
Идея этой книги родилась из опыта сопровождения сайта http://www.sql-ex.ru, где в режиме онлайн можно решать задачи на написание запросов к учебным базам данных. Автор не ставит целью формально описать все аспекты этого языка. Наоборот, он старается донести до читателя самую суть и восполнить пробел поверхностного изложения синтаксиса глубоким проникновением в логику построения запросов. Основной материал книги составляет анализ ошибочных решений задач. Эти ошибки не являются надуманными. Запросы писали посетители сайта, которые после неудачных попыток решить проблему просили объяснить, почему верный, по их мнению, запрос не принимается системой проверки. Поэтому можно смело утверждать, что в книге разбираются характерные ошибки и их объяснение позволит добиться значительно большего прогресса в изучении SQL, чем простое рассмотрение примеров использования тех или иных конструкций языка. Книга предназначена для всех, кого интересует глубокое практическое изучение приемов программирования на SQL.
Если вы хотите узнать, как получить информацию из базы данных, но не знаете, с чего начать, то эта книга для вас. Если же вы знакомы с языком SQL или даже являетесь специалистом по базам данных, вам будет интересно оценить свои знания.
Цель этой книги - быстрое изучение языка SQL. При этом "быстрое" вовсе не означает "поверхностное". Напротив, оставляя в стороне многие теоретические аспекты языка, автор старается дать глубокое понимание логической структуры данных и, как следствие, правильного построения запросов с учетом этой структуры. Надеемся, что после чтения этой книги вам будет легче понять и то, о чем здесь не написано.
Книга посвящена решению упражнений по извлечению информации из реляционной базы данных, то есть наиболее синтаксически сложному оператору SELECT. Здесь вы также найдете необходимую справочную информацию по другим операторам подъязыка манипуляции данными (DML - Data Manipulation LanguageDML, язык), а именно операторам INSERT, UPDATE и DELETE, осуществляющих модификацию данных.
Такая подача материала связана с тем, что книга адресована в основном потенциальным пользователям и разработчикам приложений СУБД, которых, в первую очередь, интересуют вопросы извлечения информации из существующих баз данных, и только потом - их модификации и создание структур хранения.
Упражнения взяты с сайта Упражнения по SQL, который уже на протяжении нескольких лет эффективно используется в системе дистанционного обучения языку SQL.
Следуя испытанной практике, предлагаем вам поучиться на чужих ошибках. При этом, разбирая ошибочные решения, в большинстве случаев не дается окончательных "правильных" решений. Это вызвано двумя причинами:
Справедливости ради, заметим, что после выяснения причины ошибки в результате анализа неверных решений их исправление не должно составить труда.
Приведенные в книге ошибочные решения не являются надуманными. Эти запросы писали посетители сайта, которые после неудачных попыток решить упражнение просили объяснить, почему верный, по их мнению, запрос не принимается системой проверки. Поэтому автор берет на себя смелость утверждать, что это характерные ошибки и их объяснение позволит добиться значительно большего успеха в изучении SQL, чем простое рассмотрение примеров использования тех или иных конструкций языка.
Для решения рассматриваемых в книге упражнений вы можете:
Если вы только приступаете к изучению языка SQL, то лучше начать с части II, где рассматривается синтаксис оператора SELECT и приведены номера упражнений, которые рекомендуется решить для закрепления соответствующего материала. Затем переходите к части I, которая поможет преодолеть затруднения при решении упражнений и разобраться в нюансах. С операторами модификации данных также можно познакомиться в части II. Упражнения по этим операторам не рассматриваются в книге, поскольку они достаточно просты, и сложные конструкции могут возникать здесь только за счет использования подзапросов. Множество примеров в книге и решение упражнений на сайте позволят вам в полной мере усвоить этот материал.
Если вы уже знакомы с языком SQL, то начинайте с части I, обращаясь к части II лишь для получения справки по тем или иным предложениям оператора SELECT или чтобы узнать о специфических особенностях реализации (в настоящее время мы используем MS SQL Server 2000).
В части III книги приводится описание функций Transact-SQL - языка, предназначенного для программирования серверной части приложений в SQL Server и SyBase, а также изложены типичные проблемы программирования на языке SQL. Эти знания пригодятся для решения задач сертификационного этапа на сайте. На данном этапе уже трудно обойтись без особенностей реализации и знания характерных приемов программирования. Надеемся, что эта информация также окажется полезной для вас.
Советуем начинать чтение с описания предметной области, моделируемой учебной базой данных, и внимательного изучения схемы данных. Затем стоит познакомиться с "неправильным" решением и самостоятельно найти в нем ошибку, а затем прочитать объяснение.
Будем считать синонимами термины таблица и отношение; строка и кортеж столбец, атрибут и поле. Интересующихся тонкостями терминологии отсылаем к фундаментальной книге Дейта [1].
Там, где требуются специфические возможности (функции), не оговоренные стандартом, при написании запросов применяется синтаксис SQL Server (версии 2000). Все приведенные в книге скрипты проверялись именно на этой СУБД, которая также используется на сайте с упражнениями. Справочную информацию по этим специфическим особенностям вы найдете в части III.
В первую очередь автор хотел бы поблагодарить своих коллег, помогавших создавать и сопровождать сайт, - Майстренко А. В., Лысенко О. В., Калинкина В. Ю. и Валуева Д. И. Без них не было бы ни сайта, ни книги. Автор также выражает признательность Гершовичу В. И., который первым предложил написать данную книгу. Автор благодарит всех авторов задач, лиц, внесших свой вклад в развитие ресурса, а также многочисленных посетителей, ошибки которых здесь и анализируются. Невозможно перечислить их всех поименно, так как список этих людей стал бы самой большой частью книги. Их имена всегда можно увидеть на сайте www.sql-ex.ru.
Две схемы данных и многие формулировки задач по этим схемам заимствованы из книги Дж. Ульмана и Дж. Уидома [2], которым автор выражает свою признательность.
Фирма занимается приемом вторсырья и имеет несколько пунктов приема. Каждый пункт получает деньги для их выдачи сдатчикам в обмен на сырье. Фактически на схеме представлены две базы данных. В каждой задаче по этой схеме используется только одна пара таблиц (либо с приставкой _o, либо без нее).
В таблицах Income_o и Outcome_o первичным ключом является пара атрибутов {point, date} - номер пункта приема и дата. Этот ключ должен моделировать ситуацию, когда сведения о получении денег на приемном пункте и их выдаче сдатчикам записываются в базу данных не чаще одного раза в день.
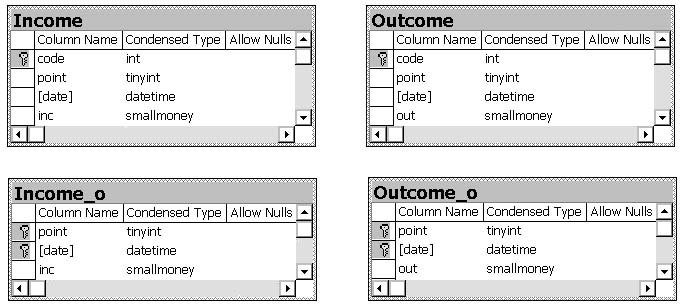
Рис. 2.1. Схема базы данных ''Фирма вторсырья''
Значения данных в столбце date не содержат времени, например 2001-03-22 00:00:00.000. К сожалению, использование для этого столбца типа данных datetime может вызвать непонимание, поскольку очевидно, что учет времени не позволит ограничить многократный ввод значений с одной и той же датой (и номером пункта), но отличающихся временем дня. Этот недостаток, связанный с отсутствием отдельных типов данных для даты и времени, уже преодолен в версии SQL Server 2005. При использовании же SQL Server 2000 обеспечить правильность ввода можно при помощи, например, следующего ограничения (CK_Income_o):
ALTER TABLE Income_o ADD CONSTRAINT PK_Income_o PRIMARY KEY ( [point], [date] ), CONSTRAINT CK_Income_o CHECK ( DATEPART(hour,[date]) + DATEPART(minute,[date]) + DATEPART(second,[date]) + DATEPART(millisecond,[date]) = 0 ) |
Это ограничение (сумма часов, минут, секунд и миллисекунд равна нулю) не позволит ввести какое-либо время, отличное от 00:00:00.000. При таком ограничении первичный ключ на данной таблице будет действительно гарантировать наличие лишь одной записи в день для каждой точки.
Таблица Income_o (point, date, inc) содержит информацию о поступлении денежных сумм (inc) на пункт приема (point). Аналогичная таблица - Outcome_o (point, date, out) - служит для контроля расхода денежных средств (out).
Вторая пара таблиц - Income (code, point, date, inc) и Outcome (code, point, date, out) - моделирует ситуацию, когда приход и расход денег может фиксироваться несколько раз в день. Следует отметить, что если записывать в последние таблицы только дату без времени (что и имеет место), то никакая естественная комбинация атрибутов не может служить первичным ключом, поскольку суммы денег также могут совпадать. Поэтому нужно либо учитывать время, либо добавить искусственный ключ. Мы использовали второй вариант, добавив целочисленный столбец code только для того, чтобы обеспечить уникальность записей в таблице.
Предположив, что приход и расход денег на каждом пункте приема фиксируется произвольное число раз (в обе таблицы добавлен первичный ключ code), написать запрос с выходными данными (point, date, out, inc), в котором каждому пункту за каждую дату соответствует одна строка.
В этой задаче требуются данные из двух таблиц собрать в одном результирующем наборе; при этом приход и расход денег на пункте приема в один и тот же день должны находиться в одной строке.
Аналогичное упражнение 29 для таблиц Income_o и Outcome_o, размещенное на сайте, как правило, затруднений не вызывало. Суть проблемы демонстрирует следующее решение:
SELECT Income.point, Income.date, SUM(out), SUM(inc) FROM Income LEFT JOIN Outcome ON Income.point = Outcome.point AND Income.date = Outcome.date GROUP BY Income.point, Income.date UNION SELECT Outcome.point, Outcome.date, SUM(out), SUM(inc) FROM Outcome LEFT JOIN Income ON Income.point = Outcome.point AND Income.date = Outcome.date GROUP BY Outcome.point, Outcome.date |
Идея решения такова. Выполняется соединение таблицы, в которой фиксируются приходы денег, с таблицей расходов средств по совпадению номера пункта приема и даты. Левое соединение, которое здесь используется, гарантирует получение результата в том случае, если на пункте приема в некоторые дни есть только приход, но нет расхода (NULL). Далее выполняется объединение с запросом, в котором выполняется обратное левое соединение таблицы расхода с таблицей прихода. Таким образом, учитывается случай, когда на пункте есть расход, но нет прихода. Исключение дубликатов строк (в случаях, когда есть и приход, и расход) выполняется использованием оператора UNION.UNION, оператор
Запрос дает неверный результат, когда в один день на пункте приема выполняется несколько операций по приходу/расходу денежных средств. В качестве примера возьмем характерный для этого случая день - 24 марта 2001 года. Выполним пару запросов:
SELECT * FROM Income WHERE date = '2001-03-24 00:00:00.000' AND point = 1 SELECT * FROM Outcome WHERE date = '2001-03-24 00:00:00.000' AND point = 1 |
Получим следующий результат:
| Приход | |||
|---|---|---|---|
| code | point | Date | inc |
| 3 | 1 | 2001-03-24 00:00:00.000 | 3600.0000 |
| 11 | 1 | 2001-03-24 00:00:00.000 | 3400.0000 |
| Расход | |||
| code | point | Date | out |
| 2 | 1 | 2001-03-24 00:00:00.000 | 3663.0000 |
| 13 | 1 | 2001-03-24 00:00:00.000 | 3500.0000 |
В данном случае, когда есть и приход, и расход, внешнее соединение эквивалентно внутреннему соединению, то есть каждая строка из одной таблицы соединяется с каждой строк из другой таблицы, если в этих строках совпадают и дата, и номер пункта приема. Поэтому перед группировкой будет получен следующий результат (показаны только столбцы прихода и расхода):
| inc | out |
|---|---|
| 3600.0000 | 3663.0000 |
| 3600.0000 | 3500.0000 |
| 3400.0000 | 3663.0000 |
| 3400.0000 | 3500.0000 |
После группировки и суммирования мы получаем удвоение результата как для прихода, так и для расхода. Если бы прихода было три, то мы бы получили утроение расхода и т. д.
И дубликаты здесь ни при чем, так как каждый из объединяемых запросов дает аналогичный результат, то есть остается одна строка на каждую пару значений пункт, дата.
Посчитать остаток денежных средств на каждом пункте приема для базы данных с отчетностью не чаще одного раза в день. Вывод: пункт, остаток.
SELECT ss.point, ss.inc - dd.out FROM (SELECT i.point, SUM(inc) AS inc FROM Income_o i GROUP BY i.point ) AS ss, (SELECT o.point, SUM(out) AS out FROM Outcome_o o GROUP BY o.point ) AS dd WHERE ss.point = dd.point |
В предложении FROM в каждом из подзапросов определяется сумма соответственно прихода и расхода денежных средств на каждом из пунктов приема. Эти подзапросы соединяются по равенству номеров пунктов приема, что позволяет построчно вычислить остаток денежных средств на каждом пункте: ss.inc - dd.out.
Казалось бы, все правильно, однако решение содержит одну ошибку. Попробуйте ее найти.
Посчитать остаток денежных средств на начало дня 15.04.2001 на каждом пункте приема для базы данных с отчетностью не чаще одного раза в день. Вывод: пункт, остаток.
SELECT i.point, CASE inc WHEN NULL THEN 0 ELSE inc END - CASE out when NULL THEN 0 ELSE out END FROM (SELECT point, SUM(inc) inc FROM Income_o WHERE '20010415' > date GROUP BY point ) AS I FULL JOIN (SELECT point, SUM(out) out FROM Outcome_o WHERE '20010415' > date GROUP BY point ) AS III ON III.point = I.point |
Это упражнение во многом аналогично предыдущему упражнению 5921. По сути, здесь дополнительно применяется лишь отбор по дате. В связи с этим обращаем внимание на ее представление в запросе. Дело в том, что в предикате сравнивается строка с полем типа datetime. В SQL Server имеется функция CONVERT,CONVERT(), функция которая позволяет преобразовать строковое представление даты/времени к этому типу, используя различные форматы представления даты. Однако строковое представление в виде год месяц день, которое используется в рассматриваемом решении, всегда будет правильно преобразовываться неявно к типу datetime вне зависимости от настроек сервера [4].
Кто разобрался с ошибкой в предыдущем упражнении, наверняка увидел здесь попытку ее исправить. К сожалению, попытку неудачную, что, с другой стороны, дает вам возможность еще раз проверить себя.