 Оценка 1050
Оценка 1050 
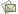 Оценить
Оценить 





| Оценка 1050 Оценить
|
Краткая информация о проекте Rsdn.Editor - Как скачать свежую версию, как присоединиться к проекту и т.д.
В этой статье я расскажу о новом открытом проекте Rsdn.Editor, его целях и проектных решениях, принятых при его реализации.
Это вступительная статья цикла, посвященного данному проекту. В остальных статьях цикла я постараюсь рассказать по отдельности о более-менее интересных частях этого проекта и подходах, использовавшихся при его реализации.
Откровенно говоря, архисерьезной необходимости в создании этого проекта не было. Занимаясь изучением 64-битной версии Windows XP, я натолкнулся на то, что процессы под управлением 64-битной версии .Net Framework, как, впрочем, и любые другие 64-битные процессы, не хотят загружать 32-битные библиотеки. А так хотелось посмотреть, как наши проекты (в основном RSDN@Home и CodeAnalyzer (визуальная утилита, входящая в R#)) работают под управлением 64-битной версии .Net Framework. R# и так мог на 90% исполняться под 64-битным Framework-ом, но злосчастные 10% приходились на CodeAnalyzer, очень удобную утилиту – все эксперименты с R# обычно производятся с ее помощью.
.NET-приложения, основанные на управляемом коде и не использующие расширений вроде IJW (из MC++), могут быть без перекомпиляции запущены под управлением 64-битного Framework-а. Если приложение написано мало-мальски грамотным программистом на C# или VB .NET, единственным препятствием может быть использование компонентов, основанных на неуправляемом коде или использующих такой код. В CodeAnalyzer такими компонентами оказались TreeGrid и Scintilla.
TreeGrid – это аналог TreeView, поддерживающий колонки, и позволяющий избежать копирования во внутренние коллекции TreeView, вместо этого храня данные во внешних, пользовательских коллекциях. Этот компонент был полностью переведен на C#, что позволило использовать его без перекомпиляции как в 32-битной, так и в 64-битной версии фреймворка.
| ПРИМЕЧАНИЕ Тут у некоторых может возникнуть вопрос... Зачем было переводить C++-код на C#? Неужели .NET не позволяет и на MC++ создать код, не требующий перекомпиляции на разных платформах? Позволяет. Но с одним ограничением. Дело в том, что (по крайней мере, во второй бета-версии .NET Framework 2.0) сборки MC++ становятся полностью переносимыми .NET-сборками только когда они компилируются с ключом /clr:safe (Safe MSIL Common Language Runtime Support). А в этом режиме MC++ из грозного монстра превращается в кроткую овечку. Даже более кроткую, чем C#. По идее, для переносимости должно было хватать режима /clr:pure, но пока это не так. Да и смысла в этом ненамного больше, чем при использовании режима /clr:safe. Основная проблема заключается в том, что не переносимой является главная возможность, предоставляемая MC++ – возможность использования IJW. В этом режиме можно пользоваться практически любыми C++-функциями, в том числе и большинством Windows API-функций. А ведь именно это является основным преимуществом, ради которого я в свое время выбрал MC++. Учитывая, что больше такого преимущества нет, и что в /clr:safe-режиме MC++ отличается от C# только ужасным синтаксисом, я решил отказаться от него. К тому же вести разработку на одном языке проще, чем на нескольких. Второй язык становится серьезным препятствием для проектов, которые должны разрабатываться на Express-версиях VS 2005, так как они не позволяют поместить в одно решение (Solution) проекты созданные на разных языках. В общем, как бы то ни было, но проект TreeGrid был переведен целиком на C#, так что проблема переносимости на другие платформы была решена. |
Вторым компонентом, создававшим проблемы, был редактор текста/кода – Scintilla. Это компонент с открытым кодом, написанный на C++ и переносимый между Windows и Linux. Scintilla не разрабатывалась с учетом 64-битных платформ. Она содержит несколько фрагментов кода, не позволяющих скомпилировать Scintilla-у в 64-битный исполняемый модуль. Но эти проблемы решаемы. Нужен где-то час, чтобы исправить ошибки и скомпилировать Scintilla-у в 64-битный модуль. Еще с час придется потратить на то, чтобы понять, почему Windows постоянно сообщает, что модуль который пытаешься запустить, не является полноценным. Но после того как понимаешь, что виновником является неверный формат манифеста, который генерируется визардом VS 2005 Beta, проблема решается в пять минут. После преодоления данной проблемы все даже начинает работать. Но вот одна закавыка не дает почувствовать удовлетворение от 64-битности. Дело в том, что перекомпилированный модуль не хочет запускаться внутри 32-битных процессов. А по иронии судьбы VS 2005, под которой ведется разработка, тоже является 32-битным процессом. Получается, что можно или запускать 64-битное приложение под отладкой, или настраивать компонент в дизайнере форм VS 2005.
Конечно, можно было потратить еще пару-тройку дней, скомпилировать Scintilla-у в два модуля, 32-битный и 64-битный, создать обертку, которая в зависимости от типа процесса загружала бы нужный модуль и продолжить изучение 64-битного мира, но тут начал действовать еще один немаловажный для меня фактор. Дело в том, что я терпеть не могу половинчатых решений, а это решение никак нельзя назвать полноценным. Хочется, знаете ли, видеть пару-тройку относительно больших полностью управляемых приложений.
В RSDN@Home были еще два неуправляемых компонента. Один – это Web-броузер (ActiveX Microsoft Internet Explorer), а второй – движок БД (Microsoft Jet, он же Access). Однако и ActiveX IE, и Jet имеются в 64-битном виде. Причем для обоих в .NET Framework существуют управляемые обертки. Так что их можно в расчет не брать.
Возможно, я закрыл бы глаза на нечистоту исполнения :), но кроме "любви к чистоте", было и обычное желание заполучить для испытаний управляемые приложения, которые можно без перекомпиляции запускать как в 64-битном, так и в 32-битном режиме. Это позволило бы, в том числе, произвести сравнение быстродействия обоих реализаций Framework-а. Ну и конечно, это очередной шанс проверить возможности новой версии .NET.
Все же не так много продуктов имеют столь определенные критерии и столько достойных реализаций, как редакторы кода с подсветкой синтаксиса. В общем, совокупность факторов сделала создание редактора на второй версии .NET Framework замечательным испытательным стендом и к тому же чертовски интересной задачей.
Однако эксперименты и испытания – это задачи ближайшего будущего. А пока я решил извлечь еще одну выгоду из этого проекта. Я постараюсь создать на его базе несколько статей, описывающих архитектурные и технические решения, примененные при разработке этого компонента. Надеюсь, эти статьи окажутся интересными для многих, изучающих программирование, и кому вообще интересно, как подобный проект можно реализовать средствами .NET.
Для начала надо рассказать о том, что же понималось под словом "редактор", какие возможности требуются от продукта, и в каком виде он должен быть реализован. Ну, и на какие вычислительные мощности он должен ориентироваться.
Под словом "редактор" я понимаю компонент, способный редактировать плоский текст и все форматы, на нем основанные. Основным предназначением редактора было редактирование сообщений в RSDN@Home, а также отображение и редактирование кода в R# (точнее, в его визуальной утилите CodeAnalyzer).
Посему редактор должен поддерживать следующие возможности:
1. Компонент должен быть реализован в виде элемента управления (далее control-а) Windows Forms, т.е. он должен быть наследником (прямым или косвенным) класса System.Windows.Forms.Control.
2. Загрузку текста из текстовой строки.
3. Выгрузку текста в текстовую строку (как целиком, так и по частям).
4. Редактирование текста (как интерактивное, так и посредством API, т.е. методов, предоставляемых control-ом).
5. Работу с буфером обмена (команды Copy, Paste, Cut). Причем в клипборд должен закладываться текст в формате "TEXT" и "UNICODE TEXT".
6. Отключаемый перенос строк по границе окна.
7. Отключаемое отображение "невидимых" символов (пробелов, табуляций, концов строк).
8. Поддержку редактирования с помощью мыши (методом Drag & Drop).
9. Режимы вставки и забивки **.
10. Отображение и редактирование одного и того же текста в нескольких окнах – View *.
11. Подсветку синтаксиса. Под синтаксисом понимается как синтаксис различных языков программирования, так и форматы, аналогичные формату сообщений RSDN@Home. Причем должно быть можно применять различное форматирование к разным частям документа. Так, для сообщений RSDN@Home должна быть возможность подсвечивать участки кода соответствующим этому языку образом, а сам текст – соответственно формату сообщений RSDN.
| ПРИМЕЧАНИЕ * В данной версии возможность не реализована. ** В данной версии возможность реализована не полностью. |
В идеале, описание формата должно задаваться декларативно в специальных файлах. Это позволит упростить добавление новых форматов подсветки.
Подсветка синтаксиса не должна существенно снижать скорость редактирования относительно больших файлов. Поскольку редактор в основном рассчитан на редактирование кода и относительно коротких сообщений, то за максимальный размер текстового файла был взят самый большой заголовочный файл C++, сгенерированный MIDL, и содержащий описание структур данных и интерфейсов Microsoft IE (размер файла около 3.3 МВ).
12. Отображение некоторых сочетаний символов в виде анимированных или обычных картинок (например, :), :)), :))), :xz:). При этом картинки должны выделяться как отдельные символы. Должна быть возможность остановить анимацию и вообще отказаться от отображения сочетаний символов в виде картинок. Эта возможность нужна для удобства редактирования сообщений в RSDN@Home, где с ее помощью будут отображаться "смайлики". Естественно, что сочетания символов должны быть не фиксированными, а задаваемыми извне. Одни и те же сочетания символов в разных частях текста могут как преобразовываться в картинки, так и не преобразовываться. Например, смайлики не должны отображаться внутри кода и строковых литералов, но могут отображаться внутри комментариев. Это означает, что управлять процессом отображения сочетаний символов в картинки должен код, занимающийся подсветкой документа.
13. Навигацию по тексту с помощью клавиатуры и мыши.
14. Работу с выделением при помощи клавиатуры и мыши.
15. Control должен позволять вмешиваться в процесс своей работы. Весь код, связанный с подсветкой конкретного формата, отображением некоторых сочетаний символов в картинки, расстановкой переносов, "умным выделением" и т.п. должен быть выделен в отдельные классы. Должна быть возможность заменить их другими реализациями во время работы.
16. Control должен предоставлять возможность вмешиваться в процесс редактирования или наблюдать за ним. Например, должна иметься возможность реализовать функциональность, аналогичную "Автозамене" (Auto Correct) в Microsoft Word, не изменяя при этом исходный код control-а.
17. Должна быть возможность неограниченное количество раз отменять редактирование (множественное Undo) и повторно применять отмененные команды (множественное Redo). Ограничением количества Undo и Redo должен служить объем доступной приложению памяти. Естественно, что хранение Undo/Redo-информации должно быть в меру компактным, чтобы работа приложения не завершалась скоропостижной смертью в виду нехватки памяти. Однако памяти в наше время довольно много, поэтому параноидальная ее экономия не требуется. В крайнем случае, можно сделать сохранение части Undo-буфера на диск с освобождением занимаемой под выгруженные данные памяти.
Перечисленное выше – это только технические требования или, иными словами, список возможностей. Все эти требования описаны очень поверхностно, и многие детали остались за кадром. В следующих статьях я буду брать каждое из перечисленных требований, расписывать его более подробно и объяснять, как это требование реализовано. Объяснения будут сопровождаться примерами кода. Кроме того, вы сможете найти исходный код всего control-а на прилагающемся к журналу диске или в SVN (svn://rsdn.ru/Editor).
Кроме технических требований, есть и требования иного рода. Так, для себя я определил ряд следующих требований:
Итак, хватит ходить вокруг да около. Перейду к описанию архитектуры control-а. Цель первой статьи цикла - описать (как говорится, по верхам) архитектуру.
Начать, пожалуй, лучше всего с описания того, как редактор хранит данные.
Наверно я не открою секрета, если скажу, что редактор текста – это типичный представитель класса задач, для решения которых прекрасно подходит паттерн MVC (Model-View-Controller, или Модель-Представление-Контроллер). Идея этого паттерна заключается в разделении задачи на модель, описывающую обрабатываемые данные, представление этих данных для пользователя и контроллер, отвечающий за взаимодействие с пользователем (обработку ввода и преобразование его в изменения модели).
MVC - это паттерн, основанный на событиях. Его преимуществами является хорошее структурирование кода и упрощение задачи за счет этого структурирования.
Однако есть у MVC и недостатки. Основной из них – это разнесение связанного кода по классам, отвечающим за модель, представление и контроллер. При этом очень многие операции проходят сквозь несколько классов. В результате тесно связанный между собой код оказывается распределенным по разным классам. Также это приводит к тому, что членами классов становятся не только законные члены, отражающие состояние этого класса, но и члены, отвечающие за состояние некоторого процесса. Например, чтобы понять, как воспринимать пришедшее сообщение о перемещении мыши – как начало DragDrop, или как попытку изменить выделение текста – нужно хранить некое состояние процесса взаимодействия с мышью. Для этого нужно вводить разные состояния, запоминать координаты курсора мыши и т.д. и т.п. Все это негативно сказывается на понятности кода. Однако применение MVC серьезно облегчает решение основной задачи, предоставляя готовые архитектурные решения, что значительно перевешивает недостатки.
На рисунке 1 схематично показано, как редактор использует паттерн MVC.
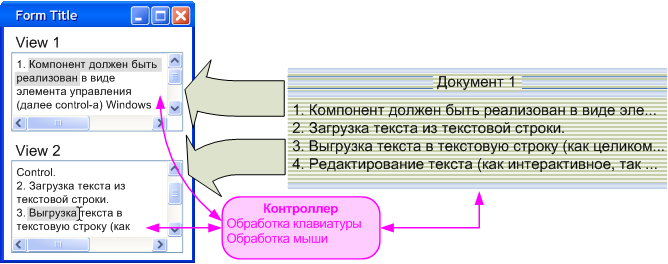
Рисунок 1. Схема применения паттерна MCV в редакторе текста.
Модель – это данные, а данные, которые редактирует редактор – документ. Документ в данном случае должен хранить строки редактируемого текста и некоторую другую, вспомогательную информацию. Такой информацией будут стили и информация о состоянии Styler-а (компонента, в задачи которого входит расстановка стилей), но о них – чуть позже.
Документ должен позволять читать строки текста, изменять их (добавлять новые, удалять и заменять фрагмент текста на другой) и оповещать представления о произошедших изменениях.
Для упрощения работы со строками их целесообразно представлять в виде коллекции. Но так как кроме самих строк нужно еще хранить информацию о стилях и состояние Styler-а, придется хранить не текстовые строки, а ссылки на экземпляры специального класса, хранящего информацию о строке. Это несколько увеличит расход памяти, но значительно упростит работу с данными.
Задачей представления является отображение данных в удобном для пользователя виде. Для одной модели может существовать неограниченное количество представлений. Более того, каждый тип представления может иметь режимы отображения, и эти режимы могут быть по-разному настроены для разных экземпляров конкретного типа представления. Например, представление может переносить длинные, не влезающие по ширине, строки, а может и не переносить, предоставляя механизм прокрутки вбок.
Кроме того, представление может владеть информацией, отсутствующей в документе (модели). Так, каждое представление, участвующее в процессе редактирования, должно хранить информацию о выделенном фрагменте документа.
Как перенос строк, так и информация о выделенном фрагменте текста уникальны для каждого экземпляра представления. Это нужно хотя бы потому, что представления могут иметь разный размер и отображать разные участки документа.
Кстати, это тоже важная информация. Документ может быть большим и не помещаться в представление целиком. При этом представление должно отображать часть документа и позволять позиционироваться на других его частях. Позиционирование тесно связано с областью действия следующего действующего лица – контроллера.
В задачи контроллера входит реакция на действия пользователя, приводящая к изменениям документа или состояния представления. В случае данного текстового редактора функциональность контроллера интегрирована в представление. Это сделано потому, что все взаимодействие ведется всегда через конкретное представление.
Контроллер обрабатывает события, возникающие вследствие нажатия клавиатурных клавиш или события мыши, и преобразует их в изменения представления и/или состояния документа.
Перейдем к непосредственному рассмотрению документа. В Rsdn.Editor документ описывается классом Rsdn.Editor.Document (далее просто Document). Этот класс содержит следующие публичные методы и свойства:
string Text { get; set; } DocumentRowCollection Rows { get; } string GetText(Position<Document> startPosition, Position<Document> endPosition); IView ActiveView { get; } public static void ExecuteCommand(ICommand command) IList<IView> Views { get; } void Delete(Position<Document> start, Position<Document> end); void DeleteBack(Position<Document> nextPosition); void DeleteDirect(Position<Document> start, Position<Document> end); void DeleteBackDirect(Position<Document> nextPosition); void Replace(string text, Position<Document> start, Position<Document> end); void ReplaceDirect(string text, Position<Document> selectionStart, Position<Document> selectionEnd); void Redo(); void Undo(); bool CanRedo { get; } bool CanUndo { get; } IFormatter Formatter { get; set; } |
Названия методов редактирования говорят сами за себя и, по-моему, пояснения здесь бессмысленны.
Методы Redo, Undo, CanRedo, CanUndo ответственны за организацию отмены и повтора изменений. Позже я детально расскажу, как они устроены, а пока что достаточно будет знать, что ExecuteCommand порождает команду, обратную применяемой, и закладывает в Undo-стек. Undo извлекает инвертированную команду из Undo-стека, выполняет ее и помещает ее инверсию в Redo-стек. Метод Redo делает ровно обратное действие. Методы CanRedo, CanUndo позволяют узнать, можно ли в данный момент выполнить Redo и Undo, соответственно.
Последнее свойство, Formatter, хранит в себе реализацию интерфейса IFormatter. Этот интерфейс содержит методы, занимающиеся переносом строк, подготовкой строк (расстановкой стилей на основании сканирования текста документа), выделения слов (используемого для организации перехода на следующее/предыдущее слово и для режима выделения по словам). По умолчанию это свойство содержит ссылку на экземпляр класса DefaultFormatter реализующий форматер, использующийся по умолчанию, но пользователь control-а волен заменить эту реализацию на собственную. Это позволяет, например, сделать для документов определенного типа (хранящих данные определенного типа) более гибкое разбиение на строки, или изменить подсветку синтаксиса.
Как видите, интерфейс документа довольно прост, но, тем не менее, он позволяет делать с документом практически все, что угодно. При этом документ обеспечивает функциональность вроде Redo/Undo, оповещения представлений, генерацию событий и автоматическую расстановку стилей.
Строки документа отличаются от строк, отображаемых в представлении. Строка в представлении может соответствовать части строки документа, так как последняя может быть перенесена, если представление работает в режиме переноса строк, или строка может быть порождена в процессе свертки строк (известном в VS как outlining). В общем, важно, что количество и нумерация строк в представлении могут не совпадать с таковыми в документе.
В достаточно большом документе процесс переноса строк может занимать относительно много времени. Это, возможно, не так критично, если замедление от процесса переноса проявляется только при изменении размеров представления или при открытии документа, но если замедление будет проявляться при каждом редактировании или при каждой перерисовке, то просматривать и редактировать большие тексты в таком редакторе отважится только истинный мазохист.
Чтобы отвадить мазохистов от данного продукта, необходимо позаботиться о кэшировании результатов переноса и свертывания строк. Таким образом, каждое представление должно содержать свой собственный набор строк, среди которых будут виртуальные строки, отображаемые на строки документа как один ко многим, или наоборот, как многое к одному.
Строка документа, не влезающая в текстовую область представления, должна быть разбита на несколько виртуальных строк, которые и будут помещены в кэш представления. В целях экономии памяти такая строка не должна копировать данных исходной строки. Вместо этого она должна хранить ссылку на исходную строку и информацию о том, какая часть исходной строки отображается на данную виртуальную строку.
Иногда случается так, что строка документа влезает в представление, или в представлении выключен перенос строк. При этом в кэш можно переносить исходную строку документа. Чтобы это стало возможным, классы строк имеют общего абстрактного предка – класс Row.Это довольно важный класс, поэтому приведу его целиком:
/// <summary> /// Абстрактный базовый класс строки текста. /// </summary> public abstract class Row { protected internal static AppliedStyle[] _defaultPosStyleArray = new AppliedStyle[0]; /// <summary>Текст строки.</summary> public abstract string Text { get; set; } /// <summary>Длина строки.</summary> public abstract int TextLength { get; } /// <summary> /// Сдвиг строки относительно строки документа. /// Всегда 0 для строк документа. /// </summary> public abstract int OffsetInDocumentRow { get; } /// <summary> /// Список диапазонов стилей, применяемых к строке. /// </summary> public abstract AppliedStyle[] AppliedStyles { get; set; } /// <summary> /// Для строк документа это ссылка на саму себя. Для остальных строк /// это ссылка на строку документа, которая породила данную виртуальную /// строку. /// </summary> public abstract DocumentRow RealDocumentRow { get; } /// <summary> /// Вычисляет высоту строки. /// </summary> /// <param name="defaultFontHelper"> /// Ссылка на описание шрифта, используемого для расчета ширины текста, /// для которого шрифт не задается стилем. /// </param> /// <returns></returns> internal int CalcRowHeight(FontHelper defaultFontHelper) { int h = defaultFontHelper.Height; foreach (AppliedStyle appliedStyle in AppliedStyles) { Style style = appliedStyle.Style; DisplayImage displayImage = style.DisplayImageHandler; if (displayImage != null) h = Math.Max(h, displayImage(Text.Substring(appliedStyle.Pos, appliedStyle.Length)).Height); else { FontHelper fontHelper = style.FontHelper; if (fontHelper != null) h = Math.Max(h, fontHelper.Height); } } return h; } /// <summary> /// Позиция начала строки, которая была бы в случае раскрытия табуляций /// и других невидимых символов. /// У обычных строк эта позиция равна нулю. /// </summary> [DebuggerHidden] public abstract int VirtualPosition { get; } /// <summary> /// Возвращает текст строки с подставленными невидимыми символами. /// </summary> /// <param name="view"> /// Представление, у которого нужно брать информацию о невидимых символах /// и необходимости их отображения. /// </param> /// <returns> /// Строка с подставленными невидимыми символами. /// </returns> [DebuggerHidden] public virtual string GetExpandedText(IView view) { return Utils.ExpandTabs(Text, VirtualPosition, view.TabSize, view.ShowInvisibles, IsEndLine); } /// <summary> /// Говорит о том, содержит ли данная строка окончание строки /// документа. /// Это свойство всегда true у строк документа. /// </summary> [DebuggerHidden] internal virtual bool IsEndLine { get { return true; } } /// <summary> /// Реализация паттерна Посетитель. /// </summary> /// <param name="visitor">Посетитель.</param> public abstract void AcceptVisitor(IRowVisitor visitor); /// <summary> /// Метод ToString в основном нужен для отладки. VS 2005 по умолчанию /// использует его для отображения содержимого объекта. /// </summary> /// <returns></returns> public override string ToString() { // Закомментировано в связи с ошибкой в отладчике VS 2005. //return Utils.ExpandTabs(Text, Position<IView>, 2, true, true); return Text; } } |
Прежде чем перейти к описанию этого класса, стоит упомянуть о его наследниках. Ведь ради них он и создавался.
У этого класса есть несколько наследников. Главным из них является класс DocumentRow. Он описывает строку, хранящуюся в документе (см. свойство Rows класса Document). Еще один наследник HyphenationRow описывает строку, возникшую в результате разбиения строки документа при переносе.
Виртуальное свойство Text класса Row позволяет вне зависимости от реального типа строки получить ее текст. Экземпляры класса DocumentRow хранят текст, ассоциированный с ними, в своем поле _text. Свойство Text класса HyphenationRow создает строку динамически. Для этого каждый экземпляр класса HyphenationRow в поле _documentRow хранит ссылку на строку документа, в результате разбиения которой получилась данная строка. Кроме того, в поле _startOffset хранится отступ от начала строки документа, а в поле _len – длина строки (ведь перенесенная строка является частью строки документа).
Независимость от типа строки позволяет получать текст строки, хранящейся в кэше представления, не обращая внимания на то, какой на самом деле у этой строки тип.
Процесс получения текста у экземпляров HyphenationRow более ресурсоемок (ведь строка каждый раз создается динамически), а со временем могут появиться и другие наследники Row с еще более сложным алгоритмом формирования строки. Так что при обращении к свойству Text нужно быть аккуратным, не впихивать его в огромные или вложенные циклы, и вообще не дергать по пустякам. Очень часто необходимо узнать длину строки. Производить ради этого формирование строки бессмысленно. Чтобы этого не делать, я добавил в класс Row еще одно виртуальное свойство – TextLength, возвращающее длину строки. Оно выглядит несколько лишним, но что не сделаешь ради оптимизации. :)
Свойство OffsetInDocumentRow возвращает отступ строки внутри строки документа. Это свойство используется в функциях пересчета "позиции в представлении" в "позицию в документе". Конечно, можно было вставить в функции пересчета распознавание типов строк (через операторы as/is), но это сделало бы функции пересчета привязанными к конкретным типам строк и, стало быть, не универсальными. Внесение в базовый класс виртуального свойства OffsetInDocumentRow позволило создать полиморфные реализации функций пересчета. Думаю понятно, что у DocumentRow это свойство будет всегда возвращать ноль.
RealDocumentRow - это еще одно виртуальное свойство, позволяющее использовать экземпляры наследников класса Row полиморфно. Экземпляры DocumentRow всегда возвращают в нем ссылку на самих себя, а все остальные наследники Row – ссылку на строку документа, которую они представляют в кэше представления.
Свойство VirtualPosition возвращает так называемую виртуальную позицию. Эта позиция с учетом виртуальных пробелов, которыми мнимо заменяются табуляции при выводе строки на экран. Дело в том, что табуляция не просто заменятся на определенное количество пробелов. Табуляции как бы создают набор невидимых колонок. Табуляция простирается до ближайшей такой колонки. VirtualPosition возвращает позицию символа, как если бы в строке вместо табуляций были подставлены пробелы.
Виртуальное свойство IsEndLine позволяет узнать, содержит ли данная строка конец строки документа. Это свойство используется для отрисовки конца строки.
Функция GetExpandedText позволяет получить текст строки с подставленными невидимыми символами (если в представлении включен соответствующий режим).
Виртуальное свойство AppliedStyles возвращает массив стилей текущей строки. Как и в случае со свойством Text, экземпляр DocumentRow возвращает ссылку на хранимый внутри массив, а экземпляры HyphenationRow рассчитывают этот массив динамически, вычленяя из массива документов только те стили, которые применяются к части строки, представляемой HyphenationRow.Ну и последний из значимых членов этого класса – метод CalcRowHeight. Он подсчитывает высоту строки. Этот метод не виртуальный, но он пользуется для подсчета только виртуальными методами и свойствами данного класса, так что он тоже является полиморфным и дает корректный результат для любого потомка класса Row. Этот метод получает в качестве параметра ссылку на объект класса FontHelper. С ее помощью рассчитывается высота символов, к которым не было применено стилей, или если примененные стили не содержат информации о шрифте. Каждое представление содержит стиль, используемый по умолчанию. При расчете высоты строки как раз и используется FontHelper из этого стиля. О том, что такое FontHelper я расскажу в отдельной статье. Так что пока вам просто нужно запомнить, что это некий объект, кэширующий информацию о шрифте и ускоряющий связанные со шрифтами расчеты. Высота строки непосредственно зависит от шрифтов, примененных в ней, так что и стиль, используемый по умолчанию в представлении, и стили, задаваемые внутри строки, хранят в себе ссылку на соответствующий экземпляр объекта FontHelper.
Представление в Rsdn.Editor реализуется в классе View. Это внутренний класс, недоступный напрямую прикладному коду (вне сборки Rsdn.Editor). Этот класс реализует публичный интерфейс IView. В тех случае, когда есть потребность дать публичную ссылку на View, возвращается ссылка на этот интерфейс. Вот описание этого интерфейса:
public interface IView { ISelection Selection { get; } int TabSize { get; set; } bool ShowInvisibles { get; set; } SimpleStyle DefaultStyle { get; } int TextAreaWidth { get; } Document Document { get; } RowCollection Rows { get; } bool WordWrap { get; set; } void TextUpdated(); void ResetViewInfo(); // Редактирование. bool BeginTextUpdated(Position<Document> StartPosition, Position<Document> endPosition); void EndTextUpdated(Position<Document> StartPosition, Position<Document> endPosition); #region EnsureVisible /// <summary> /// Проверят, видима ли позиция, переданная в качестве параметра. Если /// позиция не видна во view, то она делается видимой. Если позиция /// уже видна во view, то ничего не делается. /// </summary> /// <param name="position">Позиция, которая должна быть видимой.</param> /// <returns>True, если была произведена прокрутка.</returns> bool EnsureVisible(Position<Document> position); /// <summary> /// Проверят, видима ли позиция, переданная в качестве параметра. Если /// позиция не видна во view, то она делается видимой. Если позиция /// уже видна во view, то ничего не делается. /// </summary> /// <param name="position">Позиция, которая должна быть видимой.</param> /// <returns>True, если была произведена прокрутка.</returns> bool EnsureVisible(Position<IView> position); /// <summary> /// Проверят видима ли строка, переданная в качестве параметра. Если /// строка не видна во view, то она делается видимой. Если строка /// уже видна во view, то ничего не делается. /// </summary> /// <param name="viewLine">Строка, которая должна быть видимой.</param> /// <returns>True, если была произведена прокрутка.</returns> bool EnsureVisible(int viewLine); #endregion void UpdatedView(); } |
public interface ISelection { Position<Document> Start { get; set; } Position<Document> End { get; set; } void SetSelection(Position<Document> start, Position<Document> end); void SetSelection(Position<IView> start, Position<IView> end); string Text { get; set; } } |
Как видите, с помощью этого интерфейса можно также считывать выделенный текст или заменять его другим. При этом автоматически производятся необходимые пересчеты и перерисовка представлений.
Как я уже говорил, представление Rsdn.Editor может работать в двух режимах. С переносом строк по границе представления и без оного, но с прокруткой. Так как перенесенные строки в общем случае не соответствуют строкам документа, представление имеет свою собственную коллекцию строк (кэш).
Коллекция строк представления хранит элементы более общего (нежели строки документа) типа – Row. Это позволяет хранить в этой коллекции как строки документа, так и любых других наследников класса Row. Потенциально таких наследников может быть сколько угодно, но на сегодня есть только два работающих типа строк – HyphenationRow и DocumentRow.
При загрузке содержимого нового документа, изменении представления или изменении части имеющегося документа необходимо произвести преобразование строк документа в строки представления. Если в представлении не включен режим переноса строк, то эта операция сводится к банальному копированию строк документа в коллекцию строк представления.
Если же режим переноса строк включен, то запускается механизм переноса строк. Перенос строк – операция, имеющая множество нюансов. Так при переносе кода желательно сделать так, чтобы некоторые конструкции переносились вместе. Например, нежелательно переносить часть идентификатора. При переносе текста правила могут существенно отличаться. Тут уже может потребоваться разбивать слова, но делать это нужно по определенному алгоритму. В общем, это та задача, которую лучше не вшивать жестко в код редактора. Исходя из этого, я решил абстрагироваться от реализации алгоритма переноса и вынес его в форматер (реализующий интерфейс IFormatter). За перенос строк в IFormatter отвечает метод DocumentToViewRows. Вот описание этого метода:
RowCollection DocumentToViewRows(IView view, DocumentRowCollection rows); |
Он получает коллекцию строк документа, и должен возвратить коллекцию строк (наследников класса Row) – таких, чтобы каждая строка влезала по ширине в представление, переданное в этом метод в качестве первого параметра. Если строка не влезает, этот метод должен создать того или иного наследника Row, и разместить в нем часть строки документа. Имеющаяся реализация IFormatter использует в качестве виртуальной строки для переноса экземпляры уже упоминавшегося класса HyphenationRow.
Таким образом, после вызова метода DocumentToViewRows возвращает список строк, влезающих в некоторое представление, так что остается только поместить этот список в представление.
Этот метод можно применять для переноса как всех строк документа, так и некоторого его диапазона. Если нужно произвести перенос некоторого диапазона строк, нужно просто создать временную коллекцию типа DocumentRowCollection и скопировать в нее этот диапазон. Для этого можно воспользоваться методом DocumentRowCollection.GetRangeCollection(). Именно так и поступает редактор, когда он осознает, что изменилась часть документа, и что нужно произвести перенос изменившихся строк. На рисунке 2 приведена схема переноса строк.
Но не все так просто. Перенос строк – не такой простой механизм. Его усложняет то, что нужно рассчитывать ширину участков строки и проверять, влезает ли начальная часть строки в текстовую область представления. Причем на расчет ширины строки влияют стили. Еще более усложняет проблему то, что стили могут пересекаться. Стало быть, перед расчетом ширины текста нужно преобразовать список стилей в плоский список диапазонов стилей. В общем, операция эта – не из простых. Реализация этого алгоритма вынесена в отдельный класс BreakLine, который занимает около 10 килобайт.
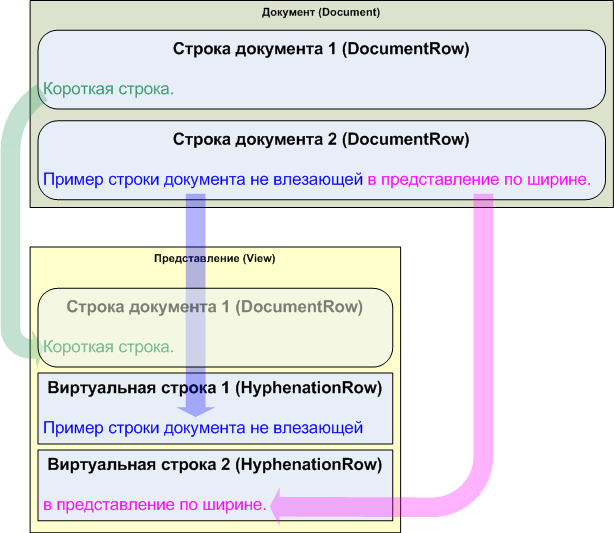
Рисунок 2. Схема переноса строк в представлении.
Можно выделить два типа редакторов:
Их фундаментальное различие состоит в том, что первый тип в качестве модели хранит просто текст, а второй хранит специальный формат, в котором текст – это не более чем частный случай.
К первому случаю относятся почти все редакторы кода и такие легендарные вещи, как Notepad. Ко второму – такие текстовые процессоры, как Microsoft Word, Star/Open Offiсe Word, все системы верстки и т.п.
Rsdn.Editor относится к первому типу. Однако даже редакторы первого типа требуют некой информации о стилях. Ведь, например, редактор кода должен подкрашивать исходные коды программ (выделять строки и комментарии, подкрашивать ключевые слова и т.п.). Конечно, можно попытаться делать это в реальном времени, но, к сожалению, на сегодня процессоры еще не столь мощны, чтобы позволить на каждый чих производить лексический и тем более синтаксический разбор файла относительно большого размера. Чтобы не тратить лишних тактов на постоянный разбор текста, результаты разбора кэшируются.
Кстати, есть еще одна причина для кэширования результатов разбора. Не дело редактора заниматься разбором текста и определять, что и как должно быть распарсено. Этим должен заниматься отдельный компонент – Styler. Такое решение позволяет заменять Styler и получать возможность подсвечивания текста разных форматов. Естественно, что Styler и редактор должны быть максимально независимы друг от друга. Список стилей позволяет «развязать» их.
Почему стиль? Все очень просто. Подсветка синтаксиса может быть разной. У текста может меняться цвет фона, размер и начертание шрифта, цвет символов, появляться подчеркивание волнистой линией и т.п. Задавать все эти характеристики по отдельности можно, но неудобно. Намного удобнее оформить все элементы оформления в стиль и применять к участкам текста уже стиль.
Стили в Rsdn.Editor представлены иерархией классов, корнем которой является абстрактный класс Style. Его наследниками являются классы:
На рисунке 3 приведена диаграмма классов для иерархии классов стилей. Эту диаграмму также можно созерцать в интерактивном виде внутри проекта. Ее имя StyleDiagram.cd.
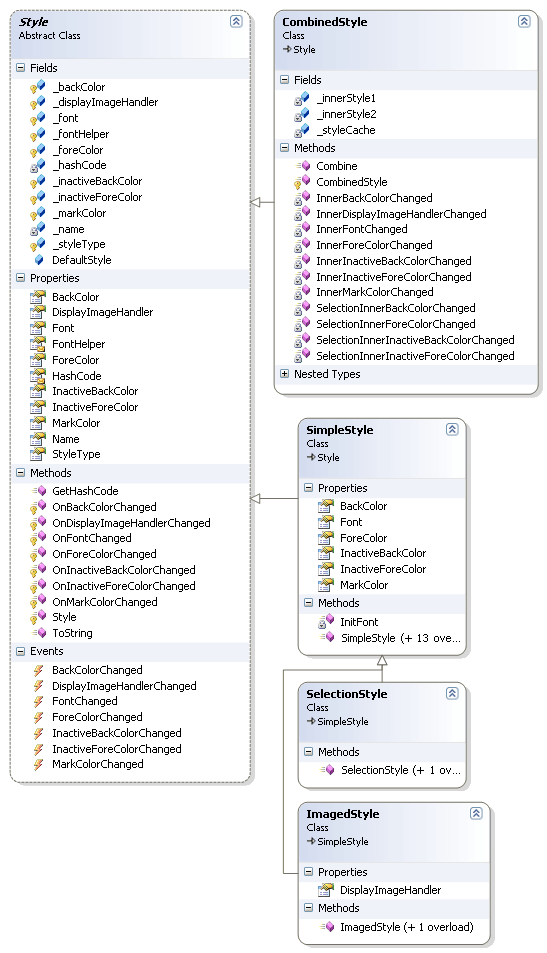
Рисунок 3. Иерархия классов стилей.
Базовый класс Style позволяет работать со стилями полиморфно. Прикладному коду совершенно все равно, какой конкретно класс он использует.
Style не позволяет изменять свойства стиля (так как они доступны только для чтения), но все переменные, хранящие значения свойств (кроме _name), доступны наследникам и могут быть изменены в них. SimpleStyle пользуется этой особенностью и расширяет класс Style набором конструкторов, через которые можно задать значения свойств, и переопределяет свойства класса (с модификатором new), делая их доступными для записи. При этом свойства класса SimpleStyle модифицируют переменные базового класса, а так как этими же переменными пользуются свойства базового класса, создается впечатление, что SimpleStyle изменяет сигнатуру свойств.
Кроме всего прочего, Style объявляет набор событий, которые должны генерироваться при модификации стиля, и виртуальные функции для генерации этих событий. Например, в случае изменения шрифта наследник обязан вызвать метод OnFontChanged, который сгенерирует событие FontChanged. Это позволяет при комбинировании стилей отслеживать модификацию комбинируемых стилей и модифицировать кэш CombinedStyle.
Кроме свойств, описывающих атрибуты стиля, базовый класс описывает свойство Name – имя стиля (которое не может изменяться со временем), и переопределяет функцию GetHashCode. Имя задает уникальный идентификатор стиля. Даже комбинированный стиль имеет уникальное имя, получаемое конкатенацией всех имен комбинируемых стилей. Переопределение GetHashCode позволяет хранить ссылки на стили в хэш-таблице и очень быстро находить их. У SimpleStyle GetHashCode возвращает хэш-код имени стиля (для ускорения работы записываемый в скрытое поле при инициализации стиля и доступный через не виртуальное свойство HashCode). CombinedStyle возвращает сумму хэш-кодов комбинируемых стилей. SelectionStyle и ImagedStyle наследуют реализацию генерации хэш-кода у класса SimpleStyle.
SelectionStyle содержит всего лишь два дополнительных конструктора, упрощающих инициализацию. Главное в этом классе – не код, а то что он есть :). Вся обработка, связанная с выделением, находится в CombinedStyle. Причем то, что стилями выделения автоматически становятся любые стили, комбинируемые с CombinedStyle, привело к тому, что пришлось ввести специальное свойство StyleType одноименного типа. Конструктор класса SelectionStyle выставляет его в StyleType.Selection, а все остальные (за исключением CombinedStyle) – в StyleType.Normal. CombinedStyle, основываясь на значении этого свойства, комбинирует стили по-разному (отдавая приоритет цвету фона и текста выделения). Естественно, что стиль, получающийся в результате комбинации со стилем, у которого свойство StyleType возвращает StyleType.Selection, тоже становится стилем выделения, и его свойство StyleType тоже возвращает значение StyleType.Selection.
На рисунке 4 показаны перекрывающиеся стили Keyword и Selection, в результате чего получается комбинированный стиль.

Рисунок 4. Демонстрация комбинации стилей.
Если внимательно приглядеться к описанию класса Row (листинг -2), то можно заметить, что у строки есть свойство AppliedStyles:
public abstract AppliedStyle[] AppliedStyles { get; set; } |
Это свойство возвращает массив стилей, примененных к строке. Тип AppliedStyle – это структура, содержащая ссылку на стиль и информацию об участке строки, к которому должен применяться стиль. На рисунке 5 показана диаграмма структуры AppliedStyle.
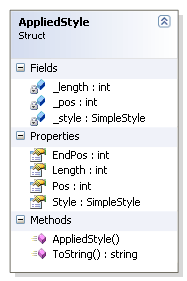
Рисунок 5. Структура AppliedStyle.
Как видите, AppliedStyle содержит стиль, его позицию в тексте и длину участка на который распространяется стиль. Как я уже сказал выше, стили могут пересекаться, и Styler-у не нужно заботиться о создании комбинированных стилей. Это значительно упрощает создание Styler-ов, а также ручную модификацию и чтение стилей строки. К сожалению, это значительно усложняет работу со стилями. Если и можно создать алгоритмы для работы с перекрывающимися стилями, хранимыми таким образом, то они будут очень запутанными и громоздкими.
Чтобы избавиться от возни со столь неудобными для обработки перекрывающимися стилями, была создана функция ToStyledRange:
internal static StyledRange[] ToStyledRange(AppliedStyle[] poss, Style styleDefault, string text, bool populateStrings) |
Она преобразует AppliedStyle[] в StyledRange[]. StyledRange (см. рисунок Ошибка! Источник ссылки не найден.) – это структура, очень похожая на AppliedStyle, но содержащая также текст и позволяющая ссылаться не только на SimpleStyle (как это делает AppliedStyle), но и на любой стиль (наследников Style). Массив StyledRange уже не может содержать участков с перекрывающимися стилями. Если какие-то стили в AppliedStyle[] перекрывались, для их сочетания создаются комбинированные стили, которые и помещаются в StyledRange[]. Таким образом, StyledRange описывает диапазон строки, к которому применяется один и только один стиль.
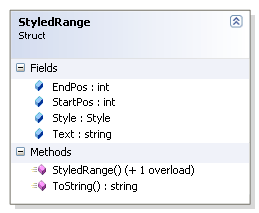
Рисунок 6. Структура StyledRange.
Попробую продемонстрировать сказанное выше на примере. Чтобы подсветить синтаксис так, как показано на рисунке 4, нужно создать вот такой массив AppliedStyle:
new AppliedStyle[] { new AppliedStyle(KeywordStyle, 0, 5), // стиль, позиция, длина new AppliedStyle(SelectionStyle, 2, 11) } |
Первый элемент этого массива описывает стиль, подсвечивающий ключевое слово «using». 0 – это позиция начала применения стиля, 5 – длина отрезка, к которому применяется стиль. Второй элемент массива описывает стиль выделения: оно начинается с индекса 2 и продолжается следующие 11 символов. Нетрудно заметить, что эти два символа пересекаются. Часть слова «using» («ing») попадает в область, на которую распространяется выделение. Стиль выделения имеет высший приоритет, поэтому цвет и фон для подстроки «ing» берутся именно из него. Но, так как стиль выделения не определяет шрифт, «ing» остается выделенным жирным. Другими словами, диапазон строки, начинающийся с символа с индексом 2 и продолжающийся до символа с индексом 4 (т.е. приходящийся на «ing»), попадает под влияние сразу двух стилей.
Функция ToStyledRange преобразует описанный выше массив AppliedStyle в:
new StyledRange[] { new StyledRange(KeywordStyle, "us", 0, 1), new StyledRange(KeywordSelectionCombinationStyle, "ing", 2, 4), new StyledRange(SelectionStyle, " System.Collections;", 5, 24), } |
KeywordSelectionCombinationStyle – это динамически формируемый стиль, получающийся в результате комбинации стилей KeywordStyle и SelectionStyle. Кстати, прошу заметить, что все имена стилей вымышлены и все совпадения с реальными персонажами случайны.
Функция ToStyledRange довольно длинна, так что прежде, чем приводить ее код, я лучше опишу ее алгоритм. Сначала стили из отрезков, выражаемых в терминах начала отрезка и его длины, преобразуются в точки (начала и конца отрезка, к которому применяется стиль). Этот процесс схематически изображен на рисунке Ошибка! Источник ссылки не найден..
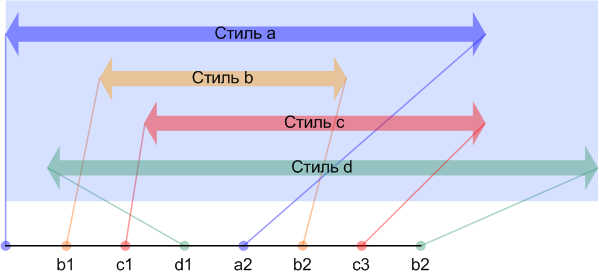
Рисунок 7. Преобразование списка отрезков текста, к которым применяются стили, в список точек начала и окончания отрезков.
Для каждого отрезка (стиля) создается по две точки (позиция начала отрезка и позиция конца отрезка). Так как добавляются эти точки в случайном порядке (добавляются то они последовательно, но стили могут располагаться в массиве совершенно хаотично, да и некоторые стили могут кончаться позже, чем другие, независимо от того, где они начались), необходимо отсортировать эти точки по возрастанию позиции в тексте. Но есть одна проблема. Для формирования комбинированных стилей нужно чтобы даже после сортировки можно было сказать, к какому AppliedStyle относится та или иная точка. Для этого точка должна хранить индекс AppliedStyle, который явился основанием для ее создания. Кроме того, нужно отличать точки, определяющие начало отрезка, и точки, определяющие конец. Это можно сделать, введя в тип, определяющий точку, соответствующий флаг. Но вернемся к алгоритму. После сортировки список точек будет выглядеть так, как это показано на рисунке Ошибка! Источник ссылки не найден..
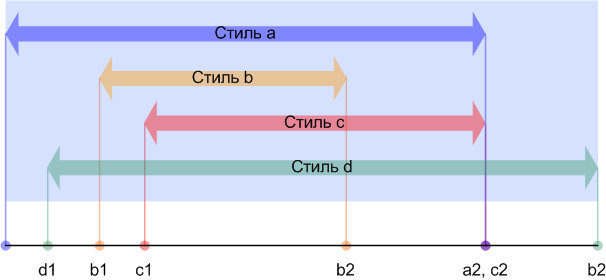
Рисунок 8. Отсортированный список отрезков стилей.
В результате промежутки между ближайшими точками определяют диапазоны текста, к которому применяется только один простой или комбинированный стиль. На рисунке Ошибка! Источник ссылки не найден. можно наблюдать список сформированных диапазонов.
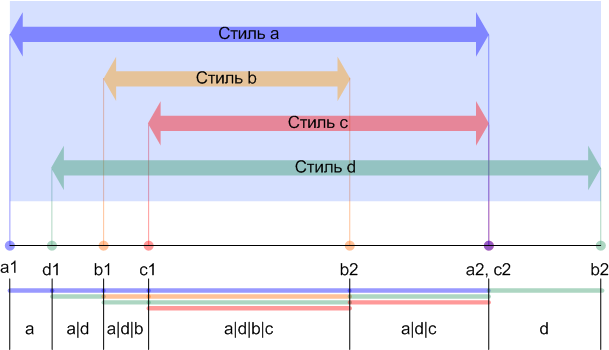
Рисунок 9. Список отрезков с непрерывными стилями.
Нетрудно заметить, что только стили «a» и «b» перекочевали в список диапазонов в неизменном виде. Остальные стили были скомбинированы, в результате чего образовалось еще четыре комбинированных стиля («a|d», «a|d|b», «a|d|b|c» и «a|d|c»).
Комбинация стилей – задача хотя и быстрая, но уж очень часто она производится. Чтобы ускорить этот процесс, комбинированные стили кэшируются в специальной хэш-таблице.
Если диапазон имеет нулевую длину (две или более точки приходятся на одну позицию в тексте), его нужно удалить. Исключением является пустой диапазон в пустой строке.
Ну, вот и все. В таком виде стили можно очень легко использовать для расчетов и отрисовки в редакторе. Почему такой вид удобнее? Все очень просто. Теперь можно бежать по строке, перебирая диапазоны и символы в них, и производя нужные расчеты или отрисовку. Например, чтобы пересчитать экранные координаты в текстовые координаты представления, нужно просто перебрать текст в StyledRange строки представления, и вычислить и суммировать ширину символов, используя шрифт из StyledRange.
Думаю, что на этом этапе задача функции ToStyledRange ясна, и даже ясен ее алгоритм. Остается заметить, что к этой функции есть еще одно небольшое требование. Она должны быть максимально быстрой. Дело в том, что она применяется очень часто. Каждая отрисовка, редактирование, перенос строк в представлении (например, произошедший в результате изменения размеров окна) приводят к многократным вызовам этой функции. Самая большая нагрузка на эту функцию падает при переносе строк большого документа. Конечно, можно обманывать пользователя, производя сначала перенос только видимых строк, а перенос всех строк документа выполнять в отдельном потоке, но это дополнительный и довольно непростой код. Учитывая то, что современные процессоры отнюдь не детские игрушки, и что разумным пределом документа является где-то 3-4 мегабайта, а также свое твердое убеждение, что хороший код не должен быть сложным :), я решил, что лучше сделать данную функцию максимально быстрой, а оптимизации вроде отложенного форматирования документа отложить до времен, когда это действительно понадобится.
Позиция стиля описывается структурой StylePosition. Ее описание приведено в листинге 5.
#region ToStyledRange /// <summary> /// Позиция стиля в строке. Используется для преобразования /// массива AppliedStyle в массив StyledRange. /// </summary> private struct StylePosition { /// <summary>Позиция в тексте.</summary> public int PosInText; /// <summary>Индекс в массиве AppliedStyle-ей.</summary> public int IndexInAppliedStyles; /// <summary> /// Если true - это описание начальной позиции. /// Если false - конечной. /// </summary> public bool Start; /// <summary> /// Стиль, ассоциированный с AppliedStyle, на который /// указывает индекс IndexInAppliedStyles. /// Это свойство используется в отладочных целях. /// </summary> public Style Style; public override string ToString() { return "Start: " + Start + "; PosInText " + PosInText + "; IndexInAs " + IndexInAppliedStyles + "; " + "Style: " + Style + "; " ; } } |
Реализация функции ToStyledRange приведена в листинге -6. Она снабжена исчерпывающими комментариями, так что поясню только самые тонкие места.
// Чтобы облегчить сборщику мусора работу, временные массивы // используются повторно. Чтобы это не вызвало проблем с // потокобезопасностью, они помечаются как локальные для потока. // Атрибут ThreadStatic говорит CLR, что нужно создать по отдельной // копии переменной для каждого потока. /// <summary> /// Кэш для временного динамического массива стилевых диапазонов. /// Используется в функции ToStyledRange. /// </summary> [ThreadStatic] private static List<StyledRange> _ranges = new List<StyledRange>(16); /// <summary> /// Кэш для временного динамического массива индексов стилей. /// Используется в функции ToStyledRange. /// </summary> [ThreadStatic] private static List<int> _indices = new List<int>(16); /// <summary> /// Преобразует массив стилей, применяемых к строке (AppliedStyle[]), /// в массив стилевых диапазонов (StyledRange[]). В отличие от /// AppliedStyle[], в StyledRange[] стили не могут перекрываться. /// Если в AppliedStyle[] стили перекрываются, то в StyledRange[] /// генерируется стилевой диапазон, содержащий комбинацию стилей. /// </summary> /// <param name="styles"> /// Список стилей, применяемых к сроке. /// </param> /// <param name="styleDefault"> /// Стиль, применяемый, если никаких стилей не задано. Также /// используется для задания значений, которые не указаны в стиле. /// В любой комбинации стилей присутствует и этот стиль. /// </param> /// <param name="text"> /// Текст строки, к которой принадлежит список стилей. /// </param> /// <param name="populateStrings"> /// Говорит о том, нужно ли заполнять поле Text в структурах StyledRange. /// </param> /// <returns> /// Список стилевых дипазонов, соответствующий AppliedStyle[]. /// </returns> internal static StyledRange[] ToStyledRange(AppliedStyle[] styles, Style styleDefault, string text, bool populateStrings) { int textLen = text.Length; // Если это пустая строка, в которой присутствует один стиль, // то это особый случай. if (textLen == 0 && styles.Length == 1 && styles[0].Length == 0) { Debug.Assert(styles[0].Pos == 0); return new StyledRange[] { new StyledRange( CombinedStyle.Combine(styles[0].Style, styleDefault), text, 0, 0) }; } if (styles.Length == 0) return new StyledRange[] { new StyledRange(styleDefault, text, 0, textLen - 1) }; // Преобразуем список стилей в отсортированный список позиций стилей // в строке. Для каждого стиля в таком списке добавляется позиция // начала его применения в тексте и позиция конца применения. StylePosition[] stylePositions = ToStylePosition(styles, textLen); // Теперь нужно пройтись по отсортированному списку позиций и // сформировать список последовательно идущих диапазонов стилей. // Список диапазонов стилей. Его формирование и есть цель // данной функции. List<StyledRange> ranges = _ranges; ranges.Clear(); // Индексы стилей, входящих в текущую комбинацию стилей. // Когда встречается начальная позиция стиля, индекс этого стиля // добавляется в indices. Когда конечная - удаляется. // При каждом изменении списка стилей производится создание // комбинированного стиля (состоящего из комбинаций стилей, входящих // в данный момент в indices), который помещается в ranges. List<int> indices = _indices; indices.Clear(); // Если первый стиль начинается не в самом начале строки... if (stylePositions[0].PosInText != 0) // ...добавляем специальный диапазон-заглушку, содержащий // стиль, используемый по умолчанию. ranges.Add(new StyledRange(styleDefault, 0)); // Индекс последний позиции (точки). int endIndex = stylePositions.Length - 1; // Перебираем все позиции стилей... for (int i = 0; i < stylePositions.Length; i++) { StylePosition stylePos = stylePositions[i]; // Если эта позиция открывает новый стилевой диапазон... if (stylePos.Start) // ...запоминаем индекс применяемого стиля. indices.Add(stylePos.IndexInAppliedStyles); else // Удаляем индекс стиля из списка индексов активных стилей. indices.Remove(stylePos.IndexInAppliedStyles); // Если последняя позиция, или если позиция не совпадает со // следующей позицией, и позиция не выходит за пределы текста. if ((i == endIndex || stylePos.PosInText != stylePositions[i + 1].PosInText) && stylePos.PosInText < textLen) { // Формируем комбинированный стиль из стилей, накладываемых // на добавляемый диапазон. Style style = styleDefault; for (int j = 0; j < indices.Count; j++) style = CombinedStyle.Combine(styles[indices[j]].Style, style); // Добавляем новый стилевой диапазон. ranges.Add(new StyledRange(style, stylePos.PosInText)); } } StyledRange[] styledRanges = ranges.ToArray(); if (styledRanges.Length > 0) { // Заполняем конечную позицию диапазонов. Она равна начальной // позиции следующего диапазона минус единица. for (int i = 1; i < styledRanges.Length; i++) styledRanges[i - 1].EndPos = styledRanges[i].StartPos - 1; // Последняя позиция должна быть равна длине текста. styledRanges[styledRanges.Length - 1].EndPos = textLen - 1; } if (populateStrings) // Инициализируем поле Text в каждом StyledRange. StyledRangeInitText(text, styledRanges); return styledRanges; } |
Сначала с помощью вспомогательной функции ToStylePosition массив AppliedStyle преобразуется в массив позиций (StylePosition[]). Эта функция просто заполняет динамический массив позиций и сортирует его с помощью специальной функции сортировки, рассчитанной на максимально быструю сортировку. В качестве алгоритма сортировки я использовал CountingSort (он тоже приведен в листинге -7). Это алгоритм с практически линейной характеристикой, рассчитанный на сортировку элементов с целочисленным ключом. Для повышения производительности я не стал реализовывать его полиморфно (с использованием объектов компараторов или делегатов). Не думал, что столь экзотичный алгоритм окажется полезным в реальном приложении, но как говориться удивительное рядом :). Все ограничения этого алгоритма оказались приемлемыми для этого случая.
Еще одной оптимизацией, которую я применил в функции ToStyledRange, явилось использование [ThreadStatic]-переменных. Этот атрибут приказывает компилятору создавать отдельные копии для статических переменных в каждом потоке, где они используются. Этим атрибутом я пометил массивы _ranges и _indices. Это рабочие массивы, используемые внутри функции ToStyledRange. Поначалу я создавал их динамически (при каждом вызове ToStyledRange), но это по показаниям профайлера приводило к более быстрому забиванию GC-кучи, что негативно сказывалось на производительности. Применение [ThreadStatic] не бесплатно. Скажу больше, использование этого атрибута не сильно быстрее создания объекта динамически, и я долго сомневался, нужно ли его использовать, но профайлер окончательно убедил меня :). Как вариант можно было бы сделать массивы просто глобальными, так как пока что ToStyledRange не вызывается из разных потоков. Но это не очень хорошее решение, так как нарушается принцип «не удивлять». Все же ToStyledRange – это функция. И негоже ей создавать побочные эффекты.
Ну, что это я все про оптимизации? Пора продолжить описывать малопонятные моменты функции ToStyledRange. Одним из таких моментов может стать массив indices. Боюсь, не всем будет понятно его назначение. Дело в том, что к StyledRange может применяться одновременно несколько простых стилей, но он обязан иметь только одну ссылку на стиль. Когда на отрезок приходится более одного стиля, их нужно скомбинировать, получив в итоге один комбинированный стиль (CombinedStyle). Первым моим решением было комбинировать стили при появлении нового отрезка, помещать их в стек, и после того как стиль кончается, извлекать стиль из стека. Но оно быстро отпало, так как я понял, что стили могут кончаться не в той последовательности, что появлялись (тут вообще нет никаких зависимостей). Поэтому мне пришлось вместо стека использовать обычный массив и удалять ставший ненужным стиль из него. Чтобы не тратить лишнее время и ресурсы, храня в массиве копию AppliedStyle, я решил хранить в массиве только индекс AppliedStyle. Так вот, массив indices как раз и хранит этот список индексов. При появлении вхождения нового стиля в этот массив помещается индекс этого стиля, а при появлении вхождения, говорящего о том, что стиль кончился, его индекс удаляется из массива. При этом, если следующее вхождение стиля не начинается с той же позиции, все стили, индексы которых в данный момент находятся в массиве indices, комбинируются, и получившийся стиль помещается в новый стилевой отрезок (StyledRange).
/// <summary> /// Инициализирует поле Text в StyledRange. /// </summary> /// <param name="text">Текст строки.</param> /// <param name="styledRanges">Список стилевых диапазонов.</param> private static void StyledRangeInitText(string text, StyledRange[] styledRanges) { int textLen = text.Length; if (styledRanges.Length == 1) styledRanges[0].Text = text; else { for (int i = 0; i < styledRanges.Length; i++) { int start = styledRanges[i].StartPos; int next = i + 1; if (next < styledRanges.Length) styledRanges[i].Text = text.Substring( start, styledRanges[next].StartPos - start); else styledRanges[i].Text = text.Substring( start, textLen - start); } } } /// <summary> /// Преобразует список стилей (AppliedStyle[]) в отсортированный список /// позиций стилей в строке (StylePosition[]). Для каждого стиля в таком /// списке добавляется позиция начала его применения в тексте и позиция /// конца применения. /// </summary> /// <param name="appliedStyles"> /// Список стилей, которые нужно преобразовать в список позиций /// начала и конца стиля в строке. /// </param> /// <param name="textLen">Длина строки.</param> /// <returns></returns> private static StylePosition[] ToStylePosition( AppliedStyle[] appliedStyles, int textLen) { // В этом массиве будут находится ссылки на стилевые диапазоны, // отсортированные по возрастанию позиций в тексте. В этот список войдут как // начальные позиции, так и конечные (начальная плюс длина). // Поэтому массив должен быть вдвое больше, чем appliedStyles. StylePosition[] stylePositions = new StylePosition[appliedStyles.Length << 1]; // Формируем массив позиций стилей в строке. for (int i = 0; i < appliedStyles.Length; i++) { // Формируем позицию начала стиля. AppliedStyle appliedStyle = appliedStyles[i]; StylePosition ndx; ndx.PosInText = appliedStyle.Pos; ndx.IndexInAppliedStyles = i; ndx.Start = true; ndx.Style = appliedStyle.Style; stylePositions[i] = ndx; // Формируем позицию конца стиля. ndx.PosInText = appliedStyle.Pos + appliedStyle.Length; ndx.IndexInAppliedStyles = i; ndx.Start = false; ndx.Style = appliedStyle.Style; // Вставляем конец стиля во вторую половину массива. stylePositions[i + appliedStyles.Length] = ndx; } return Utils.CountingSort(stylePositions, textLen, 0); } /// <summary> /// Сортирует массив StylePosition по возрастанию /// значения поля PosInText. /// В некоторых случаях, когда количество элементов меньше или равно двум, /// функция производит сортировку по месту. В противном случае возвращается /// сортированная копия массива. Функция является стабильной, т.е. если /// встречаются одинаковые элементы, то в результирующем массиве их позиция /// в исходном массиве сохраняется. /// </summary> /// <param name="array"> /// Массив, подлежащий сортировке. /// </param> /// <param name="max"> /// Максимальное значение ключа, которое может встретиться в массиве.</param> /// <param name="min"> /// Минимальное значение ключа, которое может встретиться в массиве.</param> /// <returns>Сортированный массив.</returns> static StylePosition[] CountingSort(StylePosition[] array, int max, int min) { switch (array.Length) { case 0: case 1: return array; case 2: if (array[0].PosInText > array[1].PosInText) { StylePosition temp = array[0]; array[0] = array[1]; array[1] = temp; } return array; } int i; int range = max - min + 2; int[] count = new int[range]; StylePosition[] scratch = new StylePosition[array.Length]; for (i = 0; i < array.Length; i++) { int c = array[i].PosInText + 1 - min; count[c]++; } for (i = 1; i < count.Length; i++) count[i] += count[i - 1]; for (i = 0; i < array.Length; i++) { int c = array[i].PosInText - min; int s = count[c]; scratch[s] = array[i]; count[c]++; } return scratch; } |
Если параметр populateStrings функции ToStyledRange имеет значение true, в конце функции вызывается функция StyledRangeInitText, которая инициализирует поле Text каждой структуры StyledRange в текст, соответствующий этому отрезку.
Итак, что такое стиль и как с ним работать, вам уже должно быть понятно. Также вы должны понимать, как происходит разбиение строк на виртуальные при переносе, и чем строки представления отличаются от строк документа.
Давайте теперь зададимся вопросом, а как же жить в этом зверинце? Ведь есть и координаты представления, и строки представления, и строки документа, и даже стили в строках документа. Это же можно повеситься на одних только пересчетах! Но не все так печально. Главное, что программист должен помнить – это то, что от всего на свете можно абстрагироваться. И единственное, о чем действительно нужно думать, чтобы все не переусложнить.
Так как же абстрагироваться от всего этого при расчетах? Для начала нужно понять, что за единицы измерения мы хотим использовать. Вот их список:
С последним пунктом все понятно. Для него логично применять банальную структуру System.Drawing.Point (далее просто Point). А как быть с позициями в тексте? Может быть, тоже воспользоваться для их хранения Point? В принципе, в X можно хранить позицию символа, а в Y – строки. Чем не решение? А ничем не решение. Это моментально приведет к тому, что любой, кто читает этот код, начнет путаться. Что еще хуже, компилятор ничем не сможет нам помочь. Ведь для него Point, в котором хранятся экранные координаты, ничем не будет отличаться от Point-а, в котором хранится позиция в документе или, скажем, представлении.
Чтобы подобных проблем не возникало, лучше завести для каждого вида координат отдельный тип. По сути они мало чем будут отличаться, но для компилятора это будут разные типы, да и человек по названию легко отличит их.
Чтобы избавиться от необходимости поддерживать две идентичные реализации, я создал обобщенные реализации структур Position<T> и Range<T> (см. рисунок 10). Первая описывает позицию в тексте, а вторая – диапазон (состоящий из двух позиций). Параметр типа никак не используется в этих структурах. Он нужен только для того, чтобы можно было сделать по два закрытых типа. Одну пару – для представления позиций в представлении, вторую – для представления позиций в документе. Я параметризовал их публичными типами представления (IView) и документа (Document). Жаль, что в C# не поддерживается нечто вроде глобального using-а или typedef-а. Не то можно было бы переименовать Position<IView> в ViewPosition, а Position<Document> – в DocumentPosition (как это было изначально). Ну, да лучше так чем никак.
| ПРИМЕЧАНИЕ Здесь есть один интересный момент, так что позволю себе немного отвлечься. Когда я создавал эти структуры, то не сразу принял решение создать обобщенную реализацию. Во мне боролись два чувства – чувство прекрасного и любовь к искусству :). Одно говорило, что хорошо бы иметь читаемые имена вроде DocumentPosition, а другое говорило, что негоже ради мнимой красоты делать две идентичные структуры. Сначала я поддался первому чувству и, воспользовавшись паттерном проектирования Copy/Past, создал две идентичные структуры, но при написании этих строк любовь к искусству взяла верх, и я создал одну generic-реализацию этой структуры (лишь бы не передумать :) ). Ну, да ладно. |
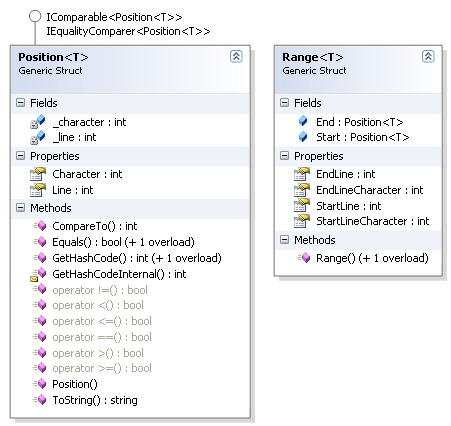
Рисунок 10. Структуры Position<T> и Range<T>, описывающие позицию в тексте.
Как видно из рисунка 10, позиция определяется строкой (свойство Line) и символом (свойство Character). В общем, все просто. Кроме того, позиции можно сравнивать, для чего присутствуют перегруженные операторы и реализация интерфейсов System.IComparable< Position<T>> и System.Collections.Generic.IEqualityComparer<Position<T>>.
Для преобразования координат и позиций в представление были добавлены функции:
public HitTestInfo HitTest(Point point, bool isUseBestFit); public Rectangle? ToLocation(Position<IView> viewPosition); public Position<Document> ToDocument(Position<IView> viewPosition); public ViewRange ToView(Position<Document> position); public ViewRange ToView(Range<Document> position); |
| ПРИМЕЧАНИЕ Все функции находятся в файле Rsdn.Editor\ObjectModel\View\View.Translate.cs. Вообще файлы View.*.cs – это части partial-класса View. Он разбит на несколько файлов, так как имеет довольно большой интерфейс. По именам файлов довольно просто найти нужные функции. Если найти функцию по файлам не удается, то можно воспользоваться средствами, предоставляемыми VS 2005 (выпадающим комбобоксом в редакторе и закладкой Class View). |

Рисунок 11. Структура HitTestInfo.
Код этих функций слишком велик и пока не очень хорошо отрефакторен, чтобы публиковать его в статье. Так что я приведу только часть кода и ограничусь словесным описанием остальных алгоритмов.
Преобразование позиции в представлении в позицию в документе состоит из поиска соответствующей строки и расчета символа в ней. ToDocument() самая простая функция из всех функций преобразования, так что я приведу ее целиком:
/// <summary> /// Преобразует Position<IView> в Position<Document>. /// </summary> /// <param name="viewPosition">Виртуальная позиция /// (в строках и символах вида)</param> /// <returns>Позиция в документе.</returns> public Position<Document> ToDocument(Position<IView> viewPosition) { Row viewRow = Rows[viewPosition.Line]; return new Position<Document>( Document.Rows.IndexOf(viewRow.RealDocumentRow), viewPosition.Character + viewRow.OffsetInDocumentRow); } |
Как видите, поиск индекса соответствующей строки осуществляется довольно тривиально. Сначала получается строка документа (ссылка на которую доступна в каждой строке через свойство RealDocumentRow). Затем вычисляется ее индекс. После этого к позиции символа добавляется сдвижка от начала реальной строки (доступная через свойство OffsetInDocumentRow).
Преобразование позиции в документе в позицию в представлении немного более объемно:
/// <summary> /// Преобразует Position<Document> в Position<IView>. /// </summary> /// <param name="documentPosition">Позиция в документе.</param> /// <returns>Позиция в представлении.</returns> public Position<IView> ToView(Position<Document> documentPosition) { RowCollection rows = Rows; DocumentRow docRow = Document.Rows[documentPosition.Line]; // Индекс строки в представлении. int viewIndex = rows.IndexOfDocumentRow(docRow); if (viewIndex < 0) throw new ArgumentOutOfRangeException("documentPosition", documentPosition, "The Line of position out of range."); // Позиция символа в документе. int docChPos = documentPosition.Character; Row viewRow; // В представлении присутствуют несколько строк, соотвествующих // строке документа. Ищем строку представления, содержащую позицию // символа, соответствующую переданной позиции. for (int i = viewIndex, count = rows.Count; i < count; i++) { viewRow = rows[i]; if (viewRow.RealDocumentRow != docRow) { int line = documentPosition.Line; if (line < 0 || line > Document.Rows.Count) throw new Exception("Incorrect Line in the documentPosition."); int ch = documentPosition.Character; if (ch < 0 || ch > Document.Rows[line].TextLength) throw new Exception( "Incorrect Character in the documentPosition."); throw new Exception( "The implementation of IFormatter. DocumentToViewRows is bad."); } // Отступ начала строки представления в строке документа. int start = viewRow.OffsetInDocumentRow; int viewPos = docChPos - start; // Если нашли строку представления... if (viewPos <= viewRow.TextLength) return new Position<IView>(i, viewPos); } throw new ArgumentOutOfRangeException("documentPosition", documentPosition, "The Character of position out of range."); } /// <summary> /// Преобразует Position<Document> в Position<IView>. /// </summary> /// <param name="range">Диапазон в документе.</param> /// <returns>Диапазон в представлении.</returns> public Range<IView> ToView(Range<Document> range) { Position<IView> start = ToView(range.Start); if (range.Start == range.End) return new Range<IView>(start, start); else return new Range<IView>(start, ToView(range.End)); } |
Особенностью этой функции является то, что далеко не первая строка представления, соответствующая строке документа, является той, что нужно. В представлении может быть несколько строк, соответствующих одной строке документа. Распознать нужную строку можно, вычислив позицию символа в представлении и сравнив ее с длиной строки представления.
Задача HitTest несравнимо сложнее. Она должна вычислить тип области, на которую указывают переданные в качестве параметров координаты, и если она находится над текстом, то вычислить позицию в представлении для переданных координат.
Для этого с помощью функции GetViewRowIndexByTopOffset производится расчет строки:
private int GetViewRowIndexByTopOffset(int y) { int topOffset = 0; RowCollection rows = Rows; FontHelper fontHelper = DefaultStyle.FontHelper; for (int i = FirstVisibleViewRow, count = rows.Count; i < count; i++) { int h = rows[i].CalcRowHeight(fontHelper); topOffset += h; if (topOffset >= y) return i; PaintDebugMarker(ref topOffset); } return -1; } |
Далее производится последовательный подсчет ширин символов с постоянной проверкой, не превышает ли правая координата очередного символа X-координаты, переданной в качестве параметра. Если превышает, то позиция этого символа (и строки) помещается в структуру HitTestInfo. При расчете ширин символов учитывается стилевые диапазоны. Для этого сначала вызывается функция ToStyledRange (см. листинг -6), преобразующая StyledRange[] из строки в AppliedStyle[], а затем перебором диапазонов находится нужный символ. Исходный код HitTest можно найти в файле Rsdn.Editor\ObjectModel\View\View.Translate.cs.
ToLocation производит обратную работу по отношению к HitTest. Сначала он бежит по строкам, пока не дойдет до указанной в параметре. Попутно он считает высоту строк представления. Далее он пробегается по символам строки, ища символ, указанный в параметре. При этом он точно так же подсчитывает их ширину. Как и в HitTest, при подсчете ширины символов используется информация о стилевых диапазонах. В итоге вычисляется экранная координата символа или возвращается null. Это говорит о том, что невозможно подсчитать координату символа (символ выходит за пределы видимой области представления).
Рассказать за один раз обо всех аспектах реализации такого большого control-а, как редактор кода с подсветкой синтаксиса – практически неподъемная задача. Поэтому я продолжу свой рассказ в следующем номере. Так, я обязательно расскажу о реализации редактирования с поддержкой Undo/Redo, о декларативном, динамическом (во внешнем XML-файле) задании клавиатурных обработчиков, реализации Drag-Drop, о работе со шрифтами, об отрисовке, о поддержке анимированных и обычных картинок и т.п. А пока что вы можете открыть исходный код проекта в VS 2005 или C# Express и под отладчиком понаблюдать за работой этого control-а.
На нашем сайте очень часто можно слышать крайне скептические мнения о производительности .NET-приложений. Мнения варьируются от откровенно дилетантских вроде «.NET – это интерпретация, а что возьмешь с интерпретации?» до разумно скептических вроде: «Да, .NET порождает компилированный код, но боюсь, что GC, проверки выходов за границы массивов и другие runtime-проверки, связанные с контролем типов, не позволят создавать на нем серьезные приложения.». Что же, не скрою, одной из задач данного проекта было развенчание скептицизма. Все же редактор – это приложение, довольно сильно нагружающее процессор. Однако опровергать скептицизм ценой параноидального вылизывания и повсеместных оптимизаций у меня никакого желания не было. Современные процессоры и видеокарты (а это основные компоненты, нагружаемые редактором) довольно шустры, и делать предварительные, да еще (как потом может оказаться) чрезмерные оптимизации, никакого желания не было. Тем более, что хотелось создать редактор, который, в отличие от, например, Scintilla (http://www.scintilla.org/), будет легко поддерживать и развивать. А любая оптимизация напрочь убивает эти качества. Посему я оптимизировал только тот код, который принципиально будет вызываться очень часто. Так, я оптимизировал приведенный выше алгоритм функции ToStyledRange(), Styler и код переноса строк. Остальное писалось по принципу: чем короче и понятнее, тем лучше. Так, отрисовка делалась по принципу «начнет тормозить – будем оптимизировать». Знаете, что произошло? Она не начала тормозить :). И это при том, что по умолчанию включен режим полноэкранного сглаживания (он все же тормозит на машинах со старыми встроенными в материнскую плату видеокартами, но его можно выключить). Так, даже при вбивании одного символа с клавиатуры или при прокрутке одной строки кода перерисовывается все представление. И что? И ничего. Скорости более чем достаточно. А отсутствие оптимизации прокрутки и отрисовки еще ко всему прочему упрощает перенос control-а на другие платформы (например, на Моно). Откровенно говоря, это не входило в задачу, но если это есть, то почему бы и нет :). В общем, на сегодня вся отрисовка выглядит как полная перерисовка при любом действии. Единственная оптимизация: при множественных изменениях отрисовку можно заморозить. Когда я писал подобный код на C++ много лет назад, я начал с оптимизаций, думая, что уж отрисовка-то точно окажется узким местом (тем более что тогда видеокарты были совсем слабенькими). В итоге я оптимизировал построчную прокрутку и отрисовку пары символов, но оказалось, что отрисовка всего экрана тормозит, и при листании страниц это очень хорошо заметно. А ведь пользователю совершенно все равно, где проявляются тормоза. Если они есть, он уже начинает испытывать неприязнь к программе. Поэтому в этот раз я сосредоточился на общей скорости отрисовки, а не на оптимизации ее отдельных частей. И я не прогадал. Достаточная скорость отрисовки всего экрана позволяет просто забыть про все оптимизации. Ну а если вдруг когда-нибудь они понадобятся, то тогда и займемся оптимизацией.
Второе место, где, возможно, оптимизация была бы уместна – это подсветка синтаксиса и перенос строк. Какова бы ни была скорость этих алгоритмов, всегда найдется документ такого размера, на котором общее время их работы будет превышать 300 миллисекунд – порог визуального восприятия среднестатистического человека. По крайней мере перенос строк вызывается при изменении размеров окна, и при больших размерах документа возникает ощущение задержки. Изменение размеров окна – нечастая операция, но психология человека такова, что он ассоциирует такие задержки с производительностью всего приложения. В таких случаях стандартным приемом является обман человеческого восприятия. Например, при изменении размеров окна можно не производить в синхронном режиме перенос всех строк документа, а работать только с частью строк, отображаемой на экране (эта операция будет заведомо быстрой на любом современном компьютере). Разбиение всех остальных строк можно производить в отдельном потоке. Такая оптимизация есть в Scintilla, а в Rsdn.Editor ее пока нет. В результате визуально текст в Scintilla переносится и загружается быстрее, чем в Rsdn.Editor, хотя на самом деле это совершенно не так. В Rsdn.Editor это не сделано по простой причине – задержки проявляются только при объеме загружаемого текста, превышающем мегабайт, что встречается нечасто.
Компонент будет доступен под разными лицензиями. Скорее всего, для жителей бывшего СССР и фирм, зарегистрированных там же, компонент будет доступен под лицензией donateware, то есть вы не принуждаетесь, но можете заплатить некоторую сумму в благодарность за проделанную работу. Для открытых проектов единственное ограничение будет только в том, что вы не можете выпускать этот код или основанный на нем под лицензией GNU и ей подобными (т.е. запрещающими проприетарное использование кода). В остальном для открытых проектов ограничений не будет. Для зарубежных фирм и частных лиц компонент будет распространяться по принципу Shareware. Исходные коды компонентов будут доступны в svn://rsdn.ru/Editor для свободного скачивания. Любой, кто захочет присоединиться к проекту, сможет это сделать, написав мне об этом по электронной почте. Если вы захотите создать на его базе нечто свое, то я не буду возражать. Но при этом вы должны будете указать, что ваш код использует код Rsdn.Editor, в readme, документации и диалоге about, ну, или связаться со мной и приобрести частную лицензию.
Я бы назвал степень готовности control-а – альфа-версия. Но, в отличие от многих альфа-версий, этот control уже вполне работоспособен. В нем есть несколько (7 штук на момент написания статьи) известных мне ошибок. И конечно же, множество ненайденных. Если вы найдете ошибку, то сообщите мне по электронной почте, напишите на форум, посвященный компоненту или запишите сами в SVN (если вы уже получили к нему доступ на запись). Путь файла, в который нужно помещать сообщения об ошибках Rsdn.Editor\Rsdn.Editor\Documentation\Bugs.xml.
Что касается надежности, то могу сказать так. Редактор довольно надежен, хотя я так и не смог заставить себя сделать unit-тесты. Что позволяет мне это утверждать? Во-первых, большая часть этой статьи была написана в самом редакторе (до появления редакторской правки и необходимости вставлять картинки). Во-вторых, в редакторе нет ни одной опасной строчки кода, разве что пара строчек interop-а. В остальном это 100% safe pure C#-код. Даже если ошибка случится, то в большинстве случаев вы получите сообщение об ошибке, в котором можно будет нажать «Continue» и продолжить работу дальше. Я сам получал подобные сообщения в процессе работы над статьей (после чего и появились первые записи в файле сообщений об ошибках), но, как видите, статья перед вами. :)
На момент написания этой статьи объем кода control-а составлял 315 Кб. Для сравнения код Scintilla составляет 2 Мб, из которых 560 Кб составляет код лексических анализаторов языков. Другими словами чистый код Scintilla составляет как минимум 1.5 Мб. И это при том, что 70% функций Scintilla в Rsdn.Editor реализованы. Забавно, что даже .NET-обертка для Scintilla, используемая в RSDN@Home, имеет размер 150 Кб.
Достичь таких показателей удалось благодаря трем аспектам:
| Оценка 1050 Оценить
|
