекты из БД? Удаляю файл из Solution Explorer, но после билда в скрипте не появляется инструкции DROP.
S>Копаемся в настройках скриптогенератора (файл Database.sqldeployment).
О, точно! Есть такая опция.
S>
S>Деплоймент:
S>1. Обязательно иметь тестовый сервак, на него деплоить только пересозданием базы. В результате имеете постоянно рабочий deployment script для новых инсталляций.
Разве из проекта нельзя создать скрипт для новой инсталляции? Или у этого тестового сервера иная цель?
S>2. Для деплоймента на боевой сервак генерим скрипт, переносим в management studio, тщательно проверяем, бэкапим, запускаем (или полагаемся на студию/VSDBCMD и надеемся что ничего не сломается).
S>3. Более мягкий вариант — используем скрипт, сгенерированный schema compare.
Расскажите плиз о других способах генерации скрипта, отличных от schema compare.
S>Для комфортной работы придётся:
S>1. Обновиться до GDR R2. По возможности переходить на 2010ю студию, в VSTSDB 2008 множество багофич без шансов на исправление.
Улучшения 2010 студии не перекрываются её сыростью? А то мы пока решили дождаться SP1.
Кстати, о багофичах:
— Сейчас VSTSDB 2008 с GDR R2 выдаёт ворнинги (unresolved reference to object), если в хранимке используется временная таблица (вида #table). Примечательно, что в Management Studio для R2 такие временные таблицы начали распознаваться Intellisence.
— Не смог сделать импорт базы из SQL Server 2008 Express R2. Как оказалось 2008R2 не поддерживается, нужно юзать 2010 студию.
S>6. Сразу же озаботиться общим стилем кода — либо приобретать что-то платное (ходят слухи что кактолькотаксразу выпустят бесплатный автоформаттер), либо писать свои правила для static code analysis. Энфорсить стоит:
S>- обязательные точки с запятой
Расскажите поподробнее, какие могут быть проблемы
S>- N перед nvarchar-строками
S>- запрет на deprecated-фичи
S>- псевдонимы для таблиц
С остальным полностью согласен
Большое спасибо, узнал много ценной информации.
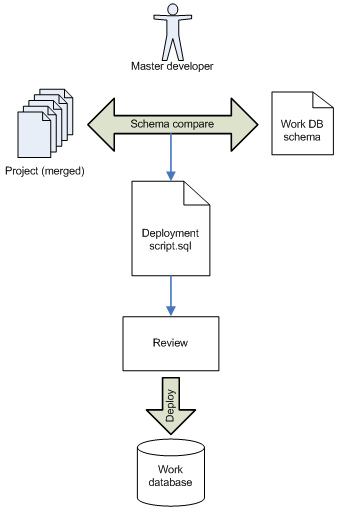
Таким образом, сейчас я получил такую картину организации работы:
1. Пара разработчиков работают над проектом БД (каждый над своей веткой), деплоят в одну разработчискую базу.

2. Когда работы завершены и все изменения смёржены, один из разработчиков с помощью Schema compare (проекта и схемы рабочей базы) генерирует скрипт со всеми изменениями. Тщательно просматривает его и деплоит на рабочую базу.