Здравствуйте, Юрий Лазарев, Вы писали:
ЮЛ>Не было предложено ни одного конкретного способа сократить длину (кроме бесчисленных пожеланий, которых при желании я и сам мог бы навалить не одну простыню). Отсюда можно сделать вывод, что вполне существуют в природе задачи, по существу не укладывающиеся в прокрустово ложе ИТ-религии, или сокращение которых займет время, сравнимое с самой разработкой и сопровождением. Фанаты формализма в таком случае просто отбрасывают задачу как "нерешаемую", хотя нерешаема она только из-за зашоренности религией (т.е. элементарного невежества).
Вполне можно представить ситуацию в которой допустимы функции по 1400 строк. Например при генерации хитрого автомата или при использовании какого-нибудь чудного компилятора двадцатилетней давности.
Но никакого цельного/неделимого алгоритма в PseudoProcessAcceptedData нет и в помине. Например:
1. Как уже заметили выше, построение графа из несвязанных отрезков (заданных координатами) — это вполне замкнутый и отдельный алгоритм, который элементарно выносится в отдельную функцию, которую даже можно использовать повторно в других местах.
2. Сразу после построения графа, идёт поиск компонент связности на базе disjoint-set — это также прекрасно оформляется в виде отдельного и цельного алгоритма. Кстати, судя по всему (избыточные условия, структуры данных и прочие торчащие уши), этот каменный лисапед рождался в муках — почему было просто не использовать поиск в глубину/ширину?
Здравствуйте, Юрий Лазарев, Вы писали:
ЮЛ>Вниманию был предложен "длинный" код всего лишь одного несложного алгоритма, написание которого не обязательно нуждается в строго согласованной с библией ИТ структурированности. Читаемость от этого мало проигрывает, но это кого либо мало волнует. Им нужен глубоко вложенный, сильно фрагментированный код, на отладке которого будет проще спотыкаться на каждом шагу.
В 2015 году код, который после написания нужно еще и отлаживать, считается говнокодом. Без вариантов. К код ревью даже не допускается.
Здравствуйте, landerhigh, Вы писали:
L>Здравствуйте, Юрий Лазарев, Вы писали:
ЮЛ>>Вниманию был предложен "длинный" код всего лишь одного несложного алгоритма, написание которого не обязательно нуждается в строго согласованной с библией ИТ структурированности. Читаемость от этого мало проигрывает, но это кого либо мало волнует. Им нужен глубоко вложенный, сильно фрагментированный код, на отладке которого будет проще спотыкаться на каждом шагу.
L>В 2015 году код, который после написания нужно еще и отлаживать, считается говнокодом. Без вариантов. К код ревью даже не допускается.
Где же у меня написано — после написания? Когда я написал код, я сдал его заказчику и на 99% уверен, что "отлазивать" его не понадобится. Отладка нужна в процессе. Но для дураков, которым "должно быть все понятно" даже без понимания сути, это конечно покажется говнокодом. Тем более в 2015
Вот почти единственный разумный ответ на сотни постов в этой теме.
Знаете, нет, близко с бустом не соприкасался, а поиск уже существующих решений по необходимости был краток, тк надо было делать работу. Если бы не было идей, как ее делать, возможно, я и стал бы копаться в инет-помойке,но тогда вряд ли и заказчик появился заранее.
Естественно, на досуге я посмотрю boost.Graph и дам более точный ответ. Пока же сразу могу сказать, что по мне код в Графе ничуть не проще для понимания, непонятно (кроме самых общих слов о графах, ребрах и тп),как его приткнуть к моей задаче, в общем это "вещь в себе", и сколько времени уйдет на ее свободное владение, ещё неизчестно, но уж вряд ли тут присутствующие за 2 недели, как они уверяли, напишут нужную программу. Конечно, я представлял, что в области ПО для графов теория вполне развита, но большинство решаемых там проблем мне был и не так важны. Graph решает массу вопросов, но в этом и другая проблема — теперь вместо решения конкретной задачи я должен приспособлять нечто к своим потребностями, что не факт, что получится. Времени убьется масса, результат не гарантирован. Например, мне не видно, можно ли через Graph найти внешний контур (мой метод использует углы при вершинах, это скорее расширение парадигмы графа, но пройдет ли это там? )
Здравствуйте, Юрий Лазарев, Вы писали:
L>>В 2015 году код, который после написания нужно еще и отлаживать, считается говнокодом. Без вариантов. К код ревью даже не допускается.
ЮЛ>Где же у меня написано — после написания? Когда я написал код, я сдал его заказчику и на 99% уверен, что "отлазивать" его не понадобится.
Ах, на 99% процентов.
ЮЛ>Отладка нужна в процессе.
В процессе чего? В процессе написания? Или в мучительном процессе заставить это хоть как-то работать в реальных условиях? Ну так говнокод и есть. Классическое определение. Если программисту в 2015 году "в процессе" работы с его собственным кодом нужен отладчик, то он явно занят не своим делом и ваш менеджер абсолютно прав
ЮЛ>Но для дураков, которым "должно быть все понятно" даже без понимания сути, это конечно покажется говнокодом. Тем более в 2015
Тут ни о каком "покажется" речи нет. Это практически эталонный говнокод, возникший в процессе эталонного сферического говнокодинга в вакууме с применением отладчика.
И еще. Если бы вы хоть 5% энергии, затраченной тут на изобличение "дураков" и восхваление собственного нетленного творения, затратили на следование скромным рекомендациям вашего весьма терпеливого начальства, то ни первой, ни второй, ни третьей темы тут заводить не понадобилось бы.
Впрочем, чего уж тут. Кто хочет — делает. Кто не хочет, придумывает 100500 оправданий.
Здравствуйте, Юрий Лазарев, Вы писали:
ЮЛ>Вот почти единственный разумный ответ на сотни постов в этой теме.
По поводу внешнего качества кода, не рассматривая его внутреннее содержание, здесь многие уже высказались. Причём по большей части справедливо — уж извините, нет здесь никакого качества.
Выяснять что же на самом деле хотел сказать автор, пытаться увидеть лес за этими кривыми деревьями — задача не из приятных. Меня же мотивировали ваши упорные заявления о том, что мол за такой формой скрывается некое уникальное и неделимое содержание. Запала хватило только на несколько частей, хотя и этого оказалось более чем достаточно.
ЮЛ>Знаете, нет, близко с бустом не соприкасался, а поиск уже существующих решений по необходимости был краток, тк надо было делать работу. Если бы не было идей, как ее делать, возможно, я и стал бы копаться в инет-помойке,но тогда вряд ли и заказчик появился заранее.
Судя по топику, задача решалась больше месяца. Неужели нельзя было выделить пару часов вначале на поиск готовых решений?
ЮЛ>но уж вряд ли тут присутствующие за 2 недели, как они уверяли, напишут нужную программу.
Не знаю какая программа требовалась, но если рассматривать только главный алгоритм — то в этих темах уже отметилось как минимум несколько человек (а то и десяток) способных его реализовать за день, без использования готовых решений. А за две недели справились бы практически все. Ну нет здесь никакого rocket science.
ЮЛ>Конечно, я представлял, что в области ПО для графов теория вполне развита, но большинство решаемых там проблем мне был и не так важны. Graph решает массу вопросов, но в этом и другая проблема — теперь вместо решения конкретной задачи я должен приспособлять нечто к своим потребностями, что не факт, что получится.
Как раз таки наоборот, Boost.Graph построен таким образом, что его легко адаптировать к свои структурам.
Part of the Boost Graph Library is a generic interface that allows access to a graph's structure, but hides the details of the implementation. This is an “open” interface in the sense that any graph library that implements this interface will be interoperable with the BGL generic algorithms and with other algorithms that also use this interface.
ЮЛ>Времени убьется масса, результат не гарантирован. Например, мне не видно, можно ли через Graph найти внешний контур (мой метод использует углы при вершинах, это скорее расширение парадигмы графа, но пройдет ли это там? )
Судя по тому что применяется формула Эйлера для планарных графов (а есть ли гарантия того, что граф планарный? ведь данные пользовательские), и тому как она применяется — контурами вы называете контуры граней (faces) планарного графа, а внешним контуром — контур внешней грани. Это как раз то, что обходит planar_face_traversal, по ссылке выше есть пример:
New face: 1 2 5 4
New face: 2 3 4 5
New face: 3 0 1 4
New face: 1 0 3 2
Оно?
А вообще, моё сообщение было отнюдь не про Boost.Graph:
1. Этот алгоритм, вопреки вашим заверениям, не является неделимым. Он бьётся на вполне законченные и обособленные части, которые можно использовать повторно.
2. Судя по торчащим из кода ушам, алгоритм поиска компонент связности реализовывался с большим скрипом, хотя можно было использовать простейший обход в глубину/ширину. Кстати, внутри PrepareContoursMakeEquidistants лежит мина с квадратичной сложностью, причём которая элементарно обходится в первом же черновом варианте. Это всё никак не сочетается с заявкой на звание "алгоритмиста".
3. Boost.Graph был приведён во-первых в качестве демонстрации того, что части алгоритма действительно реализуются отдельно, а во-вторых — наличия уже готового решения данной "уникальной" задачи (причём наверняка есть и другие варианты).
Здравствуйте, Bender, Вы писали:
B>По поводу внешнего качества кода, не рассматривая его внутреннее содержание, здесь многие уже высказались. Причём по большей части справедливо — уж извините, нет здесь никакого качества.
Я не говорил про качество, разговор только о допустимой длине.
B>Судя по топику, задача решалась больше месяца. Неужели нельзя было выделить пару часов вначале на поиск готовых решений?
Вообще то я не люблю "готовые" решения; если такие были в бусте, это вполне мог бы знать Манагер, по его рассказам уже собаку съевший на этом. Молчание доказывало, что там нечего искать. Сейчас очевидно, что его знакомство с бустом ненамного опережало мое.
B>Как раз таки наоборот, Boost.Graph построен таким образом, что его легко адаптировать к свои структурам.
Я попробую, и скажу, насколько это легко. Пока же я вижу плохую (или тяжелую) документацию. А boost у меня и не устанавливается (msvc-7.0). Рекомендуют делать build Binaries библиотек ("If you're using an earlier version of Visual C++, or a compiler from another vendor, you'll need to use Boost.Build to create your own binaries.") — но при попытке компиляции выходит в лог ошибка
builtins.c(1889) : error C2065: 'IO_REPARSE_TAG_SYMLINK' : undeclared identifier
Так что "вещь в себе" так и остается "вещью в себе".
B>Судя по тому что применяется формула Эйлера для планарных графов... Оно?
Не знаю. Формула Эйлера вообще то верна не только для планарных графов, это грани определяются в планарном графе, а в общем случае есть просто контуры — замкнутые циклы. Как в Graph определяются грани, это еще надо выяснить, — если это просто многоугольники, то это не совсем то, что мне надо. В моей задаче все ребра — произвольные кривые. Конечно, топологически можно кривую считать прямой, но что тут будет с гранями — сложно предсказать. Мне думается, проще их выявлять с помощью углов. Как в Graph, неизвестно. Нужны тесты, проверки, надо знакомиться с кодом.
Почему то библиотека не обрабатывает параллельные ребра — у меня это типичный случай, надо или игнорировать их или обрабатывать как все прочее. Exception тут не лучшее решение.
B>1. Этот алгоритм, вопреки вашим заверениям, не является неделимым. Он бьётся на вполне законченные и обособленные части, которые можно использовать повторно.
Допускаю, вопрос в том, насколько просто — разбить. Вы же не думаете, что частная задача по времени равна затратам на написание того же Grapha — или даже его одной части.
B>2. Кстати, внутри PrepareContoursMakeEquidistants лежит мина с квадратичной сложностью, причём которая элементарно обходится в первом же черновом варианте. Это всё никак не сочетается с заявкой на звание "алгоритмиста".
Не вижу квадратичной сложности. Если вы про цикл for внутри do, то при желании его можно оптимизировать, но он не пробегает по всем ребрам повторно, а только по уже найденным стилям кривых (а их в реальном чертеже не так много).
B>3. Boost.Graph был приведён во-первых в качестве демонстрации того, что части алгоритма действительно реализуются отдельно, а во-вторых — наличия уже готового решения данной "уникальной" задачи (причём наверняка есть и другие варианты).
Это еще предстоит проверить.
Здравствуйте, Varavva, Вы писали:
BFE>>Не могу согласиться. Зачем это? Зачем дураков до проекта допускать? V>Можете указать, где я это написал? V>Код должен быть понятен дураку — это одно, это пожелание пишушему код. Давать проект дураку — совсем другое.
Здравствуйте, landerhigh, Вы писали:
L>В 2015 году код, который после написания нужно еще и отлаживать, считается говнокодом. Без вариантов. К код ревью даже не допускается.
Не все в 2015 допущены до жЫрного энтерпрайза
Здравствуйте, B0FEE664, Вы писали:
BFE>Зачем вносить вселенскую гармонию в отдельно взятый проект?
Дело не в проекте, а в том, кто его делает. Человек или стремиться все делать хорошо и гармонично или второй путь — дисгармонично. Третьего не дано. Не ради проекта надо стараться, а ради своего навыка делать все гармонично
Здравствуйте, Varavva, Вы писали:
V> код должен быть понятен любому, кто сядет его дебажить или расширять
Такая же херь, как: "Любая кухарка может управлять государством".
Помнится меня восхитил код расчета по методу FIFO.
Он был удивительно эффективен по скорости исполнения и чрезвычайно компактен.
Это был реальный бриллиант.
Так вот, чтобы сначала понять, его, а потом восхититься, у меня ушло не меньше 1 часа.
Но я испытал истинное удовлетворение, когда осознал этот код.
Это был, пожалуй, единственный восхитительный фрагмент в системе, которую мы оптимизировали.
Все остальное можно было соптимизировать. А результаты оптимизации были вполне заметными — скорость генерации отчетов увеличилась в 10 раз.
Почитайте Вирта "Алгоритмы и структуры данных", там собрана коллекция мировых алгоритмов.
Каждый из них требует времени и сосредоточения для понимания.
Здравствуйте, Юрий Лазарев, Вы писали:
B>>Судя по топику, задача решалась больше месяца. Неужели нельзя было выделить пару часов вначале на поиск готовых решений? ЮЛ>Вообще то я не люблю "готовые" решения;
Почему же тогда использовали "готовую" сортировку и map?
ЮЛ>если такие были в бусте, это вполне мог бы знать Манагер, по его рассказам уже собаку съевший на этом. Молчание доказывало, что там нечего искать. Сейчас очевидно, что его знакомство с бустом ненамного опережало мое.
При постановке задачи начальник конечно же может дать релевантную информацию которой владеет, он даже может наметить план действий — если сам в теме.
В общем же случае задача сбора всей информации и поиска оптимального плана действий, в том числе поиск готовых решений — лежит на разработчике.
B>>Как раз таки наоборот, Boost.Graph построен таким образом, что его легко адаптировать к свои структурам. ЮЛ>Я попробую, и скажу, насколько это легко. Пока же я вижу плохую (или тяжелую) документацию.
Что же в ней плохого? На мой взгляд очень даже хорошая документация.
ЮЛ>А boost у меня и не устанавливается (msvc-7.0). Рекомендуют делать build Binaries библиотек ("If you're using an earlier version of Visual C++, or a compiler from another vendor, you'll need to use Boost.Build to create your own binaries.") — но при попытке компиляции выходит в лог ошибка ЮЛ> builtins.c(1889) : error C2065: 'IO_REPARSE_TAG_SYMLINK' : undeclared identifier ЮЛ>Так что "вещь в себе" так и остается "вещью в себе".
How to Build the BGL
DON'T! The Boost Graph Library is a header-only library and does not need to be built to be used. The only exceptions are the GraphViz input parser and the GraphML parser.
Да и кто вас заставляет использовать msvc-7.0? Она скорей всего уже не поддерживается в новых версиях Boost.
B>>Судя по тому что применяется формула Эйлера для планарных графов... Оно? ЮЛ>Не знаю. Формула Эйлера вообще то верна не только для планарных графов, это грани определяются в планарном графе, а в общем случае есть просто контуры — замкнутые циклы.
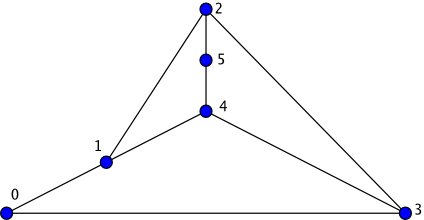
Допустим. Вот комментарий из вашего кода:
// where CONTOURS = (EDGES + COMPONENTS — VERTICES) by Euler formula
Вот граф:
Получается CONTOURS = 6, так? И где эти 6 контуров?
ЮЛ>Как в Graph определяются грани, это еще надо выяснить, — если это просто многоугольники, то это не совсем то, что мне надо.
A planar embedding is an important intermediate representation of a drawing of a planar graph. Instead of specifying the absolute positions of the vertices and edges in the plane, a planar embedding specifies their positions relative to one another. A planar embedding consists of a sequence, for each vertex in the graph, of all of the edges incident on that vertex in the order in which they are to be drawn around that vertex.
ЮЛ>Почему то библиотека не обрабатывает параллельные ребра — у меня это типичный случай, надо или игнорировать их или обрабатывать как все прочее. Exception тут не лучшее решение.
Где конкретно?
B>>1. Этот алгоритм, вопреки вашим заверениям, не является неделимым. Он бьётся на вполне законченные и обособленные части, которые можно использовать повторно. ЮЛ>Допускаю, вопрос в том, насколько просто — разбить. Вы же не думаете, что частная задача по времени равна затратам на написание того же Grapha — или даже его одной части.
Разбить можно по-разному, часто есть три основных варианта:
1. Без возможностей универсального применения в других местах, просто вынос кода в отдельную функцию. Упрощает разработку, позволяет легко делать юнит-тесты, упрощает последующее чтение и поддержку. Реализуется элементарно, я бы сказал даже механически — есть даже утилиты которые делают это сами (выедляется фрагмент кода, и нажимается одна кнопка).
2. К 1. добавить минимальную степень общности. Буквально щепотка полиморфизма и/или небольшая реогранизация открывают множество возможностей повторного использования.
3. Большая степень общности (как в Boost.Graph), плюс возможно оптимизация специальных случаев.
Разбиение алгоритма на отдельные/обособленные части — не означает создание аналога Boost.Graph, а подразумевает хотя бы выполнения пункта 1. Опять таки, Boost.Graph был приведён в качестве доказательства того, что такое разбиение возможно, а отнюдь не как единственный возможный вариант.
Вот, например, как вы тестировали правильность работы той части, которая ищет компоненты связности? Каждый раз вручную запускали программу, давали разные данные, делали дополнительный debug вывод, вручную проверяли результат?
B>>2. Кстати, внутри PrepareContoursMakeEquidistants лежит мина с квадратичной сложностью, причём которая элементарно обходится в первом же черновом варианте. Это всё никак не сочетается с заявкой на звание "алгоритмиста". ЮЛ>Не вижу квадратичной сложности. Если вы про цикл for внутри do, то при желании его можно оптимизировать, но он не пробегает по всем ребрам повторно, а только по уже найденным стилям кривых (а их в реальном чертеже не так много).
Да, я говорю про locCurvesPool (стили?) — сложность квадратична от их числа. Обходится действительно элементарно, причём сходу, а не когда выстрелит.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Здравствуйте, Юрий Лазарев, Вы писали:
ГВ>И тут Остапа понесло... Дружище, код не может быть совершенным никогда, от слова совсем. Стремление к совершенству — сугубо черта человека, а не кода. "Совершенный код" — это гипербола, вынесенная в название книги, не надо приписывать этой фразе избыточное значение, а то мы далеко зайдём.
в оригинале code complete. так что не гиперборла. кстати, сама книга написана в либеральном стиле без тоталитарщины и строгих правил.
americans fought a war for a freedom. another one to end slavery. so, what do some of them choose to do with their freedom? become slaves.
Здравствуйте, Bender, Вы писали:
B>Почему же тогда использовали "готовую" сортировку и map?
Потому что это уже "вполне очевидно" (формально: поддерживается стандартом).
ЮЛ>>если такие были в бусте, это вполне мог бы знать Манагер, по его рассказам уже собаку съевший на этом. Молчание доказывало, что там нечего искать. Сейчас очевидно, что его знакомство с бустом ненамного опережало мое.
B>В общем же случае задача сбора всей информации и поиска оптимального плана действий, в том числе поиск готовых решений — лежит на разработчике.
Считайте, я и выбрал свой оптимальный план действий. Если кому то не нравится, — надо аргументировать, "мне не нравится" как аргумент не годится.
B>Что же в ней плохого? На мой взгляд очень даже хорошая документация.
Попытаюсь еще раз, может быть мне больше повезет. Но вообще документация явно готовилась доксигеном, это удобное чтение для роботов, но не для людей.
ЮЛ>>А boost у меня и не устанавливается (msvc-7.0). Рекомендуют делать build Binaries библиотек ("If you're using an earlier version of Visual C++, or a compiler from another vendor, you'll need to use Boost.Build to create your own binaries.") — но при попытке компиляции выходит в лог ошибка ЮЛ>> builtins.c(1889) : error C2065: 'IO_REPARSE_TAG_SYMLINK' : undeclared identifier ЮЛ>>Так что "вещь в себе" так и остается "вещью в себе".
B>Boost.Graph вообще собирать не требуется, это header-only библиотека: B>DON'T! The Boost Graph Library is a header-only library and does not need to be built to be used. The only exceptions are the GraphViz input parser and the GraphML parser. B>Да и кто вас заставляет использовать msvc-7.0? Она скорей всего уже не поддерживается в новых версиях Boost.
Да-да, но она преподносится как работающая на любых платформах, и для любых компиляторов. Смотрим еще раз (это цитата из самой последней версии boost): "If you're using an earlier version of Visual C++, or a compiler from another vendor,"...
т.е. при желании ранние версии msvc можно трактовать как a compiler from another vendor. Как я понял, в этом случае должен собраться какой то их собственный Build, дополняющий возможности компиляторов. Но он вообще не собирается!
Поддерживается у них официально msvc-7.1 А кто заставляет использовать msvc-7.0 — жизнь! Или вы полагаете, что не имея работы, я могу позволить себе ставить самые последние навороченные версии, которые так завораживают местных хомячков?
B>>>Судя по тому что применяется формула Эйлера для планарных графов... Оно? ЮЛ>>Не знаю. Формула Эйлера вообще то верна не только для планарных графов, это грани определяются в планарном графе, а в общем случае есть просто контуры — замкнутые циклы.
B>Допустим. Вот комментарий из вашего кода: B>
B>// where CONTOURS = (EDGES + COMPONENTS — VERTICES) by Euler formula
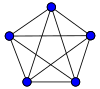
Обозначая последовательно узлы 1,2,3,4,5, эти контуры будут, например 123, 234, 345, 451, 512 и 12345.
Вообще же , конечно, правило определяющее контур, входящий в число контуров в формуле Эйлера, не так просто, как кажется на первый взгляд. (Иначе можно или насчитать слишком много контуров, или их недосчитаться). Я сформулирую его примерно так: "Каждый контур должен отличаться от прочего объединения контуров хотя бы одним "своим собственным" ребром, и при этом контур должен иметь хотя бы одно смежное с прочими ребро".
Условие наличия смежного ребра хорошо демонстрирует ваш рисунок. Казалось бы, можно все ребра разложить на 2 контура — внешний пентагон и внутреннюю звезду. Но эти 2 контура не имеют ни одного смежного ребра — поэтому вместе не составляют контуров для формулы Эйлера. По отдельности же для каждого варианта можно набрать по 6 "правильных" контуров — первый случай для пентагона я выписал выше. А для звезды это, например — 142, 253, 314, 425, 531 и 14253.
B>A planar embedding is an important intermediate representation of a drawing of a planar graph. Instead of specifying the absolute positions of the vertices and edges in the plane, a planar embedding specifies their positions relative to one another. A planar embedding consists of a sequence, for each vertex in the graph, of all of the edges incident on that vertex in the order in which they are to be drawn around that vertex.
Если вам такое объяснение кажется верхом абстракции и удобства, то как я должен в этих понятиях закодировать случай двух (или более) ребер, идущих из одной и той же точки в другую, тоже общую им? Разве они не совпадут (т.е. не сделаются "параллельными"?)
ЮЛ>>Почему то библиотека не обрабатывает параллельные ребра — у меня это типичный случай, надо или игнорировать их или обрабатывать как все прочее. Exception тут не лучшее решение. B>Где конкретно?
Где то было, а вы не видели? Странно, такая хорошая документация...
B>>>1. Этот алгоритм, вопреки вашим заверениям, не является неделимым. Он бьётся на вполне законченные и обособленные части, которые можно использовать повторно. ЮЛ>>Допускаю, вопрос в том, насколько просто — разбить. Вы же не думаете, что частная задача по времени равна затратам на написание того же Grapha — или даже его одной части.
B>Разбить можно по-разному, часто есть три основных варианта: B>1. Без возможностей универсального применения в других местах, просто вынос кода в отдельную функцию. Упрощает разработку, позволяет легко делать юнит-тесты, упрощает последующее чтение и поддержку. Реализуется элементарно, я бы сказал даже механически — есть даже утилиты которые делают это сами (выедляется фрагмент кода, и нажимается одна кнопка).
Разве у меня код не вынесен в "отдельную функцию"?
B>2. К 1. добавить минимальную степень общности. Буквально щепотка полиморфизма и/или небольшая реогранизация открывают множество возможностей повторного использования.
И тут нет возражений.
B>3. Большая степень общности (как в Boost.Graph), плюс возможно оптимизация специальных случаев.
Да, но время? Время?
B>Разбиение алгоритма на отдельные/обособленные части — не означает создание аналога Boost.Graph, а подразумевает хотя бы выполнения пункта 1. Опять таки, Boost.Graph был приведён в качестве доказательства того, что такое разбиение возможно, а отнюдь не как единственный возможный вариант.
Для меня применение "готовых решений" не очень еще и по опыту применения и разработок ActiveX — вещь сильно завязана на автора, пользователь ограничен в возможностях расширения (автор сам решает, что можно, что нельзя). Это подобно собиранию кода из Лего — какую то игрушку-самолет, даже очень на вид неплохую вы и соберете, но настоящий самолет заведомо из набора Лего не получится. Хотя, для наших хомячков, предпочитающих писать код, не особо размышляя над его алгоритмом, Лего — самый лучший подход.
B>Вот, например, как вы тестировали правильность работы той части, которая ищет компоненты связности? Каждый раз вручную запускали программу, давали разные данные, делали дополнительный debug вывод, вручную проверяли результат?
Я проверял именно те его части, которые вызывали сомнения. Для того и подбирались данные, а тестирование случайных данных я не делаю. Для того есть лучшее решение — тесты у заказчика, которых набралось уже за тысячи.
B>Да, я говорю про locCurvesPool (стили?) — сложность квадратична от их числа. Обходится действительно элементарно, причём сходу, а не когда выстрелит.
Ну да, можно применить map или set по стилям, но зачем городить огород и усложнять код ненужными обобщениями?
Здравствуйте, Varavva, Вы писали:
BFE>>Зачем вносить вселенскую гармонию в отдельно взятый проект? V>Дело не в проекте, а в том, кто его делает. Человек или стремиться все делать хорошо и гармонично или второй путь — дисгармонично. Третьего не дано. Не ради проекта надо стараться, а ради своего навыка делать все гармонично
Как правило, люди, которые делают свой проект "гармонично" не заканчивают проект вовремя. "Хорошо" и "гармонично" слишком расплывчатые понятия. А у вас ещё интереснее получается: проект должен быть гармоничным, чтобы он был понятен дураку. И делать так следует ради вселенской гармонии. У вас очень интересные технические требования к заданию.
Здравствуйте, Юрий Лазарев, Вы писали:
ЮЛ>>>Вообще то я не люблю "готовые" решения; B>>Почему же тогда использовали "готовую" сортировку и map? ЮЛ>Потому что это уже "вполне очевидно" (формально: поддерживается стандартом).
Допустим. И всё же, чем вам не угодили готовые решения? Какие аргументы?
ЮЛ>>>если такие были в бусте, это вполне мог бы знать Манагер, по его рассказам уже собаку съевший на этом. Молчание доказывало, что там нечего искать. Сейчас очевидно, что его знакомство с бустом ненамного опережало мое. B>>В общем же случае задача сбора всей информации и поиска оптимального плана действий, в том числе поиск готовых решений — лежит на разработчике. ЮЛ>Считайте, я и выбрал свой оптимальный план действий. Если кому то не нравится, — надо аргументировать, "мне не нравится" как аргумент не годится.
Из месячной работы был ли потрачен хотя бы час на поиск готовых библиотек или описаний алгоритмов?
B>>Что же в ней плохого? На мой взгляд очень даже хорошая документация. ЮЛ>Попытаюсь еще раз, может быть мне больше повезет. Но вообще документация явно готовилась доксигеном, это удобное чтение для роботов, но не для людей.
Doxygen там не было. В документации сгенерированного содержания минимум.
Покажите мне тот "доксиген" который сгенерирует подобное содержание и робота который его поймёт: http://www.boost.org/doc/libs/1_57_0/libs/graph/doc/planar_graphs.html http://www.boost.org/doc/libs/1_57_0/libs/graph/doc/planar_face_traversal.html
B>>Boost.Graph вообще собирать не требуется, это header-only библиотека: B>>DON'T! The Boost Graph Library is a header-only library and does not need to be built to be used. The only exceptions are the GraphViz input parser and the GraphML parser. B>>Да и кто вас заставляет использовать msvc-7.0? Она скорей всего уже не поддерживается в новых версиях Boost. ЮЛ>Да-да, но она преподносится как работающая на любых платформах, и для любых компиляторов. Смотрим еще раз (это цитата из самой последней версии boost): "If you're using an earlier version of Visual C++, or a compiler from another vendor,"... ЮЛ>т.е. при желании ранние версии msvc можно трактовать как a compiler from another vendor. Как я понял, в этом случае должен собраться какой то их собственный Build, дополняющий возможности компиляторов. Но он вообще не собирается!
Boost это набор библиотек.
Некоторые из них нужно предварительно компилировать, большинство же нет. Некоторые работают на старых компиляторах (плохо поддерживающих стадарт C++) и являются кросс-платформенными, другие же работают только на конкретных платформах и компиляторах.
Boost.Graph — это header-only библиотека, то есть не требует предварительной сборки. В Boost появилась довольно давно, и скорей всего поддерживает даже очень старые компиляторы. Если же вдруг в новой версии сломали поддержку какого-то древнего компилятора, то просто достаточно взять Boost старой версии.
ЮЛ>Поддерживается у них официально msvc-7.1 А кто заставляет использовать msvc-7.0 — жизнь! Или вы полагаете, что не имея работы, я могу позволить себе ставить самые последние навороченные версии,
Непонятно о чём речь. У MSVC есть бесплатные Express версии, есть абсолютно бесплатные gcc и clang.
Да даже если поставить себе компилятор и Boost это прям такая проблема — то есть ведь онлайн-компиляторы. Вот пример planar_face_traversal из Boost.Graph запущенный в такой онлайн-среде: http://coliru.stacked-crooked.com/a/63829dee31ffbd98
Играйтесь на здоровье.
ЮЛ>которые так завораживают местных хомячков?
Кого вы называете хомячками? Инженеров предпочитающих работать инструментами, которые лучше соответствуют международным стандартам?
ЮЛ>>>Формула Эйлера вообще то верна не только для планарных графов, это грани определяются в планарном графе, а в общем случае есть просто контуры — замкнутые циклы. B>>Допустим. Вот комментарий из вашего кода: B>>
B>>// where CONTOURS = (EDGES + COMPONENTS — VERTICES) by Euler formula
B>>Вот граф: B>>Image: 100px-Complete_graph_K5.svg.png B>>Получается CONTOURS = 6, так? И где эти 6 контуров? ЮЛ>Обозначая последовательно узлы 1,2,3,4,5, эти контуры будут, например 123, 234, 345, 451, 512 и 12345.
Не, не пойдёт, это уже натягивание совы на глобус.
Во-первых вы пытаетесь посчитать внешнюю грань, хотя в своей интрепретации формулы Эйлера её отбросили. Вот полная формула Эйлера, учитывающая внешнюю грань:
faces = edges + components — vertices + 1
в вашем же варианте нет "+ 1".
Во-вторых не учитываете 134 и ещё четыре подобных цикла.
ЮЛ>Если вам такое объяснение кажется верхом абстракции и удобства, то как я должен в этих понятиях закодировать случай двух (или более) ребер, идущих из одной и той же точки в другую, тоже общую им? Разве они не совпадут (т.е. не сделаются "параллельными"?)
В планарном графе нет параллельных рёбер. Если в оригинальном чертеже есть совпадающие отрезки, и например вам нужно оба отмечать при обходе соответвующего контура, то просто сделайте соответсвие: одно ребро графа (то есть абстрактного представления) -> несколько отрезков в оригинальной моделе. Подобно тому, как в вашем же коде одна вершина графа соответсвует нескольким оригинальным точкам.
ЮЛ>>>Почему то библиотека не обрабатывает параллельные ребра — у меня это типичный случай, надо или игнорировать их или обрабатывать как все прочее. Exception тут не лучшее решение. B>>Где конкретно? ЮЛ>Где то было, а вы не видели? Странно, такая хорошая документация...
Я спросил где конкретно, потому что там это есть в нескольких местах.
B>>Разбить можно по-разному, часто есть три основных варианта: B>>1. Без возможностей универсального применения в других местах, просто вынос кода в отдельную функцию. Упрощает разработку, позволяет легко делать юнит-тесты, упрощает последующее чтение и поддержку. Реализуется элементарно, я бы сказал даже механически — есть даже утилиты которые делают это сами (выедляется фрагмент кода, и нажимается одна кнопка). ЮЛ>Разве у меня код не вынесен в "отдельную функцию"?
В функцию длинной более тысячи строк и цикломатической сложностью за 300 (при рекомендованных значениях 10-15). При том что в этой функции элементарно очерчиваются обособленные алгоритмы.
B>>2. К 1. добавить минимальную степень общности. Буквально щепотка полиморфизма и/или небольшая реогранизация открывают множество возможностей повторного использования. ЮЛ>И тут нет возражений. B>>3. Большая степень общности (как в Boost.Graph), плюс возможно оптимизация специальных случаев. ЮЛ>Да, но время? Время?
На 3. действительно ушло бы очень много времени, но этого никто и не требовал. У вас же нет даже 1.
B>>Разбиение алгоритма на отдельные/обособленные части — не означает создание аналога Boost.Graph, а подразумевает хотя бы выполнения пункта 1. Опять таки, Boost.Graph был приведён в качестве доказательства того, что такое разбиение возможно, а отнюдь не как единственный возможный вариант. ЮЛ>Для меня применение "готовых решений" не очень еще и по опыту применения и разработок ActiveX — вещь сильно завязана на автора, пользователь ограничен в возможностях расширения (автор сам решает, что можно, что нельзя).
Опять двадцать пять. Прийдётся даже скопировать: Boost.Graph был приведён в качестве доказательства того, что такое разбиение возможно.
ЮЛ>Это подобно собиранию кода из Лего — какую то игрушку-самолет, даже очень на вид неплохую вы и соберете, но настоящий самолет заведомо из набора Лего не получится. Хотя, для наших хомячков, предпочитающих писать код, не особо размышляя над его алгоритмом, Лего — самый лучший подход.
Настоящий самолёт собирают из готовых деталей, агрегатов. Либо делают новые детали, но уже на готовых станках. Либо создают новые станки, используя уже готовые инструменты.
Ну не выходят авиаконструкторы в поле, для создания каменных молтков голыми руками.
B>>Вот, например, как вы тестировали правильность работы той части, которая ищет компоненты связности? Каждый раз вручную запускали программу, давали разные данные, делали дополнительный debug вывод, вручную проверяли результат? ЮЛ>Я проверял именно те его части, которые вызывали сомнения. Для того и подбирались данные, а тестирование случайных данных я не делаю. Для того есть лучшее решение — тесты у заказчика, которых набралось уже за тысячи.
То есть тесты вы делали только когда уже отдали работу заказчику, на его тестовых данных? А до этого вообще код не запускали?
B>>Да, я говорю про locCurvesPool (стили?) — сложность квадратична от их числа. Обходится действительно элементарно, причём сходу, а не когда выстрелит. ЮЛ>Ну да, можно применить map или set по стилям, но зачем городить огород и усложнять код ненужными обобщениями?
Да нет огорода, а получается проще чем с ручным линейным поиском: