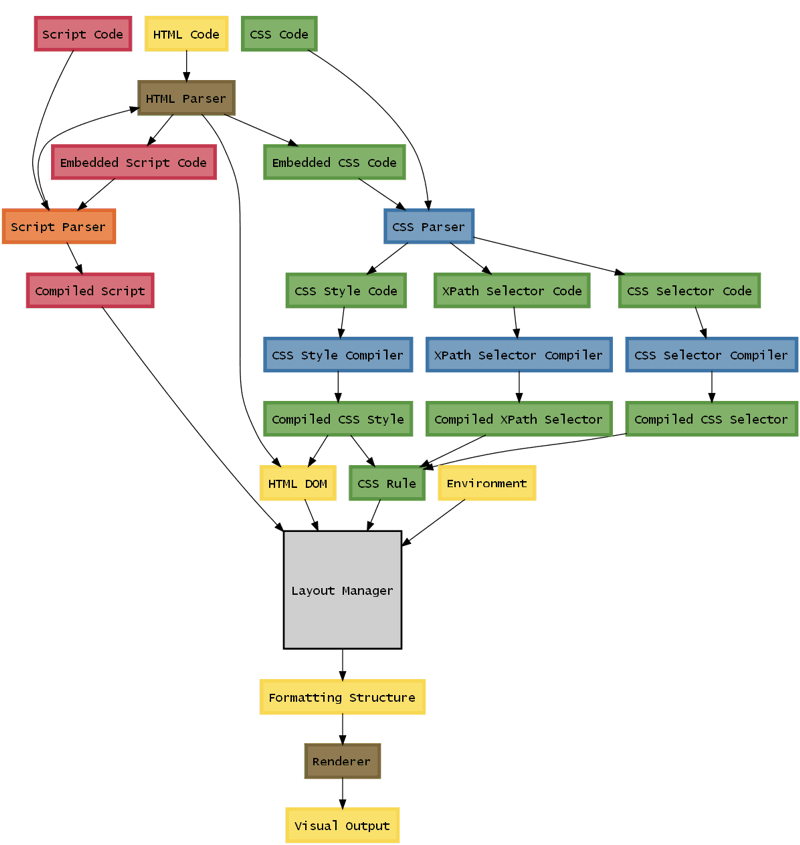
Особенности архитектуры:
DOM основан на XmlElement и может использоваться везде вместо XML, например в XML сериализации (такой план).
CSS поддерживает не только CSS селекторы, но и XPath.
В качестве скриптового движка будет использоваться Jint.
CSS Rule это два скомпилированных на лету DynamicMethod-а. Первый — проверяет условия, второй — модифицирует DOM. В мобильной версии (когда руки дойдут), будет два Jint-метода, если в .Net CF так и не появится компилятор.
Особенности плана работ:
Полезность проекта на любой стадии разработки приоритетна. После третьей стадии проект должен стать конкурентом HtmlAgilityPack.
Потенциальная возможность параллельной разработки зависимых модулей.
MONO поддерживать собираемся.
В данный момент мы заняты тем что:
Настраиваем рабочее окружение. Пока остановили выбор на VS2010 (C#/.Net 4.0), RedMine, Mercurial, xUnit (TestDriven.Net).
Пишем первый набросок парсера HTML, читаем спецификации. Умнеем.
По мере возможности, стандартизируем классы касающиеся HTML DOM и CSS Rules.
Ну и если кто-то ещё захочет участвовать, ничего кроме радости это не вызовет
Здравствуйте, AndrewVK, Вы писали:
A>> DOM основан на XmlElement и может использоваться везде вместо XML, например в XML сериализации (такой план). AVK>Почему не XElement?
А в чём плюсы по сравнению с XmlElement исходя из сценариаев использования?
A>> CSS Rule это два скомпилированных на лету DynamicMethod-а. AVK>Компиляция должна быть опциональной, иначе на ряде сценариев получишь немаленькие тормоза.
Вариант с Jint-скриптом я описал, а без результатов профайлинга оптимизировать нет смысла.
Здравствуйте, AndrewVK, Вы писали:
A>>А в чём плюсы по сравнению с XmlElement исходя из сценариаев использования? AVK>Легче, удобнее, лучше продуман интерфейс.
Это не сценарий использования. Концертация в объекты и обратно XML сериализацией — сценарий, а то что ты описал личное мнение. Я отдаю предпочтение не абстрактной крутости, а удобству интеграции.
Здравствуйте, adontz, Вы писали:
AVK>>Легче, удобнее, лучше продуман интерфейс.
A>Это не сценарий использования.
Естественно не сценарий.
A> Концертация в объекты и обратно XML сериализацией — сценарий, а то что ты описал личное мнение. Я отдаю предпочтение не абстрактной крутости, а удобству интеграции.
Ну вот и поясни тогда, чем XmlElement лучше XElement. На конкретных примерах.
... << RSDN@Home 1.2.0 alpha 4 rev. 1471 on Windows 7 6.1.7600.0>>
Здравствуйте, AndrewVK, Вы писали:
A>> Концертация в объекты и обратно XML сериализацией — сценарий, а то что ты описал личное мнение. Я отдаю предпочтение не абстрактной крутости, а удобству интеграции. AVK>Ну вот и поясни тогда, чем XmlElement лучше XElement. На конкретных примерах.
XmlElement, наследник XmlNode, можно передать в конструктор XmlNodeReader. Следовательно, для конвертации из DOM в дерево типизированных объектов и обратно, из объектов в DOM, можно использовать XmlSerializer. Кроме того, хотя XmlElement и класс, он фактически не содержит непереопределяемых реализаций и не навязывает их.
XElement/XNode напротив содержит много непереопределяемых реализаций. Простая задача, предоставление механизма оповещения об изменении атрибутов, не представляется простой в реализации.
XmlNodeReader — есть XmlReader, реализовать аналогичный, который обходит ту или иную реализацию дерева вообще не проблема.
Если смотреть на XmlDocument vs XDocument и прочие, то XmlDocument безусловно много ближе по своей сути, т.к. он реализует W3C DOM Level 2 Core. Например XmlAttribute есть XmlNode, в то время как XAttribute — нет. За одно это этого в принципе достаточно, что бы к чертям выкинуть XDocument.
Впрочем, лично я пока ни к одному из них не склонился. Работы хватает пока без этого.
Здравствуйте, adontz, Вы писали:
A>XmlElement, наследник XmlNode, можно передать в конструктор XmlNodeReader.
Аналогичный ридер есть и для XElement
A>Кроме того, хотя XmlElement и класс, он фактически не содержит непереопределяемых реализаций и не навязывает их.
XElement намного более легковесен.
A>XElement/XNode напротив содержит много непереопределяемых реализаций.
Ты что то путаешь.
P.S. Написание собственного XmlReader для собственной структуры — совсем несложная задача.
... << RSDN@Home 1.2.0 alpha 4 rev. 1471 on Windows 7 6.1.7600.0>>
Здравствуйте, AndrewVK, Вы писали:
A>>XElement/XNode напротив содержит много непереопределяемых реализаций. AVK>Ты что то путаешь.
XAttribute.Value — зачем далеко ходить.
Здравствуйте, AndrewVK, Вы писали:
F>>Если смотреть на XmlDocument vs XDocument и прочие, то XmlDocument безусловно много ближе по своей сути AVK>Ближе к чему?
К W3C DOM.
F>>, т.к. он реализует W3C DOM Level 2 Core AVK>Который сам по себе — уродство то еще.
Вопрос спорный. Каким бы он не был — его интерфейс является стандартным и должен быть реализован.
F>>Например XmlAttribute есть XmlNode, в то время как XAttribute — нет. AVK>И чем это плохо?
Тем, что аттрибуты в W3C DOM устроены не так.
Здравствуйте, adontz, Вы писали:
A>О, а я даже не обратил внимания. Очень здорово.
Имеет смысл ориентироваться на Level 3 — сходу впишется он или нет — пока что тоже не знаю.
Здравствуйте, AndrewVK, Вы писали:
AVK>P.S. Написание собственного XmlReader для собственной структуры — совсем несложная задача.
Ну, мы для HTML писали свой reader и пользовались своими "совсем легковесными объектами" для формирования структуры. Легковесность еще в том, что известные таги и аттрибуты в этой модели представлены кодами enum — гораздо быстрее идет оперирование. И там действительно ничего сложного, разработка всей модели — 3 дня максимум.
Здравствуйте, vdimas, Вы писали:
V>Легковесность еще в том, что известные таги и аттрибуты в этой модели представлены кодами enum — гораздо быстрее идет оперирование.
Мне как то для одной узкой задачи понадобилось ускорить XML DOM (XElement тогда еще не было). Просто переписывание узлов без каких либо изысков ускорило чтение дерева раз в 20.
... << RSDN@Home 1.2.0 alpha 4 rev. 1471 on Windows 7 6.1.7600.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Мне как то для одной узкой задачи понадобилось ускорить XML DOM (XElement тогда еще не было). Просто переписывание узлов без каких либо изысков ускорило чтение дерева раз в 20.
Да, похожий порядок. Конкретно ускорение чтения не замерял, но общее время, где было чтение + обработка "нашего DOM" HTML, ускорилось 30-50 раз (чем больше страница, тем больше разница).